kubernetes-beginer
Concernant les supports de cours
Supports de cours
Les cours sont maintenus et donnés par : https://www.alterway.fr/cloud-consulting
- Copyright © 2014 - 2025 Alter Way Cloud Consulting
- Licence : Creative Commons BY-SA 4.0
- Sources : https://github.com/alterway/formations/

LABS
Site du labs
Les labs sont içi : https://bit.ly/3XQHbUk

KUBERNETES : Projet, Gouvernance et Communauté
Projet Kubernetes
- Initialement développé par Google, devenu open source en 2014.
- Premier projet hébergé par la CNCF (Cloud Native Computing Foundation).
- Géré via une communauté open source active sur GitHub, Slack, etc.
Gouvernance et Standards
- CNCF : Fondation qui héberge et promeut les technologies cloud natives. Elle définit des standards, favorise l'interopérabilité et incube de nouveaux projets.
- OCI (Open Container Initiative) : Crée des standards ouverts pour les formats de conteneurs et leurs runtimes afin d'assurer portabilité et compatibilité.
Cycle de Développement
- Fréquence : Environ 3 releases majeures par an (cycle trimestriel).
- Versioning :
vX.Y.Z(Majeure, Mineure, Patch). - Support : Les 3 dernières versions mineures sont supportées (environ 9 mois par version).
- Fonctionnalités : Passent par les phases Alpha, Beta, et Stable.
Communauté
- Organisée en SIGs (Special Interest Groups), chacun responsable d'un aspect du projet (ex:
sig-network,sig-storage,sig-security). - KubeCon : Conférences majeures organisées par la CNCF pour rassembler la communauté et partager les nouveautés.
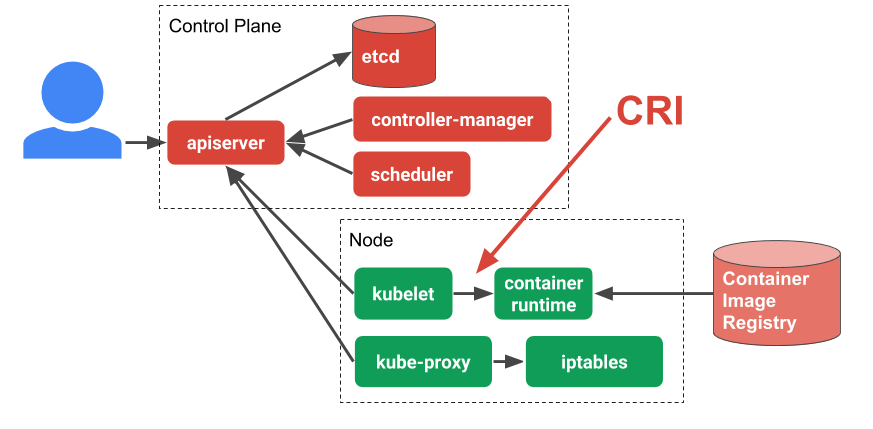
KUBERNETES : Architecture
Kubernetes : Composants
Kubernetes est écrit en Go, compilé statiquement.
Un ensemble de binaires sans dépendances
Faciles à conteneuriser et à packager
Peut se déployer uniquement avec des conteneurs sans dépendance d'OS
k3d, kind, minikube, docker...
Kubernetes : Les noeuds (Nodes)
Les noeuds qui exécutent les conteneurs embarquent :
Un "container Engine" (Docker, CRI-O, containerd...)
Une "kubelet" (node agent)
Un kube-proxy (un composant réseau nécessaire mais pas suffisant)
Ancien nom des noeuds : Minions
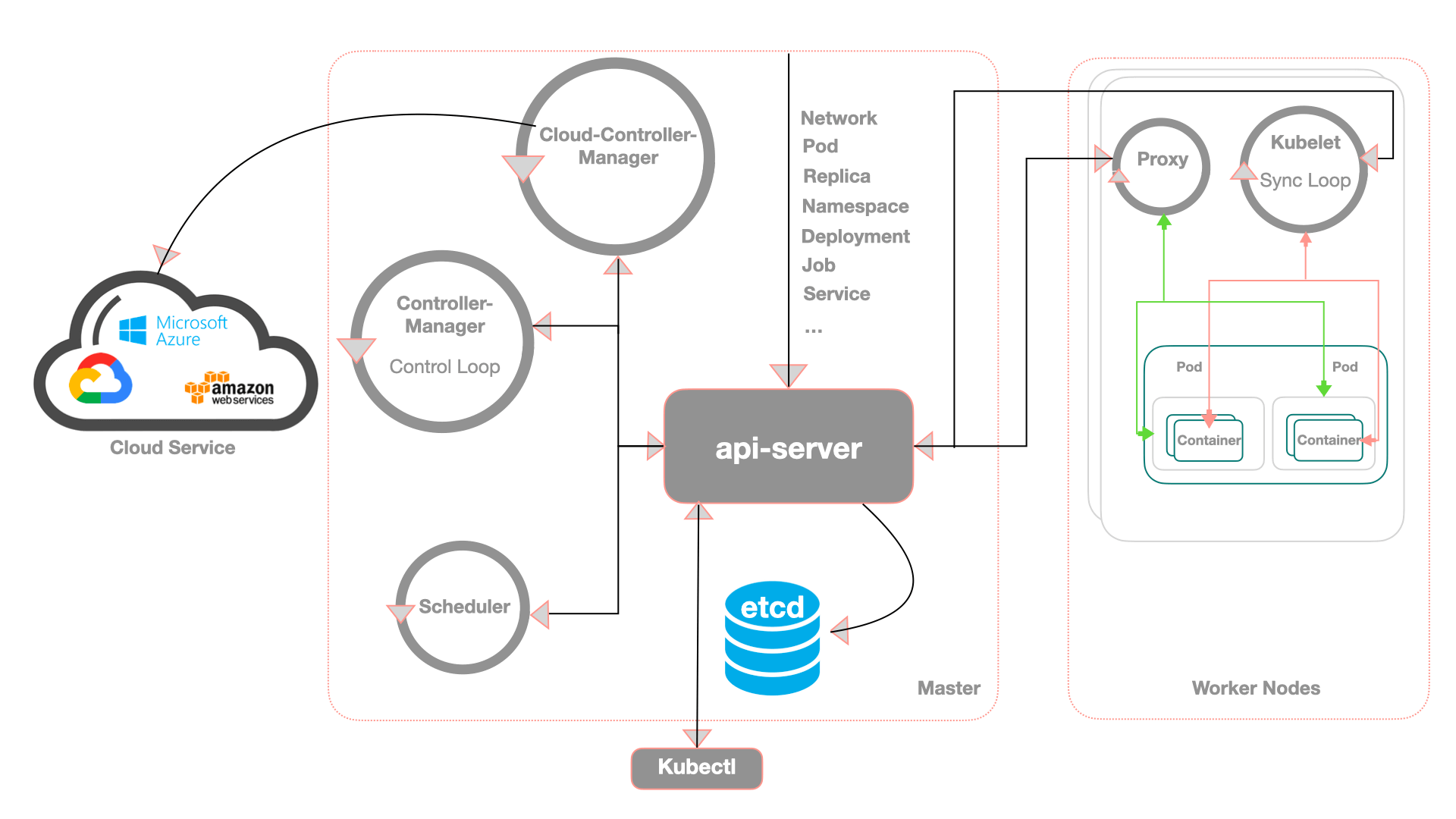
Kubernetes : Architecture
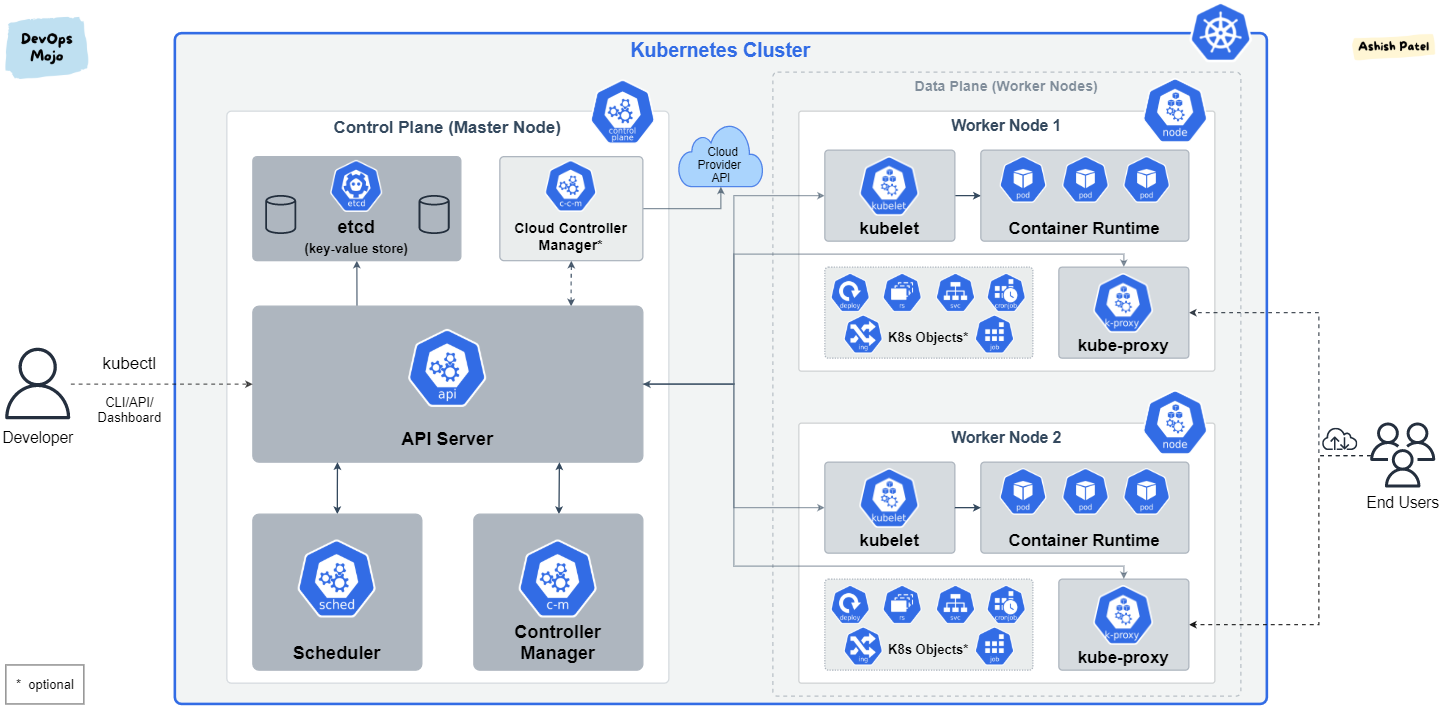
Kubernetes : Composants du Control Plane
etcd: magasin de données clé-valeur open source cohérent et distribuékube-apiserver: L'API Server est un composant qui expose l'API Kubernetes, l'API server qui permet la configuration d'objets Kubernetes (Pod, Service, Deployment, etc.)core services :
kube-scheduler: Implémente les fonctionnalités de schedulingkube-controller-manager: Responsable de l'état du cluster, boucle infinie qui régule l'état du cluster afin d'atteindre un état désirékube-cloud-controller-manager: Est un composant important du plan de contrôle (control plane) de Kubernetes, spécifiquement conçu pour interagir avec l'infrastructure cloud sous-jacentekube-proxy: Permet le forwarding TCP/UDP et le load balancing entre les services et les backends (Pods)
Le control plane est aussi appelé "Master"
Kubernetes : etcd
- Site : https://etcd.io
- Code : https://github.com/etcd-io/etcd
- Base de données de type Clé/Valeur distribuée (Distributed Key Value Store)
- Haute disponibilité: etcd est conçu pour être hautement disponible, même en cas de panne de certains nœuds
- Cohérence forte: etcd garantit que toutes les données sont cohérentes entre tous les nœuds.
- API simple: etcd offre une API simple et facile à utiliser pour interagir avec les données.
- Surveillance: etcd fournit des outils de surveillance pour suivre l'état du cluster.
- Stocke l'état d'un cluster Kubernetes
- Point sensible (stateful) d'un cluster Kubernetes
- Projet intégré à la CNCF (https://github.com/etcd-io)

Kubernetes : kube-apiserver
Sans le kube-apiserver le cluster ne sert à rien. De plus, il est LE SEUL à interagir avec le cluster etcd, que ce soit en écriture ou en lecture.
- Les configurations d'objets (Pods, Service, RC, etc.) se font via l'API server
- Un point d'accès à l'état du cluster aux autres composants via une API REST
- Tous les composants sont reliés à l'API server
- Roles :
- Reçoit les requêtes API faites au cluster
- Authentifie les requêtes
- Valide les requêtes
- Récupère, Met à jour les données dans
etcd - Transmet les réponses aux clients
- Intéragit avec le kube-scheduler, le controller-manager, le kubelet, etc...
- C'est une API donc utilisable via des composants externes (kubectl, curl, lens, ...)
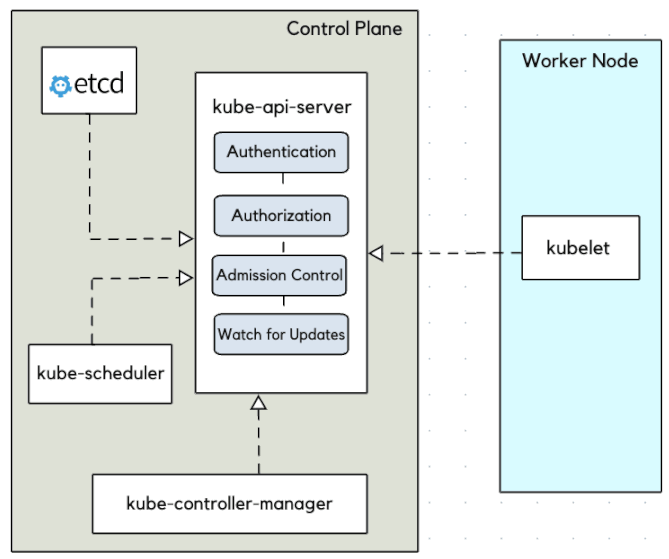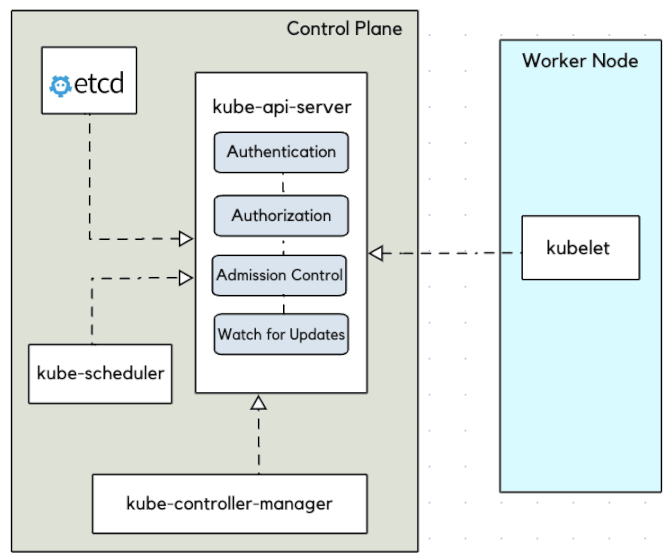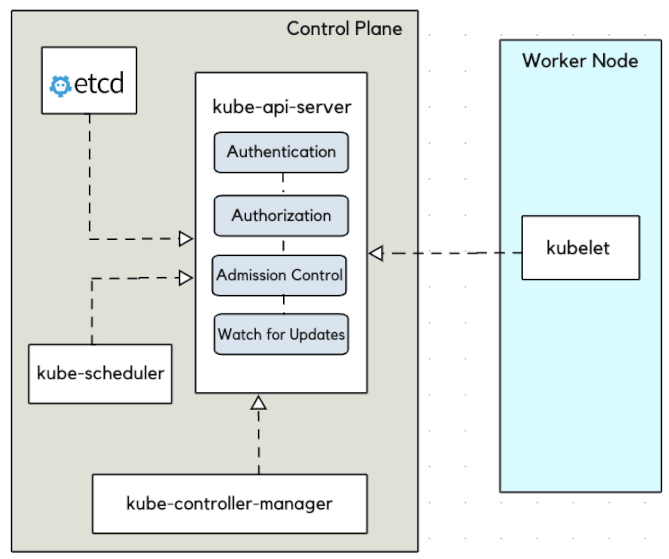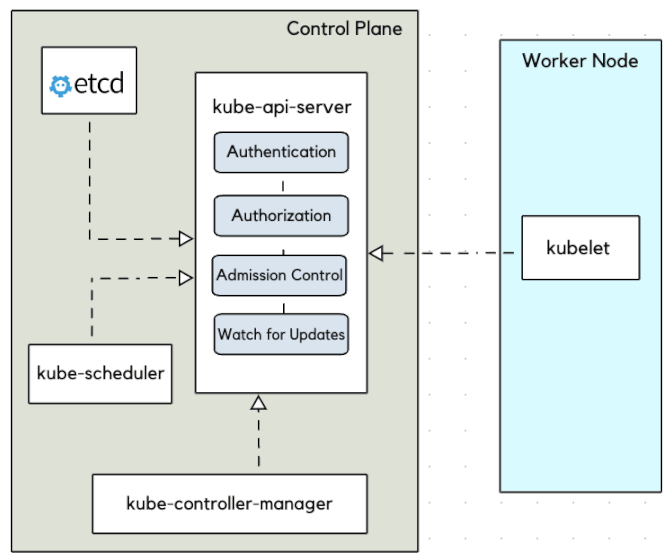
Kubernetes : kube-scheduler
Le kube-scheduler est le composant responsable d'assigner les pods aux nœuds "worker" du cluster. Il choisit alors selon les contraintes qui lui sont imposées un nœud sur lequel les pods peuvent être démarrés et exécutés.
- Planifie les ressources sur le cluster
- En fonction de règles implicites (CPU, RAM, stockage disponible, etc.)
- En fonction de règles explicites (règles d'affinité et anti-affinité, labels, etc.)
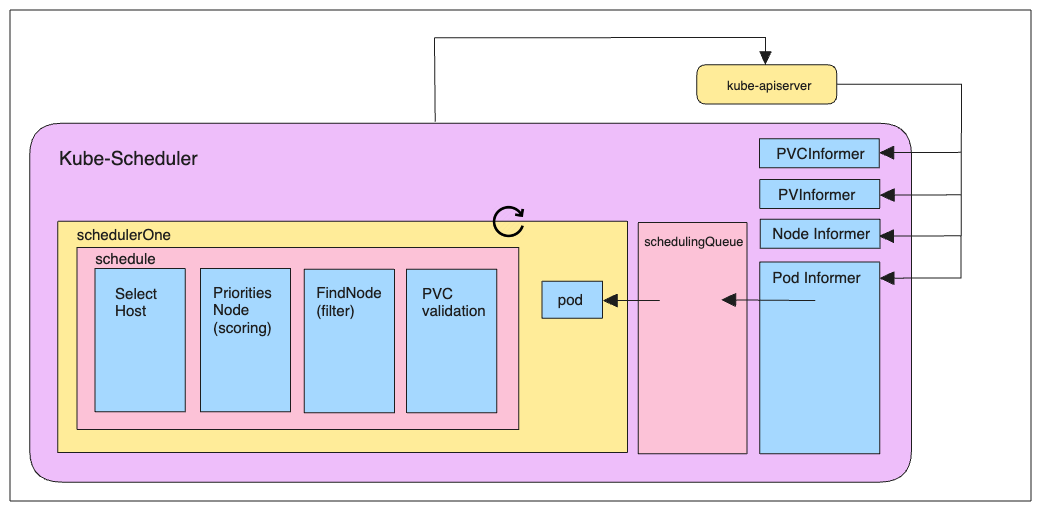
Kubernetes : kube-controller-manager
Le kube-controller-manager exécute et fait tourner les processus de contrôle du cluster.
- Boucle infinie qui contrôle l'état d'un cluster
- Effectue des opérations pour atteindre un état donné
- De base dans Kubernetes : replication controller, endpoints controller, namespace controller et serviceaccounts controller
- Processus de contrôle :
- Node Controller : responsable de la gestion des nœuds du cluster et de leur cycle de vie
- Replication Controller : responsable du maintien du nombre de pods pour chaque objet de réplication dans le cluster
- Endpoints Controller : fait en sorte de joindre correctement les services et les pods
- Service Account & Token Controllers : Gestion des comptes et des tokens d'accès à l'API pour l'accès aux
namespacesKubernetes

Kubernetes : kube-cloud-controller-manager
Fonction principale :
- Le CCM agit comme une interface entre Kubernetes et le fournisseur de cloud spécifique (comme AWS, Google Cloud, Azure, etc.). Il permet à Kubernetes de gérer les ressources spécifiques au cloud de manière indépendante du reste du cluster.
- Séparation des responsabilités :
- Avant l'introduction du CCM, le contrôleur de nœud (node controller), le contrôleur de route (route controller) et le contrôleur de service (service controller) étaient intégrés au contrôleur de gestion Kubernetes (kube-controller-manager). Le CCM a extrait ces fonctionnalités spécifiques au cloud pour les gérer séparément.
- Contrôleurs spécifiques au cloud : Le CCM implémente plusieurs contrôleurs qui interagissent avec l'API du fournisseur de cloud :
- Node Controller : Vérifie si les nœuds ont été supprimés dans le cloud après avoir cessé de répondre.
- Route Controller : Configure les routes dans l'infrastructure cloud pour que les pods sur différents nœuds puissent communiquer.
- Service Controller : Crée, met à jour et supprime les load balancers du cloud.
Kubernetes : kube-proxy
Le kube-proxy maintient les règles réseau sur les nœuds. Ces règles permettent la communication vers les pods depuis l'intérieur ou l'extérieur de votre cluster.
Responsable de la publication de services
Route les paquets à destination des PODs et réalise le load balancing TCP/UDP
3 modes de proxyfication :
Userspace mode
IPtables mode
IPVS (IP Virtual Server) mode
Remarque: Par défaut, Kube-proxy fonctionne sur le port 10249. Vous pouvez utiliser un ensemble d'endpoints exposés par Kube-proxy pour l'interroger et obtenir des informations.
Pour voir quel mode est utilisé :
Sur un des noeuds executer la commande :
curl -v localhost:10249/proxyMode;echo
# ex: retourne iptablesCertains plugins réseaux, tel que Cilium, permettent de ne plus utiliser kube-proxy et de le remplacer par un composant du CNI
Kubernetes : kube-proxy Userspace mode

- Userspace mode est ancien et inefficace.
- Le paquet est comparé aux règles iptables puis transféré au pod kube-Proxy, qui fonctionne comme une application pour transférer le paquet aux pods backend.
- Kube-proxy fonctionne sur chaque nœud en tant que processus dans l'espace utilisateur.
- Il distribue les requêtes entre les pods pour assurer l'équilibrage de charge et intercepte la communication entre les services.
- Malgré sa portabilité et sa simplicité, le surcoût de traitement des paquets dans l'espace utilisateur le rend moins efficace pour les charges de trafic élevées.
Kubernetes : kube-proxy IPtables mode

- Le mode iptables est préférable car il utilise la fonctionnalité iptables du noyau, qui est assez mature.
- kube-proxy gère les règles iptables en fonction du fichier YAML du service de Kubernetes.
- Pour gérer le trafic des services, Kube-proxy configure des règles iptables sur chaque nœud.
- Il achemine les paquets vers les pods pertinents en utilisant du NAT (Network Address Translation) iptables.
- Ce mode fonctionne bien avec des volumes de trafic modestes et est plus efficace que le mode espace utilisateur.
Kubernetes : kube-proxy IPVS mode

IPVS mode équilibre la charge en utilisant la fonctionnalité IPVS du noyau Linux. Par rapport au mode IPtables, il offre une meilleure évolutivité et des performances améliorées.
IPVS est le mode recommandé pour les installations à grande échelle car il peut gérer de plus gros volumes de trafic avec efficacité. IPtable Non !
Kubernetes : Kubelet
Elle, Il, iel ? 😉
- Agent principal du nœud : Kubelet est le principal agent qui s'exécute sur chaque nœud (machine) d'un cluster Kubernetes.
- Gestion des pods : Elle est responsable de la création, de la mise à jour et de la suppression des pods sur ce nœud, en suivant les instructions du plan de contrôle Kubernetes.
- Communication avec l'API Kubernetes : Kubelet communique en permanence avec l'API Kubernetes pour recevoir les mises à jour de configuration et les commandes.
- Exécution des conteneurs : Il utilise un runtime de conteneur (comme Docker ou containerd) pour lancer et gérer les conteneurs à l'intérieur des pods.
- Permet à Kubernetes de s'auto configurer :
- Surveille un dossier contenant les manifests (fichiers YAML des différents composant de Kubernetes).
- Applique les modifications si besoin (upgrade, rollback).
- Surveillance de l'état des pods : Kubelet surveille en permanence l'état des pods et des conteneurs, et signale tout problème au plan de contrôle.
- Gestion des ressources : Il gère l'allocation des ressources (CPU, mémoire) aux pods et assure que les limites de ressources ne sont pas dépassées.
- Intégration avec le système d'exploitation : Kubelet s'intègre avec le système d'exploitation hôte pour gérer les réseaux, les volumes et autres fonctionnalités du système.
Kubernetes : Architecture détaillée
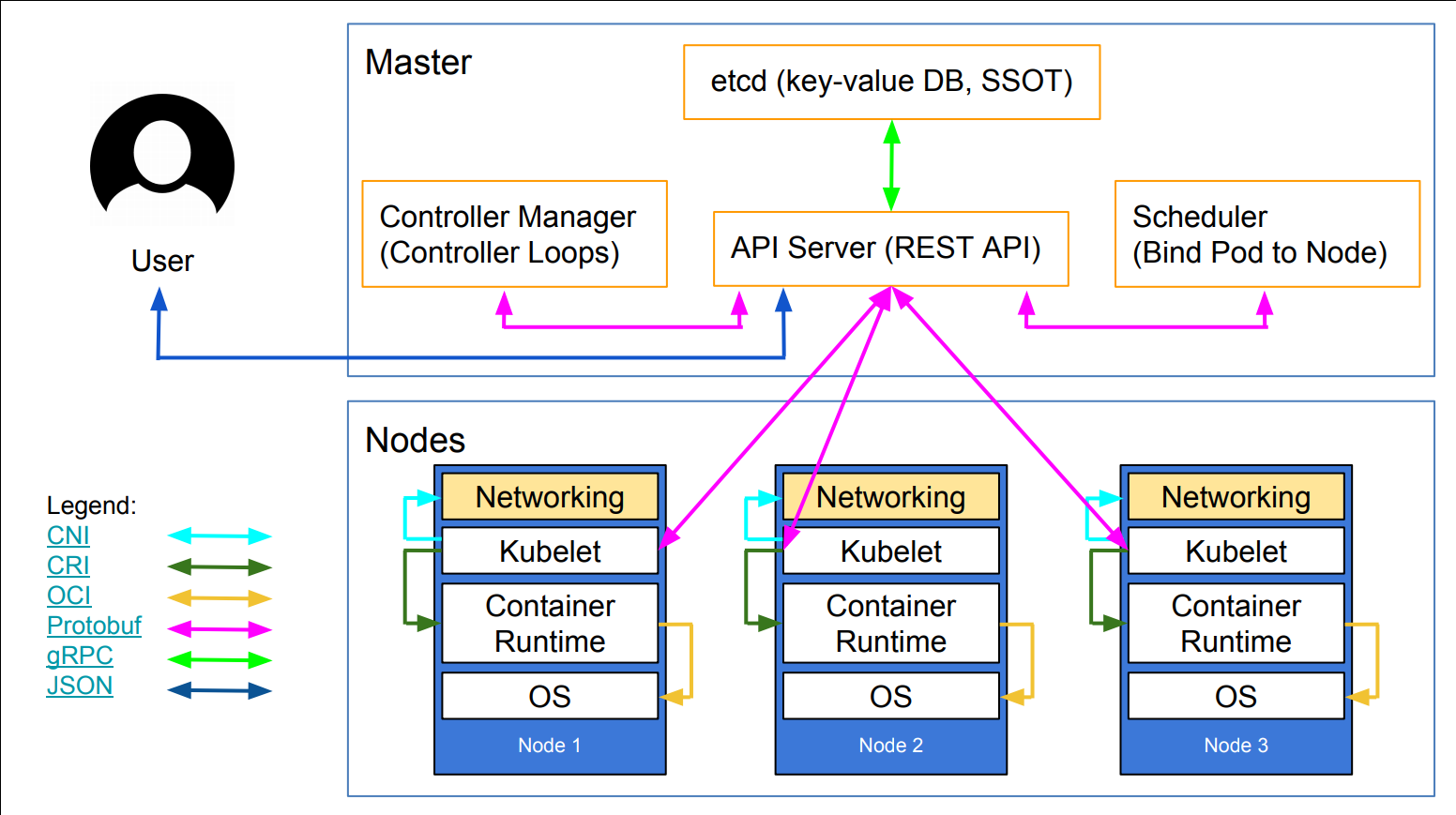
Kubernetes : Cluster Architecture
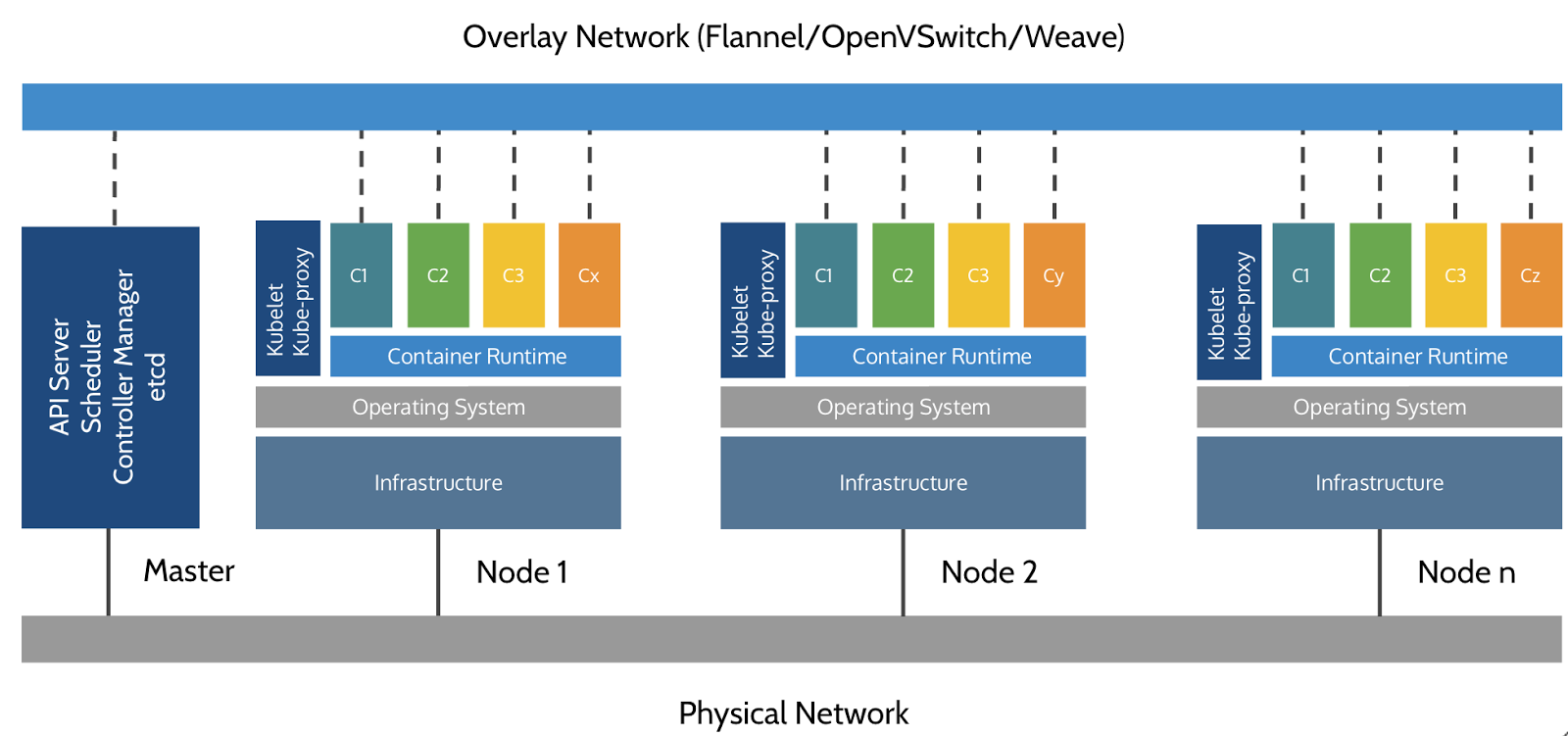
Kubernetes: Network
Kubernetes n'implémente pas de solution réseau par défaut, mais s'appuie sur des solutions tierces qui implémentent les fonctionnalités suivantes:
- Chaque pods reçoit sa propre adresse IP
- Tous les nœuds doivent pouvoir se joindre, sans NAT
- Les pods peuvent communiquer directement sans NAT
- Les pods et les nœuds doivent pouvoir se rejoindre, sans NAT
- Chaque pod est conscient de son adresse IP (pas de NAT)
- Kubernetes n'impose aucune implémentation particulière
- Quelques exemple d'implémentations :
- Calico : https://projectcalico.docs.tigera.io/about/about-calico/
- Cilium : https://github.com/cilium/cilium
- Flannel : https://github.com/flannel-io/flannel#flannel
- Multus : Un Multi Network plugin permet d'avoir des pods avec plusieurs interfaces
- Weave Net : https://www.weave.works/oss/net/
- Voir les autres : https://kubernetes.io/docs/concepts/cluster-administration/networking/
Kubernetes : Aujourd'hui
Les versions de Kubernetes sont exprimées sous la forme x.y.z, où x est la version majeure, y est la version mineure et z est la version du correctif, conformément à la terminologie du Semantic Versioning.
- Version 1.35.x : stable en production
- Solution complète
- Éprouvée par Google
- https://kubernetes.io/releases/
1.35
Latest Release:1.35.0 (released: 2025-12-17)
End of Life:2027-02-28
Complete 1.35 Schedule and Changelog
KUBERNETES : Installation
Kubernetes Local : Poste Personnel
| Solution | Description | Avantages | Inconvénients |
|---|---|---|---|
| Minikube | Outil officiel pour installer un cluster Kubernetes local sur une machine. | - Facile à installer et à configurer - Compatible avec la majorité des environnements - Supporte divers hyperviseurs et conteneurs |
- Peut être lourd en ressources - Nécessite une VM pour fonctionner |
| Kind | Kubernetes IN Docker (KinD) utilise Docker pour exécuter des clusters. | - Léger et rapide - Simple à configurer - Idéal pour les tests CI/CD |
- Moins de fonctionnalités avancées - Dépend de Docker |
| MicroK8s | Distribution légère de Kubernetes par Canonical. | - Facile à installer - Léger et optimisé - Idéal pour les environnements de développement |
- Moins de flexibilité dans la configuration - Utilise des snaps (peut ne pas plaire à tout le monde) |
| K3s | Distribution allégée de Kubernetes par Rancher. | - Très léger et rapide - Idéal pour les environnements IoT et edge - Moins de ressources requises |
- Moins de fonctionnalités intégrées - Moins documenté que Minikube |
| Docker Desktop | Inclut une option pour exécuter Kubernetes directement. | - Facile à utiliser pour les développeurs habitués à Docker - Intégration transparente avec Docker |
- Peut être lourd en ressources - Moins flexible que Minikube ou Kind |
| Rancher Desktop | - Open Source, - Choix des version de k8s - Choix du CRI |
- Facile à utiliser | - Moins d'extensions que Minikube |
Kubernetes Local : Minikube
Installation : https://minikube.sigs.k8s.io/docs/start
- Créer un cluster
- minikube start
- Les cluster sont ajoutés automatiquement au fichier ~/.kube/config de votre poste de travail
Les cluster sont supprimés automatiquement au fichier ~/.kube/config avec la commande
minikube delete [--all]- Supporte de nombreux drivers
- (HyperKit, Hyper-V, KVM, VirtualBox, but also Docker and many others)
- Beaucoup de plugins (addons)
minikube addons list
Kubernetes Local : k3s
Pré-requis : - Linux - Raspberry
- Installation : https://docs.k3s.io/installation
ou plus simplement : curl -sfL https://get.k3s.io | sh -
- K3s est conçu pour être très léger, nécessitant seulement environ 512 Mo de RAM pour fonctionner. Cela le rend idéal pour les environnements avec des ressources limitées.
Kubernetes Local : kind
- Kubernetes-in-Docker
- Il faut un serveur docker
- Fonctionne aussi avec podman
- Créer un cluster
kind create cluster
- Possibilité de créer plusieurs clusters
- Possibilité de créer des clusters de plusieurs noeuds (avec un fichier de config yaml)
Kubernetes Local : Docker Desktop
Installation : https://www.docker.com/products/docker-desktop/
Licence obligatoire si autre utilisation que personnelle (https://www.docker.com/pricing/)

Kubernetes Local : Rancher Desktop
- Installation : https://rancherdesktop.io/
- Configuration Simple
- Port-Forwarding simple
- Build et Run de container (nerdctl ou Docker CLI)
- Choix des version de kubernetes
Kubernetes Local : Podman Desktop
- Installation : https://podman-desktop.io/
- Docker ou Kubernetes au choix
- docker-compose (podman compose) doisponible
- Configuration simple
- Utilisation de contextes multiples
- Création de clusters kubernetes locaux avec kind
Installation de Kubernetes
- De nombreuses ressources présentes pour le déploiement de Kubernetes dans un environnement de production
Kubeadm est un outil qui facilite le déploiement de Kubernetes en automatisant les tâches d'initialisation et de configuration d'un cluster.
Installation de Kubernetes avec kubeadm
- Certains pré-requis sont nécessaires avant d'installer Kubernetes :
- Désactiver le
swap(Support alpha depuis la 1.22) - Assurer que les ports requis soient ouverts : https://kubernetes.io/docs/setup/independent/install-kubeadm/#check-required-ports
- Installer une Container Runtime compatible CRI (containerd, CRI-O, Docker, ...)
- Désactiver le
kubeadm
- Installer les composants Kubernetes (kubeadm, kubectl, kubelet) : https://kubernetes.io/docs/setup/independent/install-kubeadm/
- Exécuter :
kubeadm initsur le noeudmaster(control plane)kubeadm joinsur les autres noeuds (worker) (avec le token fournit par la commandekubeadm init)
- Copier le fichier de configuration généré par
kubeadm init - Installer le plugin Réseau
- Optionnellement: Tester le déploiement d'un pod
kubeadm demo
kubeadm fonctionnalités
En plus de l'installation de Kubernetes,
kubeadmpeut :Génération des fichiers de configuration: Crée les fichiers de configuration nécessaires pour les composants du cluster.
Gestion des certificats: Génère et distribue les certificats nécessaires pour sécuriser les communications entre les composants du cluster.
Gestion des tokens: Crée des tokens d'authentification pour les nœuds qui rejoignent le cluster.
Vérification de la configuration: Valide que le système et les configurations sont compatibles avec Kubernetes.
Mises à jour et modifications: Facilite les mises à jour des versions de Kubernetes et les modifications de la configuration du cluster.
Kubernetes managés "as a Service" Majeurs
- Plateformes Cloud Majeures :
- Amazon Elastic Kubernetes Service (EKS):
- Documentation : https://aws.amazon.com/fr/eks/
- Offre une solution entièrement gérée pour déployer, gérer et mettre à l'échelle des clusters Kubernetes sur AWS.
- Google Kubernetes Engine (GKE):
- Documentation : https://cloud.google.com/kubernetes-engine
- Propose une plateforme hautement disponible et entièrement gérée pour exécuter des applications conteneurisées sur Google Cloud Platform.
- Azure Kubernetes Service (AKS):
- Documentation : https://azure.microsoft.com/fr-fr/services/kubernetes-service/
- Permet de déployer et gérer des clusters Kubernetes sur Azure avec une intégration profonde avec les autres services Azure.
- Amazon Elastic Kubernetes Service (EKS):
Kubernetes managés "as a Service" Populaires
- Autres Plateformes Populaires :
- DigitalOcean Kubernetes:
- Documentation : https://www.digitalocean.com/products/kubernetes/
- Offre une solution simple et abordable pour déployer des clusters Kubernetes sur DigitalOcean.
- Rancher Kubernetes Engine (RKE):
- Documentation : https://rancher.com/docs/rke/latest/en/
- Solution open-source pour gérer des clusters Kubernetes multi-cloud et sur site.
- Platform9 Managed Kubernetes:
- Documentation : https://platform9.com/docs/
- Plateforme de gestion de Kubernetes hybride et multi-cloud.
- Red Hat OpenShift:
- Documentation : https://www.openshift.com/
- Plateforme containerisée complète basée sur Kubernetes, offrant une large gamme de fonctionnalités pour les entreprises.
- Scaleway Kapsule :
- Documentation : https://www.scaleway.com/fr/kubernetes-kapsule/
- Alibaba Container Service for Kubernetes (ACK)
- Documentation : https://www.alibabacloud.com/fr/product/kubernetes
- DigitalOcean Kubernetes:
Autres Installateurs de Kubernetes
Via Ansible :
kubesprayhttps://github.com/kubernetes-sigs/kubesprayVia Terraform : https://github.com/poseidon/typhoon
- Il existe d'autres projets open source basés sur le langage Go :
- kube-aws : https://github.com/kubernetes-incubator/kube-aws
- kops : https://github.com/kubernetes/kops
- rancher : https://rancher.com/docs/rancher/v2.5/en/
- tanzu : https://github.com/vmware-tanzu
- clusterAPI : https://cluster-api.sigs.k8s.io/
Conformité kubernetes
Voici quelques outils permettant de certifier les déploiements des cluster kubernetes en terme de sécurité et de respects des standards
- Sonobuoy
- Popeye
- kube-score
- kube-bench
- Kube-hunter:
KUBERNETES : Utilisation et Déploiement des Ressources
Kubernetes : kubectl

- Le seul (ou presque) outil pour interagir avec des clusters Kubernetes
- Utilise un ou plusieurs fichier(s) de configuration (kubeconfig) pour communiquer avec l'API de Kubernetes
Le(s) fichier(s) se trouve(nt) par défaut dans le répertoire
~/.kube/config- Le fichier de configuration contient des informations essentielles pour se connecter au cluster, notamment :
- L'adresse(URI) de l'APIServer
- Les chemins des certificats TLS utilisés pour l'authentification
- Le contexte actuel (cluster, utilisateur, namespace) pour cibler un environnement spécifique.
- Des informations d'identification (jetons, mots de passe) pour l'authentification.
- Fichier
kubeconfigpeut être passé en paramètre de kubectl avec le flag--kubeconfig- ex:
kubectl --kubeconfig=/opt/k8s/config get po
- ex:
- Fichier
kubeconfigpeut être passé en paramètre de kubectl avec la variable d'nvironnementKUBECONFIG- ex:
KUBECONFIG=/opt/k8s/config kubectl get pods
- ex:
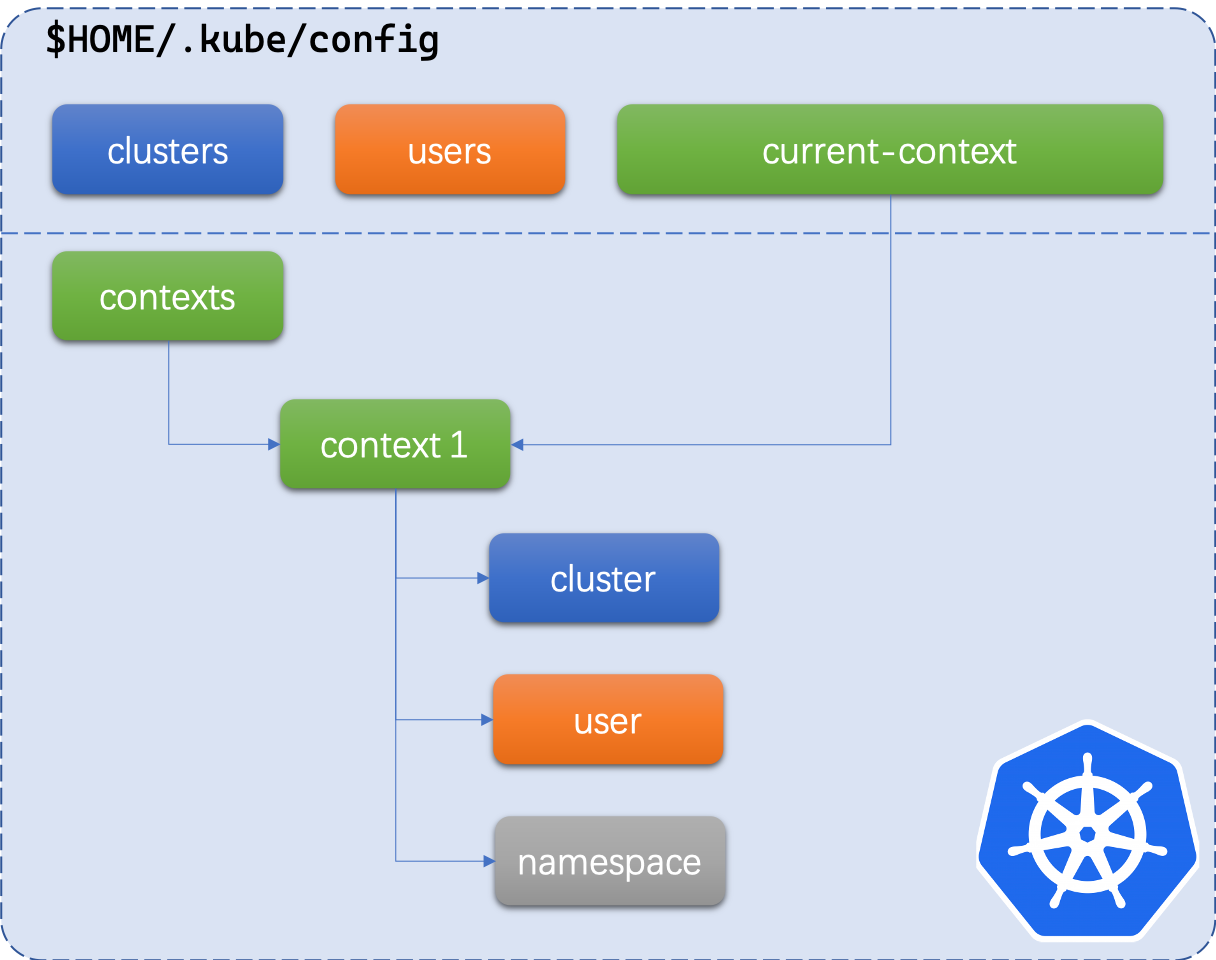
Kubeconfig 1/4
Un seul fichier pour gérer tous les clusters avec trois informations :
- Serveurs (IP, CA Cert, Nom)
- Users (Nom, Certificat, Clé)
- Context, association d'un user et d'un serveur
Kubeconfig 2/4
Kubeconfig 3/4
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FU..
server: https://akshlprod001-e419e3f0.hcp.northeurope.azmk8s.io:443
name: aks-hl-prod-001
contexts:
- context:
cluster: aks-hl-prod-001
namespace: velero
user: clusterUser_rg-hl-prod-001_aks-hl-prod-001
name: aks-hl-prod-001
current-context: aks-hl-prod-001
kind: Config
preferences: {}
users:
- name: clusterUser_rg-hl-prod-001_aks-hl-prod-001
user:
client-certificate-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0t..
client-key-data: LS0tLS1CRUdJTiBSU0Eg..
token: 0ad033b165e2f7a4f705ca6defef8555ff501345e2324cf337b68820d85dc65bae39c47bb58ad913b0385a0d7eb5df6e872dbd1fe62fd34ca6e4ed58b2e8a733Kubeconfig 3/4
Lorsque vous accédez à plusieurs clusters Kubernetes, vous aurez de nombreux fichiers kubeconfig.
Par défaut, kubectl recherche uniquement un fichier nommé config dans le répertoire $HOME/.kube.
Alors, comment pouvons-nous fusionner plusieurs fichiers kubeconfig en un seul ?
- Faire une copie de votre fichier kubeconfig (au cas ou 😱...)
cp ~/.kube/config ~/.kube/config-backup - Définir la variable d'environnement KUBECONFIG
La variable d'environnement KUBECONFIG est une liste de chemins vers des fichiers de configuration, par exemple :
export KUBECONFIG=~/.kube/config:/path/cluster1/config:/path/cluster2/config:/path/cluster3/config- Fusionner tous les fichiers kubeconfig en un seul
kubectl config view --flatten > all-in-one-kubeconfig.yaml- Remplacer l'ancien fichier de configuration par le nouveau fusionné
mv all-in-one-kubeconfig.yaml ~/.kube/config- Tester !
kubectl config get-contextsKubernetes : Kubectl

Kubernetes : kubectl api-resources
- Afficher la liste des ressources API supportées par le serveur:
$ kubectl api-resources
NAME SHORTNAMES APIGROUP NAMESPACED KIND
configmaps cm true ConfigMap
limitranges limits true LimitRange
namespaces ns false Namespace
nodes no false Node
persistentvolumeclaims pvc true PersistentVolumeClaim
persistentvolumes pv false PersistentVolume
pods po true Pod
secrets true Secret
services svc true Service
daemonsets ds apps true DaemonSet
deployments deploy apps true Deployment
replicasets rs apps true ReplicaSet
statefulsets sts apps true StatefulSet
horizontalpodautoscalers hpa autoscaling true HorizontalPodAutoscaler
cronjobs cj batch true CronJob
jobs batch true Job
ingresses ing extensions true Ingress- Pourquoi utiliser
kubectl api-resources?- Découverte: Pour connaître les ressources disponibles dans votre cluster.
- Documentation: Pour obtenir des informations sur les différentes ressources et leurs propriétés.
- Développement: Pour créer des scripts et des outils d'automatisation.
- Dépannage: Pour identifier les problèmes liés à des ressources spécifiques.
Kubernetes : kubectl explain
- Le "man pages" de kubernetes
- Explorer les types et définitions
kubectl explain type- Expliquer la définition d'un champs de ressource, ex:
kubectl explain node.spec- Boucler sur les définitions
kubectl explain node --recursiveKubernetes : Kind
Les noms de ressources les plus courants ont 3 formes:
- singulier (par exemple, node, service, deployment)
- pluriel (par exemple, nodes, services, deployments)
- court (par exemple no, svc, deploy)
Certaines ressources n'ont pas de nom court (clusterroles, clusterrolebindings, roles ...)
Les points de terminaison (endpoints) ont uniquement une forme plurielle ou courte (ep)
Kubernetes - Obtenir des informations : kubectl get
Nous allons explorer en détail les différents types de ressources Kubernetes plus tard dans ce cours.
Pour l'instant, concentrons-nous sur l'utilisation de kubectl pour récupérer des informations sur notre cluster.
Voiçi quelques exemples d'utilisation de cette commande très puissante
- Afficher les noeuds du cluster :
kubectl get nodes- Ces commandes sont équivalentes:
kubectl get no
kubectl get nodesKubernetes - Obtenir des informations : kubectl get
- plus d'infos
kubectl get nodes -o wide- Sortie yaml / json
kubectl get nodes -o yaml
kubectl get nodes -o jsonUtiliser JSONPath
- Plus d'infos : https://kubernetes.io/docs/reference/kubectl/jsonpath/
kubectl get pods -o=jsonpath='{@}'
kubectl get pods -o=jsonpath='{.items[0]}'
kubectl get pods \
--output=jsonpath='{.items[0].metadata.name}'Kubernetes - Obtenir des informations : kubectl get
- Utiliser
jq
kubectl get nodes -o json |
jq ".items[] | {name:.metadata.name} + .status.capacity"⚠ : Il faut utiliser jq quand on a besoin de regexp car JSONPath ne les supporte pas.
ex:
# KO :
kubectl get pods -o jsonpath='{.items[?(@.metadata.name=~/^test$/)].metadata.name}'
# OK :
kubectl get pods -o json | jq -r '.items[] | select(.metadata.name | test("test-")).spec.containers[].image'Kubernetes - Obtenir des informations : kubectl get
- Afficher les namespaces
kubectl get ns
kubectl get namespaces- Par défaut, kubectl utilise le namespace
default - Il est possible de sélectionner un namespace avec l'option
-nou--namespace
kubectl -n kube-system get podsKubernetes - Obtenir des informations : kubectl get
- Afficher les pods (pour le namespace default)
kubectl get pods
kubectl get podKubernetes - Obtenir des informations : kubectl get
- Afficher les services (pour le namespace
default):
kubectl get services
kubectl get svcKubernetes : kubectl get
- Afficher les ressources d'un
namespaceparticulier - Utilisable avec la plupart des commandes
kubectl
kubectl get pods --namespace=kube-system
kubectl get pods -n kube-system
# Mais aussi sur d'autres commandes
kubectl create -n NNN ...
kubectl run -n NNN ...
kubectl delete -n NNN ...
# ...Kubernetes - Obtenir des informations : kubectl get
- Pour lister des ressources dans tous les namespaces :
--all-namespaces - Depuis kubernetes 1.14 on peut utiliser le flag
-Aen raccourci - Il est possible de l'utiliser avec beaucoup de commande kubectl pour manipuler toutes les ressources
kubectl get pods --all-namespaces
# ou
kubectl get pods -A
# autres actions
kubectl delete -A ...
kubectl label -A ...Kubectl : Se déplacer dans un Namespace de manière permanente (comme un cd)
Évite de toujours préciser le flag -n
kubectl get ns
kubectl config set-context --current --namespace <nom-du-namespace>
# ou
alias kubens='kubectl config set-context --current --namespace '
# ex: kubens kube-system Kubernetes : namespace kube-public
kube-public est créé par kubeadm
kubectl get all -n kube-public- Le configMap contient les informations données par la commande
kubectl cluster-info
kubectl -n kube-public get configmaps
# voir le contenu du configmap (cm)
kubectl -n kube-public get configmap cluster-info -o yaml
# Ce configmap est lisible par tout le monde sans authentification
curl -k https://{NodeIP}/api/v1/namespaces/kube-public/configmaps/cluster-info
# Contient le kubeconfigCe configmap contient l'url de l'API du serveur, et la clé publique de l'AC
Ce fichier ne contient pas de clés client ni de tokens
Il ne s'agit pas d'informations sensibles
Kubernetes : kubeconfig
- Extraire le kubeconfig du configmap
cluster-info
curl -sk https://<IP PRIV>/api/v1/namespaces/kube-public/configmaps/cluster-info \
| jq -r .data.kubeconfigKubernetes : namespace kube-node-lease
Qu'est-ce qu'un Lease dans Kubernetes ? Un Lease est un objet qui expire après un certain temps s'il n'est pas renouvelé. Dans le contexte de kube-node-lease, chaque nœud du cluster a un Lease associé. La kubelet (l'agent Kubernetes s'exécutant sur chaque nœud) envoie régulièrement des mises à jour à ce Lease pour indiquer qu'il est toujours en fonctionnement.
- Ce namespace particulier existe depuis la 1.14
- Il contient un objet
leasepar noeud - Ces
leasespermettent d'implémenter une nouvelle méthode pour vérifier l'état de santé des noeuds - Voir (KEP-0009)[https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/0009-node-heartbeat.md] pour plus d'information
Kubernetes : kubectl describe
kubectl describea besoin d'un type de ressource et optionnellement un nom de ressourceIl est possible de fournir un préfixe de nom de ressource
ex:
kubectl describe node/worker-0
kubectl describe node worker-0Pourquoi utiliser kubectl describe ? :
- Dépannage: Pour comprendre pourquoi un objet ne fonctionne pas comme prévu.
- Audit: Pour vérifier la configuration d'un objet et s'assurer qu'elle correspond à vos attentes.
- Apprentissage: Pour mieux comprendre la structure et le fonctionnement des différents objets Kubernetes.
Kubernetes : Création d'objets Kubernetes

Kubernetes : Création d'objets Kubernetes
Les objets Kubernetes sont créés sous la forme de fichiers JSON ou YAML et envoyés à l'APIServer
Possible d'utiliser la commande
kubectl run, mais limitée auxdeploymentset auxjobsL'utilisation de fichiers YAML permet de les stocker dans un système de contrôle de version comme git, mercurial, etc...
La documentation de référence pour l'API Kubernetes https://kubernetes.io/docs/reference/#api-reference
Kubernetes : Créer un pod en ligne de commande
- Cette commande avant la 1.18 créait un
deployment - Depuis elle démarre un simple
pod
# Création d'un pod en tâche de fond
kubectl run pingu --image=alpine -- ping 127.1# Création d'un pod en intératif
kubectl run -i --tty my-pod --image=debian -- /bin/bash⚠ : Notez le --entre le nom de l'image et la commande à lancer
Kubernetes : Créer un déploiement (par exemple) en ligne de commande
kubectl create deployment...- Depuis kubernetes 1.19, il est possible de préciser une commande au moment du
create
kubectl create deployment pingu --image=alpine -- ping 127.1⚠ : Notez le --entre le nom de l'image et la commande à lancer
Kubernetes : Création d'objets Kubernetes
- Pour créer un object Kubernetes depuis votre fichier
YAML, utilisez la commandekubectl create:
kubectl create -f object.yaml- Il est possible de créer des objets Kubernetes à partir d'une URL :
kubectl create -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook/frontend-deployment.yamlKubernetes : Création d'objets Kubernetes
- Pour les supprimer exécuter simplement :
kubectl delete -f object.yaml- Mettre à jour un objet Kubernetes en écrasant la configuration existante:
kubectl replace -f object.yaml
kubectl apply -f object.yaml⚠ : Il est possible d'utiliser apply pour créer des resources.
Kubernetes : Kubernetes Dashboard
- Interface graphique web pour les clusters Kubernetes
- Permet de gérer les différents objets Kubernetes créés dans le(s) cluster(s).
- Installé par défaut dans minikube
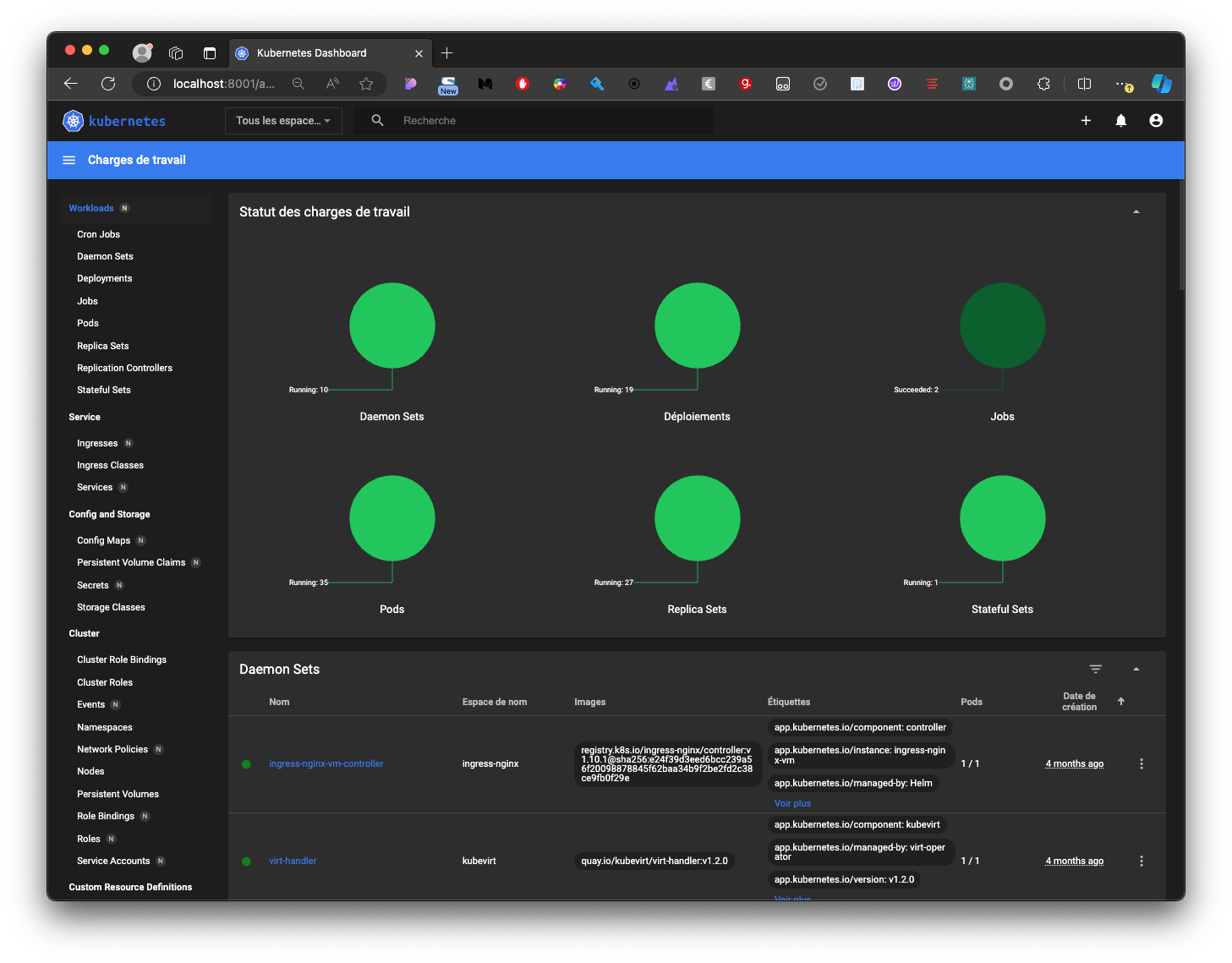
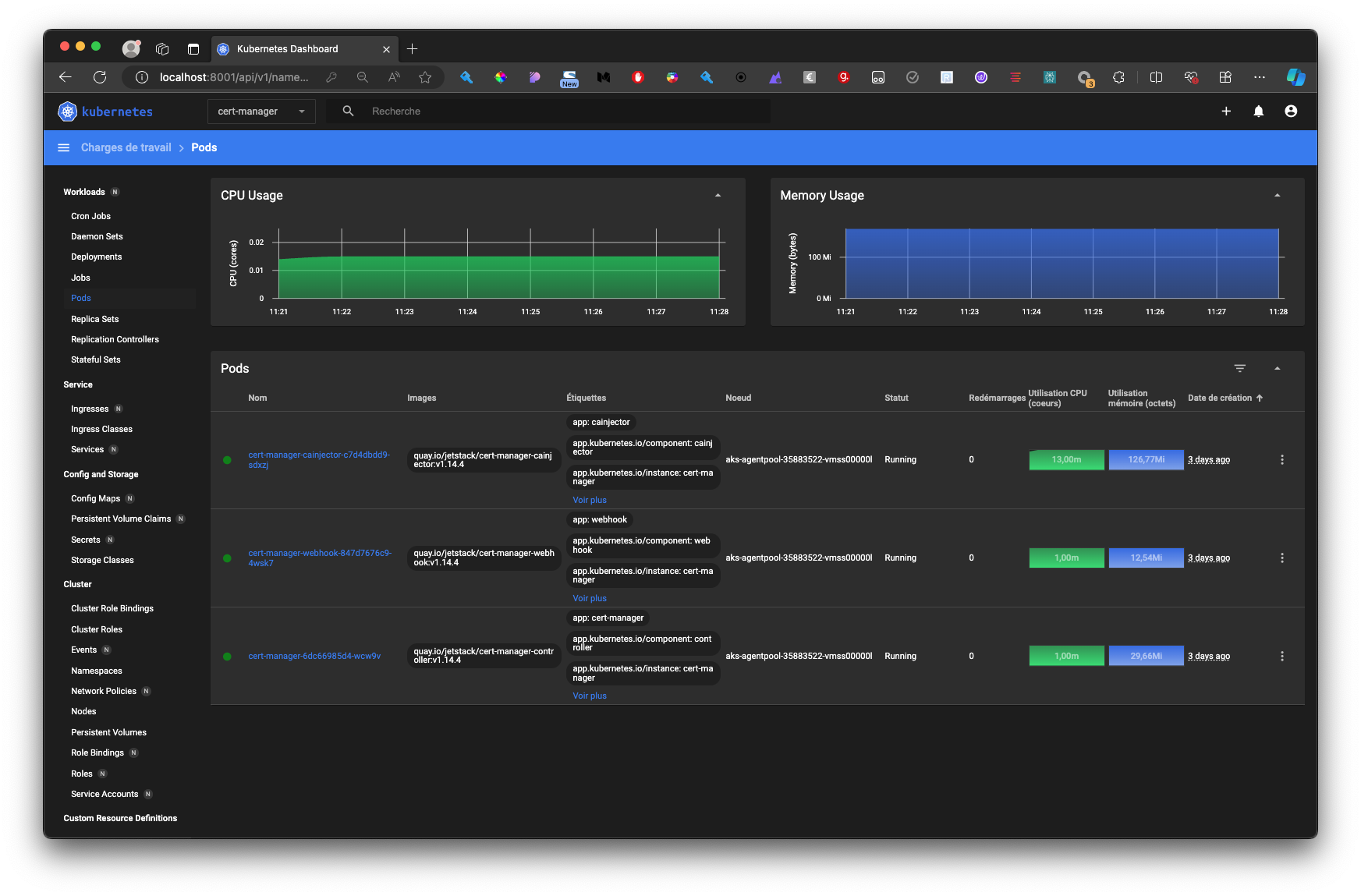
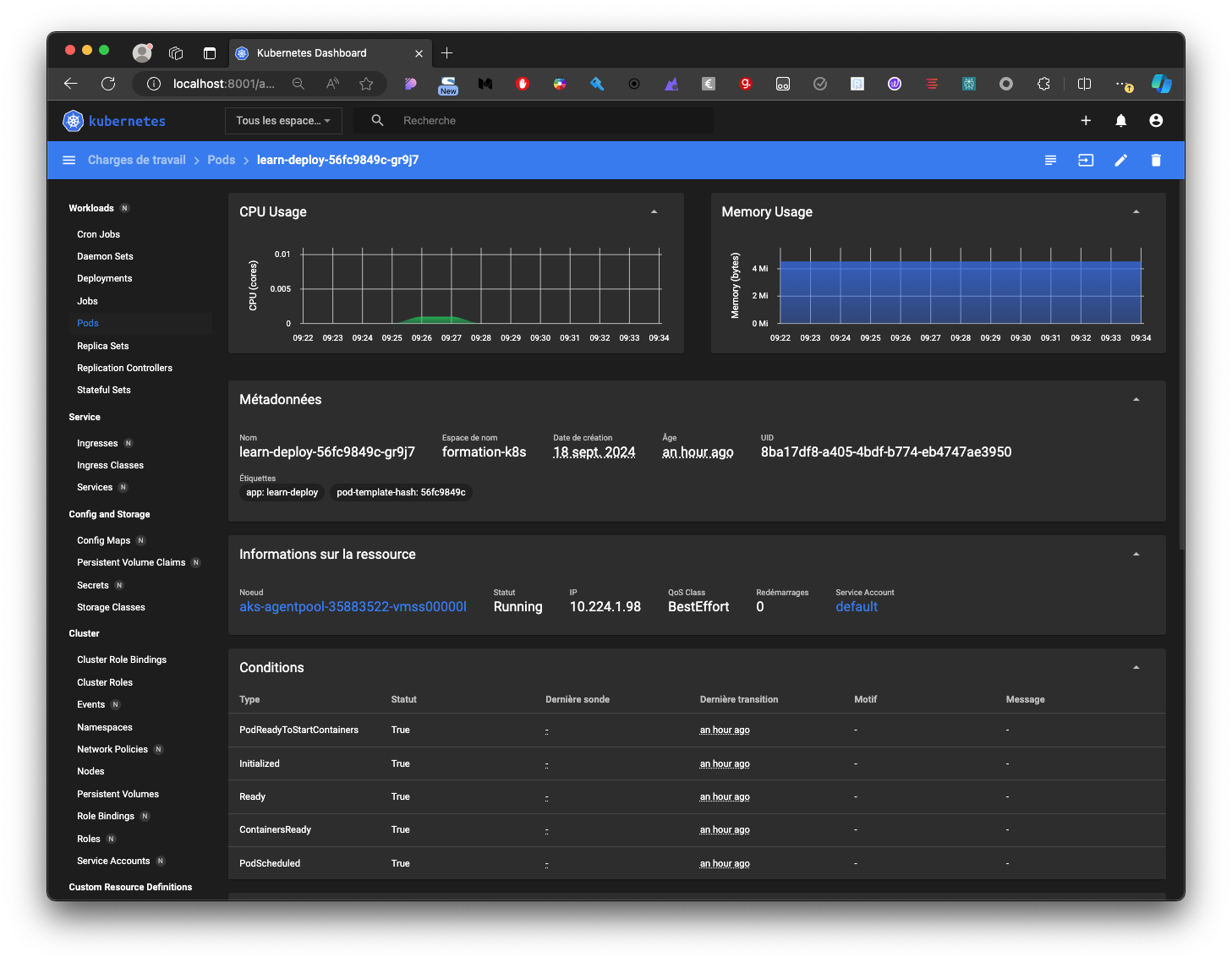
Kubernetes : Kubernetes Dashboard
Kubernetes : Kubernetes Dashboard
Kubernetes : Kubernetes Dashboard
Étape 1: Déployer le Dashboard
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yamlÉtape 2: Créer un compte de service et un rôle d'administration
- Créer un fichier YAML pour le compte de service:
# dashboard-adminuser.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard- Appliquer le fichier YAML pour créer le compte de service:
kubectl apply -f dashboard-adminuser.yamlKubernetes : Kubernetes Dashboard
- Créer un fichier YAML pour le rôle d'administration:
# admin-role-binding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard- Appliquer le fichier YAML pour créer le rôle d'administration:
kubectl apply -f admin-role-binding.yamlKubernetes : Kubernetes Dashboard
Étape 3: Récupérer le token d'accès
kubectl -n kubernetes-dashboard create token admin-userCopiez le token affiché et sauvegardez le.
Kubernetes : Kubernetes Dashboard
Étape 4: Accéder au Dashboard
Si vous êtes sur votre PC (installation locale de kubernetes)
Démarrer un proxy pour accéder au Dashboard:
kubectl proxy- Cela démarre un proxy à l'adresse http://localhost:8001
- Ouvrir le Dashboard dans votre navigateur:
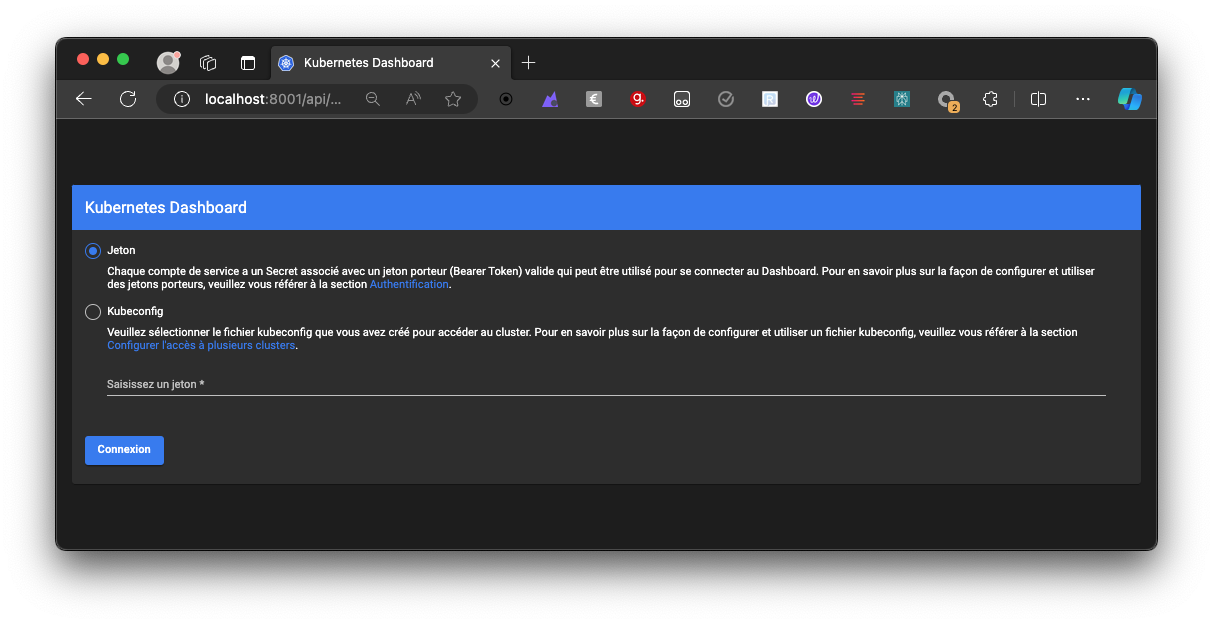
- Accédez à l'URL suivante dans votre navigateur: http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/
- Se connecter avec le token:
- Lorsque vous êtes invité à vous connecter, choisissez l'option "Token" et entrez le token que vous avez récupéré à l'Étape 3.
Kubernetes : Kubernetes Dashboard
Si vos machines sont déployées sur un Cloud Provider (AWS, Azure, GCP, etc)
- Sur le
master
kubectl -n kubernetes-dashboard port-forward svc/kubernetes-dashboard 8443:443 --address=0.0.0.0Dans votre navigateur utilisez l'url suivante en l'adaptant avec l'adresse IP publique du master
https://[IP-PUBLIQUE-MASTER]:8443/
Acceptez l'alerte de sécurité concernant le certificate
- Se connecter avec le token:
- Lorsque vous êtes invité à vous connecter, choisissez l'option "Token" et entrez le token que vous avez récupéré à l'Étape 3.
Kubernetes : Kubernetes Dashboard
Kubernetes : Kubernetes Dashboard
Kubernetes : Kubernetes Dashboard
Kubernetes : Kubernetes Dashboard
Résumé des commandes kubectl
- Lister les ressources :
kubectl get- Utilité : Voir les objets qui tournent sur le cluster.
Exemples :
# Lister les pods dans le namespace actuel kubectl get pods # Lister les nœuds avec plus d'informations kubectl get nodes -o wide # Lister les services dans tous les namespaces kubectl get services -A
- Inspecter une ressource :
kubectl describe- Utilité : Obtenir une vue détaillée et les événements récents d'un objet. Indispensable pour le débogage.
Exemple :
# Voir les détails d'un pod spécifique kubectl describe pod <nom-du-pod>
- Créer ou Mettre à jour :
kubectl apply- Utilité : Appliquer une configuration définie dans un fichier YAML. La commande la plus courante pour déployer.
Exemple :
kubectl apply -f mon-deploiement.yaml
- Supprimer des ressources :
kubectl delete- Utilité : Supprimer les objets créés à partir d'un fichier YAML.
Exemple :
kubectl delete -f mon-deploiement.yaml
Aide et Découverte
- Découvrir les API :
kubectl api-resources- Utilité : Lister tous les types de ressources que vous pouvez créer sur le cluster (ex:
pods,deployments,ingresses...). Exemple :
kubectl api-resources
- Utilité : Lister tous les types de ressources que vous pouvez créer sur le cluster (ex:
- Obtenir de la documentation :
kubectl explain- Utilité : Comprendre la structure et les champs possibles pour un type de ressource, directement dans le terminal.
Exemple :
# Comprendre ce qu'on peut mettre dans la section 'spec' d'un pod kubectl explain pod.spec
KUBERNETES : Concepts et Objets
Kubernetes : Core API Resources
Namespaces
Labels
Annotations
Pods
Deployments
DaemonSets
Jobs
Cronjobs
Services
Kubernetes : Namespaces
Namespaces : Pensez aux différents départements d'une entreprise (par exemple, les ressources humaines, l'ingénierie, le marketing). Chaque département a ses propres ressources (employés, budgets, projets) et fonctionne de manière assez indépendante, mais ils font tous partie de la même entreprise. Vous ne pouvez pas avoir deux projets avec le même nom dans le même département, mais vous le pouvez dans des départements différents.
- Fournissent une séparation logique des ressources :
- Par utilisateurs
- Par projet / applications
- Autres...
- Les objets existent uniquement au sein d'un namespace donné
- Évitent la collision de nom d'objets
- Font partie du fqdn du service (DNS) (mon-service.mon-namespace.svc.cluster.local)
- Quotas et limites: Vous pouvez définir des quotas et des limites sur les ressources (CPU, mémoire, nombre de pods, etc.) au niveau du namespace pour contrôler l'utilisation des ressources.
Défaut: Le namespace
defaultexiste par défaut dans chaque cluster Kubernetes.
Kubernetes : Labels
Labels : Imaginez des étiquettes sur des boîtes dans un entrepôt. Vous pouvez étiqueter les boîtes avec des mentions comme "fragile", "lourd", "électronique" ou par destination comme "Paris". Cela vous aide à trouver et à organiser rapidement toutes les boîtes ayant une caractéristique spécifique. Une boîte peut avoir plusieurs étiquettes.
- Système de clé/valeur
- Organisent, filtrent, selectionnent les différents objets de Kubernetes (Pods, RC, Services, etc.) d'une manière cohérente qui reflète la structure de l'application
- Corrèlent des éléments de Kubernetes : par exemple un service vers des Pods
- Ils contiennent des informations d'identification utilisées par les requêtes qui utilisent un sélecteur ou dans les sections de sélecteurs dans les définitions d'objets
- Le nom dans la clé est limité à 63 caractères et le suffixe à 253 caractères
- La valeur ne peut dépasser 63 caractères
- La valeur doit commencer un aplhanum ou être vide
- La valeur peut contenir des
~.etalphanum - Arbitraires: Vous pouvez définir n'importe quelle paire clé-valeur.
- Immuables: Une fois créés, les labels ne peuvent pas être modifiés directement. Pour les changer, il faut créer un nouveau déploiement ou un nouveau pod.
Multiples: Un objet peut avoir plusieurs labels.
Kubernetes : Labels
- Exemple de label :
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
env: prod
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80Kubernetes : Labels
La commande
kubectl get pods, par défaut, ne liste pas les labels.Il est possible de les voir en utilisant
--show-labels:
$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 31s app=nginx,env=prod- Lister des ressources par l'utilisation de labels
kubectl get po -A -l k8s-app=kube-dns
# ou
kubectl get pods --selector=k8s-app=dns
kubectl get po -A -l k8s-app=kube-dns -l pod-template-hash=6d4b75cb6d
# equivalent
kubectl get po -A -l k8s-app=kube-dns,pod-template-hash=6d4b75cb6d
# ou
kubectl get po -A --selector=8s-app=kube-dns,pod-template-hash=6d4b75cb6d
# Lister les valeurs d'un label
kubectl get pods -L k8s-app
# Lister to les labels d'un object
kubectl get deploy --show-labels
kubectl get deploy,po --show-labels
# Utiliser la forme négative
kubectl get po -A -l k8s-app!=kube-dnsKubernetes : Annotations
Annotations : C'est comme un commentaire ou une note sur un document. Il fournit des informations supplémentaires pour les humains ou d'autres outils (comme le nom de l'auteur, la date de la dernière révision ou un lien vers une documentation externe), mais il ne change pas la manière dont le document est traité par le système principal.
- Système de clé/valeur
- Ce sont des informations qui ne sont pas utilisées pour l'identification de ressources.
- Les annotations ne sont pas utilisées en interne par kubernetes
- Stockage de données personnalisées: Pour stocker des informations spécifiques à votre application ou à votre infrastructure.
- Elles peuvent être utilisées par des outils externes ou librairies (ex: cert-manager, ingress-controller...)
- Le nom dans la clé est limitée à 63 caractères et le suffixe à 253 caractères
- Arbitraires: Vous pouvez définir n'importe quelle paire clé-valeur.
- Mutables: Les annotations peuvent être modifiées après la création de l'objet.
Multiples: Un objet peut avoir plusieurs annotations.
Kubernetes : Annotations
- exemple d'annotation
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: test-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
cert-manager.io/cluster-issuer: theClusterIssuer
spec:
rules:
- http:
paths:
- path: /testpath
pathType: Prefix
backend:
service:
name: test
port:Kubernetes : Pod
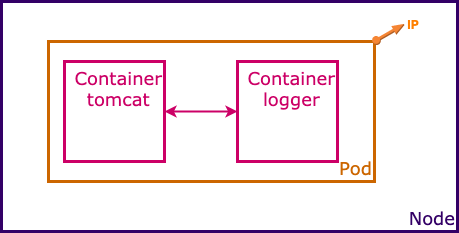
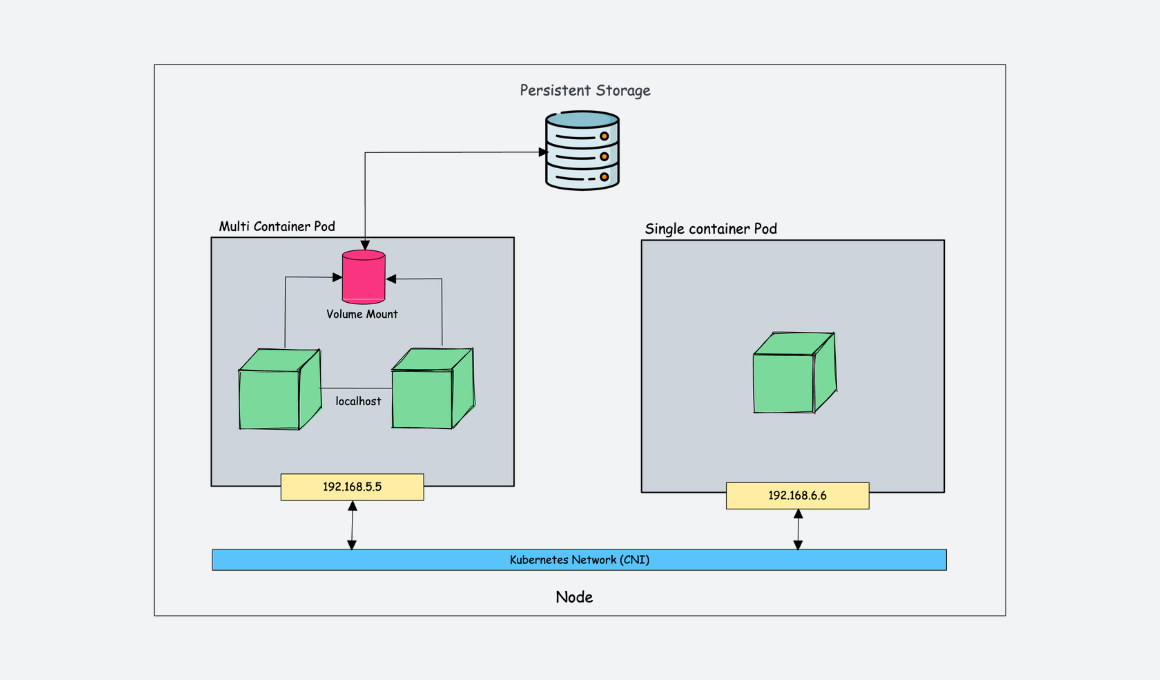
Pods : Un Pod est comme un appartement dans un immeuble. L'appartement fournit l'environnement essentiel (murs, électricité, eau) pour ses habitants (les conteneurs). Tous les habitants de l'appartement partagent la même adresse (adresse IP) et peuvent facilement communiquer entre eux. Ils partagent des ressources comme la cuisine et la salle de bain (volumes, réseau).
- Un Pod n'est pas un processus, c'est un environnement pour les containers
- Un pod ne peut pas être redémarré
- Il ne peut pas se "planter", les containers d'un pod "oui"
- C'est, donc, Ensemble logique composé de un ou plusieurs conteneurs
- Les conteneurs d'un pod fonctionnent ensemble (instanciation et destruction) et sont orchestrés sur un même hôte
- Les conteneurs partagent certaines spécifications du Pod :
- La stack IP (network namespace)
- Inter-process communication (PID namespace)
- Volumes
- IP: Le pod lui-même dispose d'une adresse IP unique, que tous les conteneurs du pod peuvent utiliser.
- Cycle de vie: Les conteneurs d'un pod sont créés et détruits en même temps
- Node: Tous les conteneurs d'un pod sont généralement co-localisés sur le même nœud du cluster Kubernetes.
C'est la plus petite et la plus simple unité dans Kubernetes
En savoir plus : https://kubernetes.io/fr/docs/concepts/workloads/pods/pod/
Kubernetes : Pod
Kubernetes : Pod
- Les Pods sont définis en YAML comme les fichiers
docker-compose:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80Kubernetes : Pod
Dans les statuts du pod on trouve la notion de phase d'exécution
- Phases :
Pending: accepté par le cluster, les container ne sont pas initialiséRunning: Au moins un des containers est en cours de démarrage, d'exécution ou de redémarrageSucceeded: Tous les containers se sont arrêtés avec un "exit code" à 0 (zéro); Le pod ne sera pas redémarréFailed: Tous les containers se sont arrêtés et au moins un a un exit code différent de 0Unknown: L'état du pod ne peut pas être déterminé
$ kubectl get pods -o wideen sortie :
NAME READY STATUS RESTARTS AGE IP NODE
xx-79c5968bdc-6lcfq 1/1 Running 0 84m 10.244.0.6 kind-cp
yy-ss7nk 1/1 Running 0 84m 10.244.0.5 kind-cpKubernetes : Pod
Dans les statuts du pod on trouve la notion de Conditions d'état des pods
- Conditions :
PodScheduled: Un nœud a été sélectionné avec succès pour "lancer" le pod, et la planification est terminée.ContainersReady: Tous les containers sont prêtsInitialized: Les "Init containers sont démarrés"Ready: Le pod est capable de répondre aux demandes ; par conséquent, il doit être inclus dans le service et les répartiteurs de charge.
kubectl describe pods <POD_NAME>en sortie
...
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
...Kubernetes : Pod
États des containers (States)
Les containers peuvent avoir seulement 3 états
- États:
Waiting: Les processus requis sont en cours d'exécution pour un démarrage réussiRunning: Le container est en cours d'exécutionTerminated: L'exécution du conteneur s'est déroulée et s'est terminée par un succès ou un échec.
$ kubectl get pods <POD_NAME> -o jsonpath='{.status}' | jqKubernetes : Pod
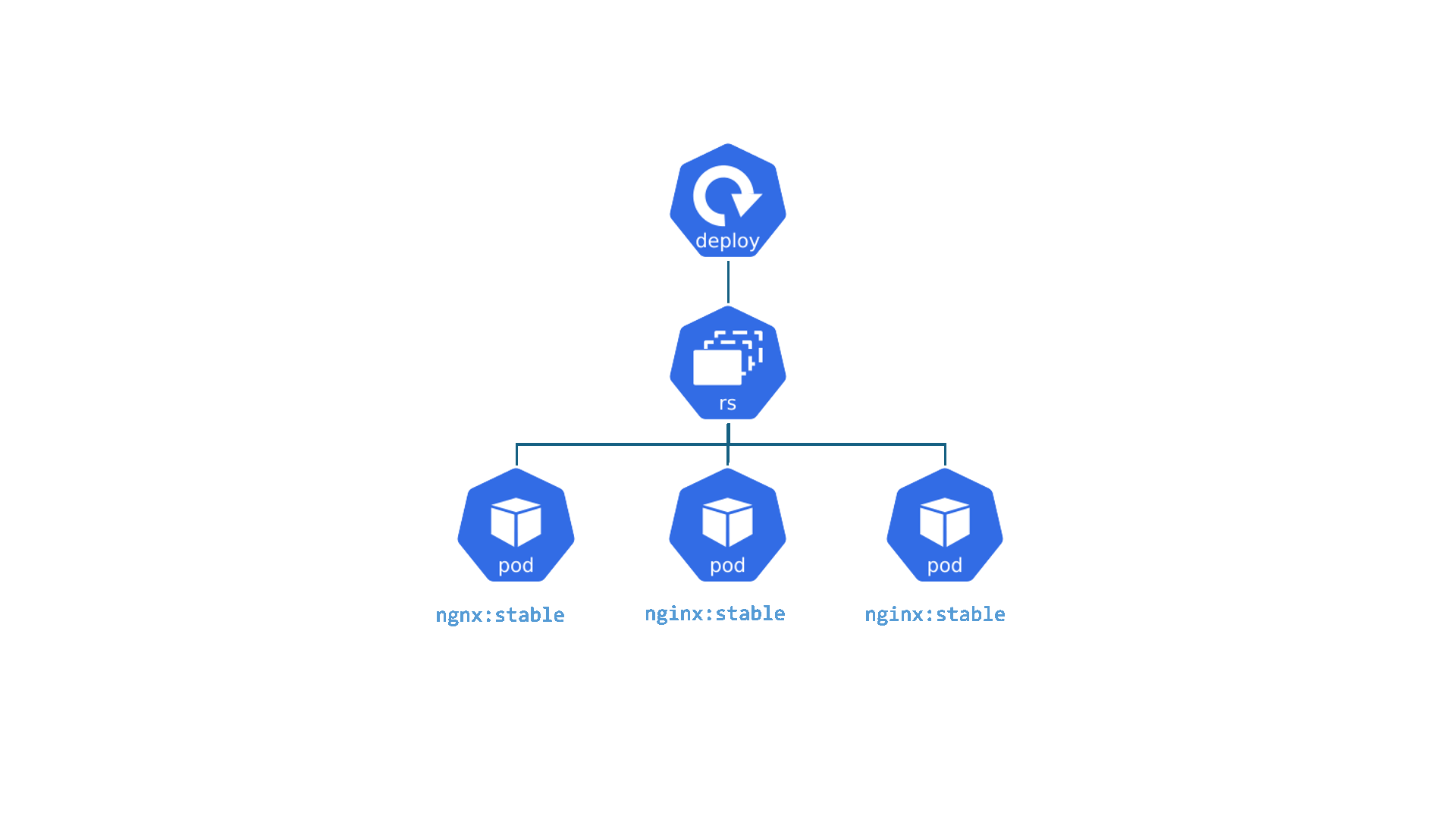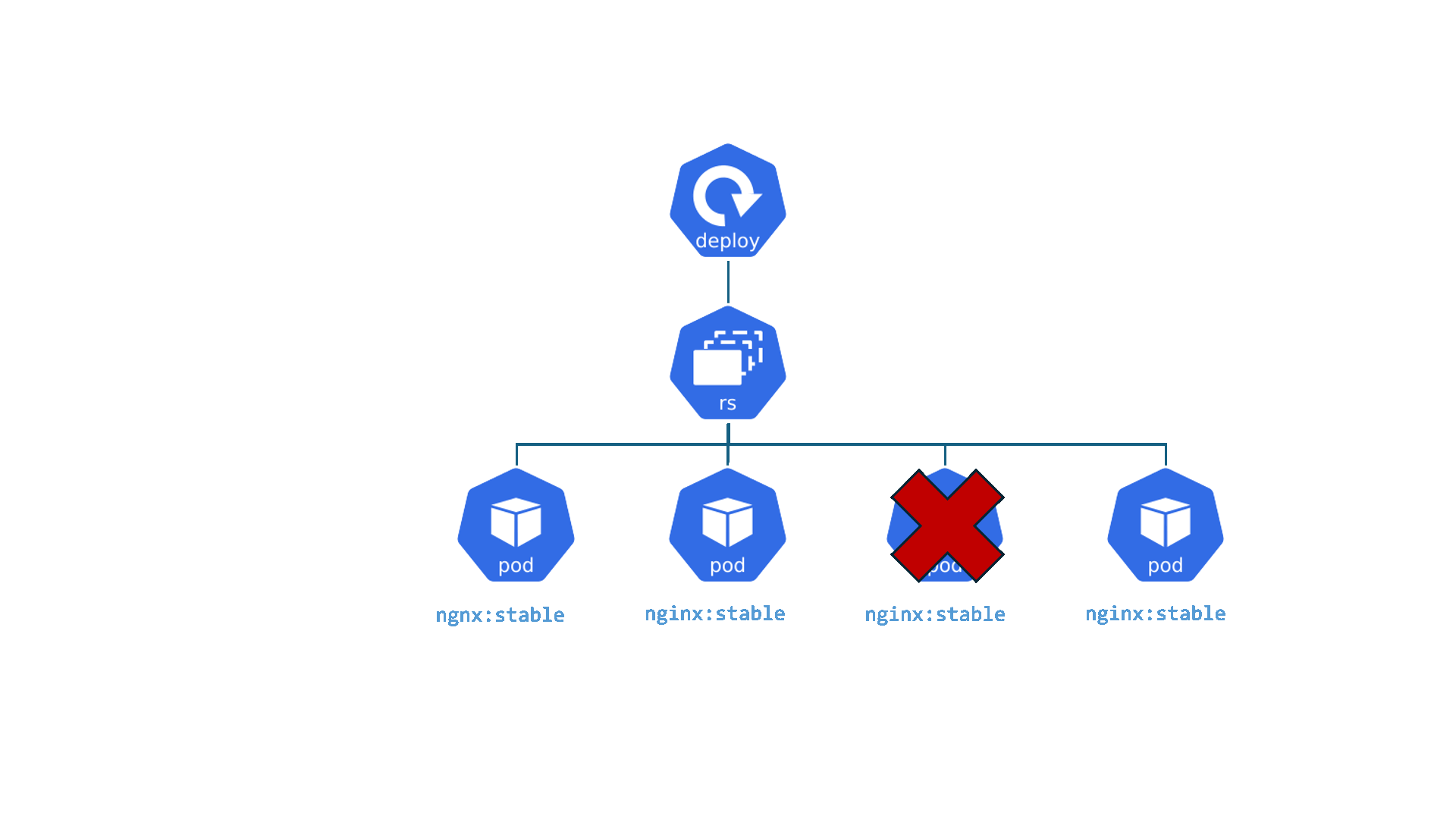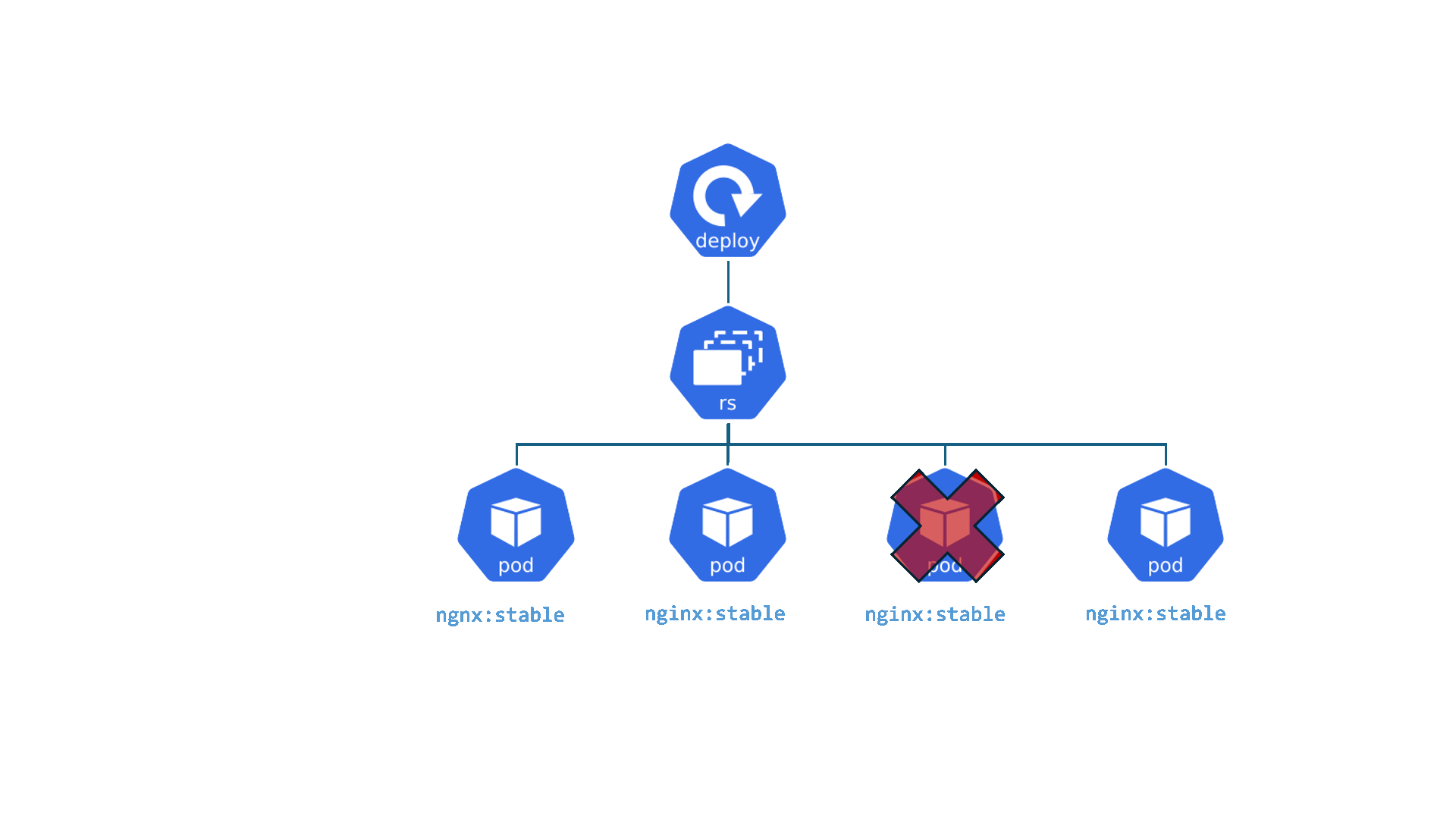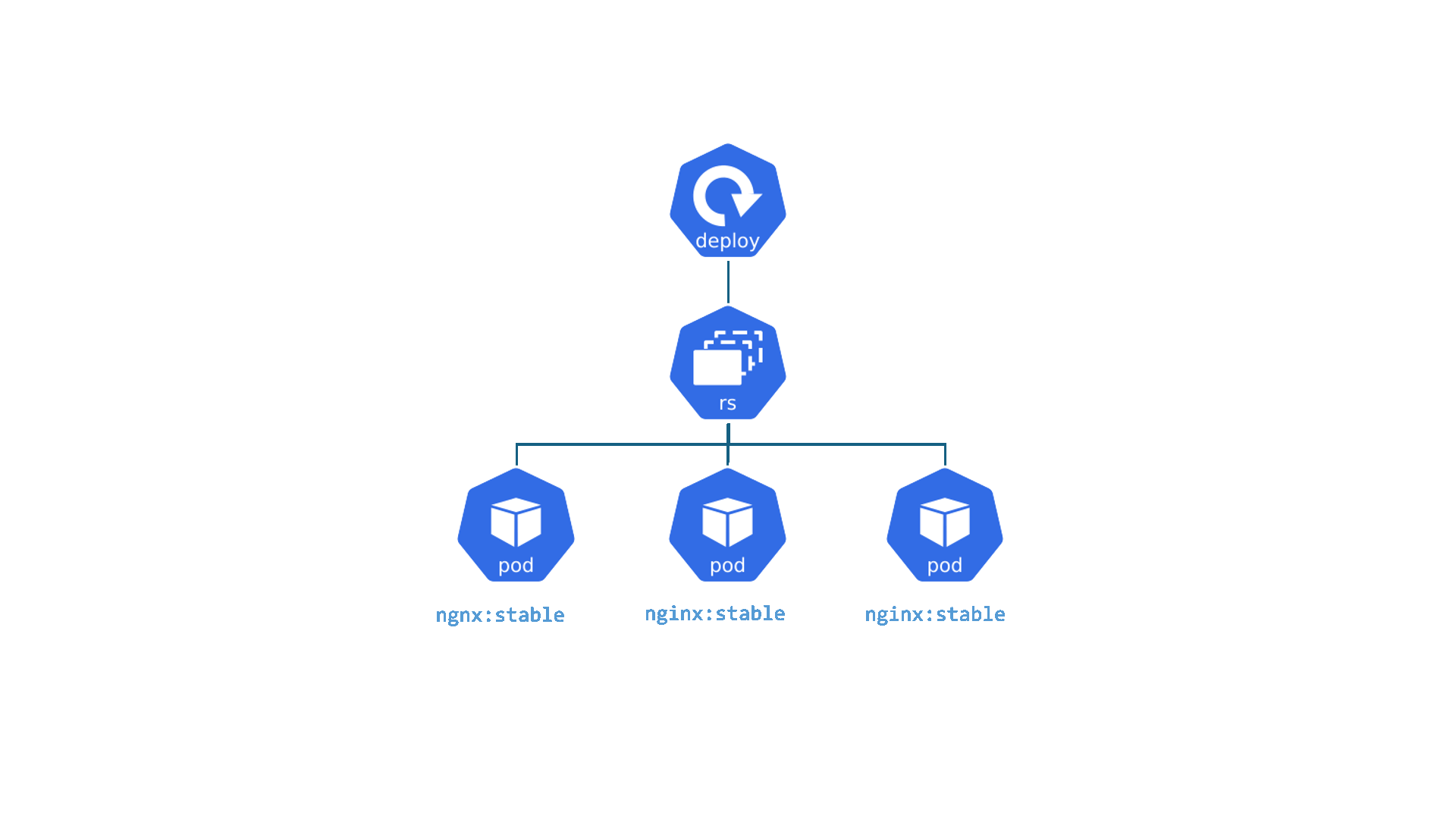
Kubernetes : Deployment
Deployments : C'est comme le gérant d'une chaîne de cafés identiques. Le travail du gérant est de s'assurer qu'un certain nombre de cafés (Pods/réplicas) sont toujours ouverts et fonctionnent de la même manière. Si un café ferme de manière inattendue, le gérant en ouvre un nouveau immédiatement. S'il veut changer le menu (mettre à jour l'application), le gérant déploie le changement dans tous les cafés, un par un, sans les fermer tous en même temps.
- Permet d'assurer le fonctionnement d'un ensemble de Pods
- Gère les Version, Update et Rollback
- Il est lié avec l'object ReplicaSet qui gère le cycle de vie et la mise à l'échelle des pods
Souvent combiné avec un objet de type service
Kubernetes : Deployment
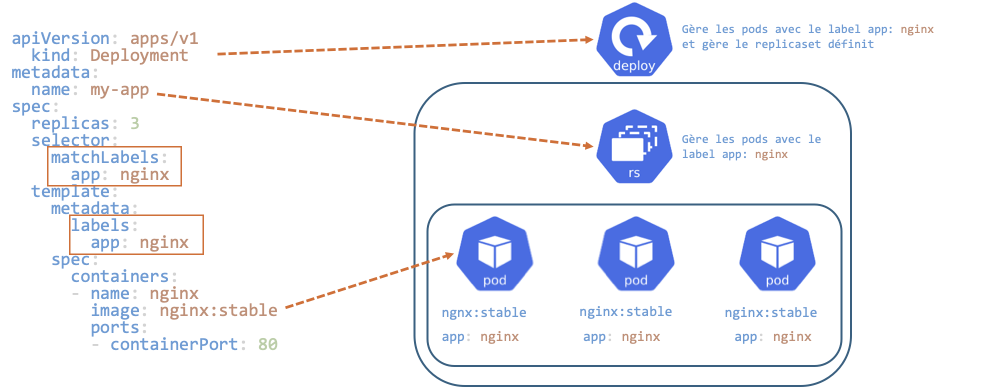
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:stable
ports:
- containerPort: 80Ou en ligne de commande
kubectl create deployment my-app --image=nginx:latest --replicas=3Kubernetes : Deployment
Kubernetes : DaemonSet
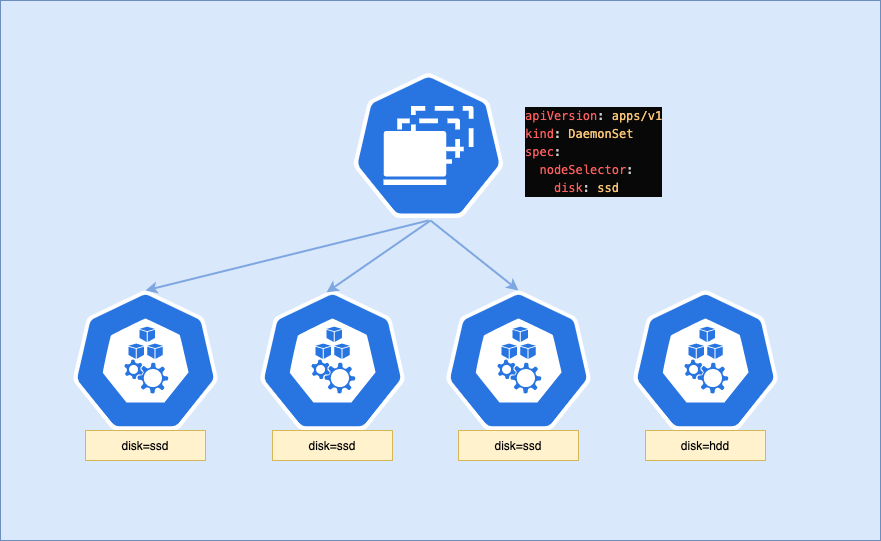
DaemonSets : Pensez à avoir un agent de sécurité à chaque étage d'un immeuble. Vous ne spécifiez pas combien de gardes vous avez besoin au total ; vous déclarez simplement que chaque étage doit en avoir exactement un. Si un nouvel étage est ajouté, un nouveau garde lui est automatiquement assigné.
- Assure que tous les noeuds exécutent une copie du pod sur tous les noeuds du cluster
- Ne connaît pas la notion de
replicas. - Utilisé pour des besoins particuliers comme :
- l'exécution d'agents de collection de logs comme
fluentdoulogstash - l'exécution de pilotes pour du matériel comme
nvidia-plugin - l'exécution d'agents de supervision comme NewRelic agent, Prometheus node exporter
- l'exécution d'agents de collection de logs comme
Kubernetes : DaemonSet
Kubernetes : DaemonSet
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ssd-monitor
spec:
selector:
matchLabels:
app: ssd-monitor
template:
metadata:
labels:
app: ssd-monitor
spec:
nodeSelector:
disk: ssd
containers:
- name: main
image: luksa/ssd-monitorKubernetes : StatefulSet
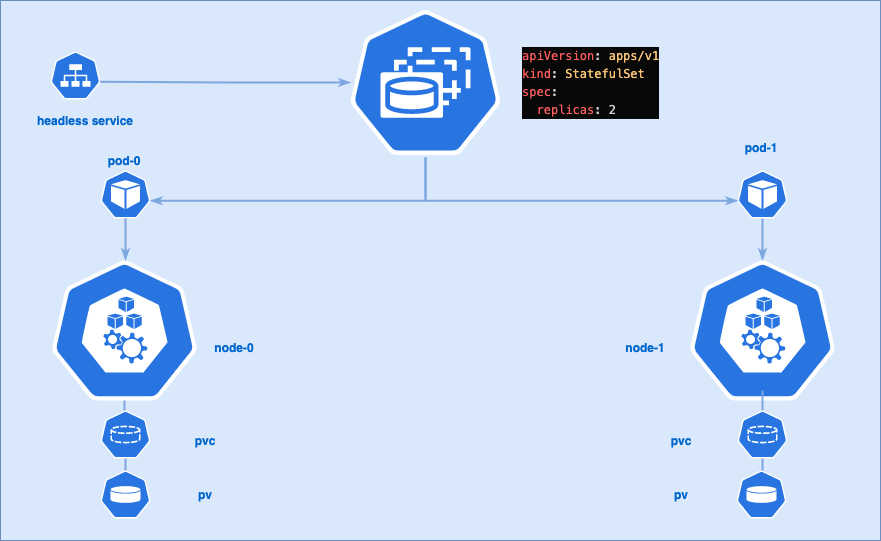
StatefulSets : C'est la différence entre le bétail (cattle) et les animaux de compagnie (pets). Un
Deploymentgère le bétail : si une vache tombe malade, vous la remplacez par une autre en bonne santé, et cela n'a pas d'importance. UnStatefulSetgère les animaux de compagnie : si votre chienFidoest malade, vous voulez que Fido soit soigné et revienne. Vous ne voulez pas un nouveau chien identique. Les StatefulSets donnent à chaque Pod une identité unique et stable (un nom commedb-0,db-1) et un stockage persistant qui lui est propre. C'est essentiel pour les applications comme les bases de données, où chaque instance a un rôle et des données spécifiques qui doivent être préservés.- Similaire au
Deploymentmais les noms des composants sont prédictibles - Les pods possèdent des identifiants uniques.
- Chaque replica de pod est créé par ordre d'index
- Nécessite un
Persistent Volumeet unStorage Class. Supprimer un StatefulSet ne supprime pas le PV associé
Kubernetes : StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx
serviceName: "nginx"
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80kubectl get po
NAME READY STATUS RESTARTS AGE
web-0 0/1 ContainerCreating 0 3s
❯ kubectl get po
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 9s
web-1 0/1 ContainerCreating 0 1s
❯ kubectl get po
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 12s
web-1 1/1 Running 0 4s
web-2 0/1 ContainerCreating 0 2s
❯ kubectl get po
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 15s
web-1 1/1 Running 0 7s
web-2 1/1 Running 0 5sKubernetes : StatefulSet avancé
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
app.kubernetes.io/name: mysql
data:
primary.cnf: |
[mysqld]
log-bin
replica.cnf: |
[mysqld]
super-read-only
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
app.kubernetes.io/name: mysql
serviceName: mysql
replicas: 3
template:
metadata:
labels:
app: mysql
app.kubernetes.io/name: mysql
spec:
initContainers:
- name: init-mysql
image: mysql:5.7
command:
- bash
- "-c"
- |
set -ex
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
if [[ $ordinal -eq 0 ]]; then
cp /mnt/config-map/primary.cnf /mnt/conf.d/
else
cp /mnt/config-map/replica.cnf /mnt/conf.d/
fi
....
- name: clone-mysql
image: gcr.io/google-samples/xtrabackup:1.0
command:
- bash
- "-c"
- |
set -ex
[[ -d /var/lib/mysql/mysql ]] && exit 0
# Skip the clone on primary (ordinal index 0).
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal -eq 0 ]] && exit 0
ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql
...
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ALLOW_EMPTY_PASSWORD
value: "1"
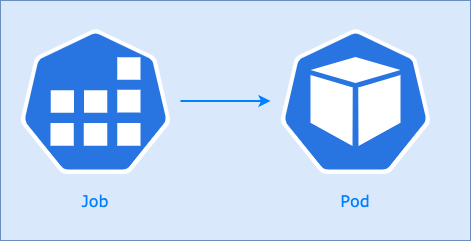
...Kubernetes : Job
Jobs : C'est comme une tâche ponctuelle pour un entrepreneur, par exemple, "peindre cette pièce". L'entrepreneur (Job) vient, apporte ses outils (conteneur), effectue le travail (exécute le processus), et part une fois que le travail est terminé avec succès. S'il renverse la peinture et fait un gâchis (échec), il devra peut-être nettoyer et réessayer.
- Crée des pods et s'assurent qu'un certain nombre d'entre eux se terminent avec succès.
- Peut exécuter plusieurs pods en parallèle
Si un noeud du cluster est en panne, les pods sont reschedulés vers un autre noeud.
Kubernetes : Job
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
parallelism: 1
completions: 1
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: OnFailureEn ligne de commande :
kubectl create job exemple-job --image=busybox -- /bin/sh -c "date; echo Hello from the Kubernetes cluster"Kubernetes: CronJob
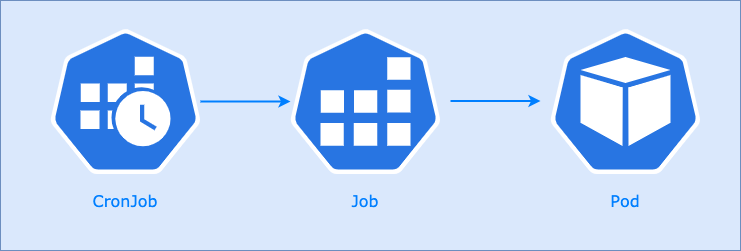
CronJobs : Imaginez un service de nettoyage quotidien programmé pour un bureau. Le service (CronJob) est configuré pour venir chaque jour à 18h (l'horaire) pour effectuer la tâche de nettoyage (le Job). C'est une tâche récurrente et automatisée.
- Un CronJob permet de lancer des Jobs de manière planifiée.
- la programmation des Jobs se définit au format
Cron le champ
jobTemplatecontient la définition de l'application à lancer commeJob.
Kubernetes : CronJob
apiVersion: batch/v1
kind: CronJob
metadata:
name: batch-job-every-fifteen-minutes
spec:
schedule: '0,15,30,45 * * * *'
jobTemplate:
spec:
template:
metadata:
labels:
app: periodic-batch-job
spec:
restartPolicy: OnFailure
containers:
- name: pi
image: perl
command:
- perl
- '-Mbignum=bpi'
- '-wle'
- print bpi(2000)En ligne de commande :
kubectl create cronjob exemple-cronjob --image=busybox --schedule="*/5 * * * *" -- /bin/sh -c "date; echo Hello from the Kubernetes cluster"Susprendre un cronjob :
kubectl patch cronjob <cronjob-name> -p '{"spec" : {"suspend" : true }}'Reprendre l'exécution :
kubectl patch cronjob <cronjob-name> -p '{"spec" : {"suspend" : false }}'Kubernetes : Service
- Services : C'est comme le réceptionniste dans un grand immeuble de bureaux. Vous n'avez pas besoin de connaître l'emplacement exact ou le numéro de téléphone direct de la personne à qui vous voulez parler (un Pod spécifique, qui peut changer). Vous dites simplement au réceptionniste (Service) qui vous voulez joindre (en utilisant un sélecteur de label comme
app=ventes), et il vous mettra en relation avec une personne disponible dans ce département. Le réceptionniste fournit un point de contact stable.
Un Service est un objet Kubernetes qui fournit une abstraction pour accéder à un ensemble de Pods. Il agit comme un point d'entrée unique et stable pour les applications, même si les Pods derrière lui sont créés, détruits ou déplacés.
Voici ses principales caractéristiques :
- Point d'accès stable : Chaque Service possède une adresse IP virtuelle (
ClusterIP) et un nom DNS stables qui ne changent pas pendant son cycle de vie. Les applications clientes se connectent au Service plutôt qu'aux Pods directement, dont les adresses IP sont éphémères. - Découverte de services et sélection de Pods : Un Service utilise des
labelset dessélecteurspour identifier dynamiquement l'ensemble des Pods auxquels il doit acheminer le trafic. Cela permet de découpler les applications qui consomment le service des Pods qui le fournissent. - Répartition de charge (Load Balancing) : Par défaut, un Service répartit le trafic réseau de manière égale (round-robin) entre tous les Pods correspondants, assurant ainsi la haute disponibilité et la scalabilité des applications.
Cet objet est fondamental pour la communication inter-applicative au sein du cluster. Nous aborderons en détail les différents types de Services (comme ClusterIP, NodePort, et LoadBalancer) et leurs cas d'usage dans un chapitre dédié au réseau dans Kubernetes.
Extras : Init Containers
- On peut définir des conteneurs qui doivent s'exécuter avant les conteneurs principaux
- Ils seront exécutés dans l'ordre (au lieu d'être exécutés en parallèle)
- ⚠️ Ils doivent tous réussir avant que les conteneurs principaux ne soient démarrés
exemple :
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app.kubernetes.io/name: MyApp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
- name: init-mydb
image: busybox:1.28
command: ['sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"]Extras : Init Containers
- Lors du démarrage d'un Pod, le kubelet retarde l'exécution des conteneurs d'initialisation jusqu'à ce que le réseau et le stockage soient prêts. Ensuite, le kubelet exécute les conteneurs d'initialisation du Pod dans l'ordre où ils apparaissent dans la spécification du Pod.
- Chaque conteneur d'initialisation doit se terminer avec succès avant que le suivant ne démarre.
- Si un conteneur ne parvient pas à démarrer en raison de l'environnement d'exécution ou se termine avec un échec, il est relancé conformément à la
restartPolicydu Pod. Cependant, si larestartPolicydu Pod est définie surAlways, les conteneurs d'initialisation utilisent la restartPolicy OnFailure. - Un Pod ne peut pas être
Readytant que tous les conteneurs d'initialisation n'ont pas réussi. Les ports d'un conteneur d'initialisation ne sont pas agrégés sous un Service. - Un Pod en cours d'initialisation est dans l'état
Pendingmais doit avoir une conditionInitializeddéfinie à false. Si le Pod redémarre, ou est redémarré, tous les conteneurs d'initialisation doivent s'exécuter à nouveau.
- Utilisations possibles
- Charger/préparer des données (code, data, configuration,...)
- Organiser les update (migrations) de bases de données
- Attendre que certains services soient démarrés (bonne alternative à des sondes)
- ...
Méthode déclarative et impérative pour créer des objets Kubernetes
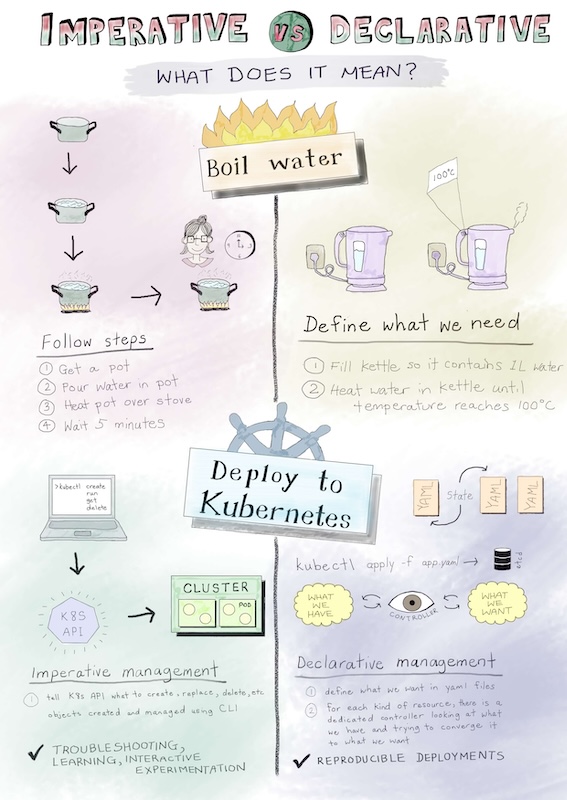
déclaratif vs impératif
La méthode déclarative
L'approche déclarative consiste à décrire l'état désiré des ressources. Vous déclarez ce que vous voulez obtenir, et Kubernetes s'occupe de mettre en place et de maintenir cet état.
- Consiste à définir un objet dans un fichier yaml puis à créer l'objet avec la commande kubectl apply ou kubectl create
- Recommandé pour garder un historique de tous les objets créés, puis de faire du versionning
Il facilite également le travail entre équipe.
- Avantages :
- Simplicité: Plus facile à comprendre et à maintenir que les commandes impératives.
- Reproductibilité: Les fichiers de configuration peuvent être versionnés et utilisés pour recréer un environnement à tout moment.
- Idéal pour l'automatisation: Parfaitement adapté aux outils d'intégration continue et de déploiement continu (CI/CD).
- Détection des dérives: Kubernetes compare l'état actuel du cluster à l'état désiré défini dans les fichiers de configuration et effectue les modifications nécessaires pour rétablir la conformité.
- Inconvénients:
- Moins de flexibilité pour certaines opérations: Certaines opérations peuvent nécessiter des commandes impératives pour être effectuées.
La méthode impérative
L'approche impérative consiste à donner des instructions directes à Kubernetes pour effectuer des actions spécifiques. On décrit comment réaliser une tâche, pas seulement le résultat final.
- Permet la création rapide des ressources à l'aide d'une commande
- Gain un temps considérable lors de l'examen
Recommandé dans des environnements de lab ou pour tester une commande
- Avantages :
- Flexibilité: Grande liberté dans la façon de gérer les ressources.
- Contrôle précis: Possibilité d'effectuer des actions très spécifiques.
- Inconvénients :
- Erreur humaine: Le risque d'erreur est plus élevé car chaque action doit être spécifiée manuellement.
- Difficulté de suivi: Il peut être difficile de retracer les modifications apportées à un état donné du cluster.
- Moins adapté aux environnements complexes: La gestion manuelle de nombreuses ressources peut devenir rapidement fastidieuse et source d'erreurs.
La méthode impérative
- Creation d'un pod NGINX:
kubectl run nginx --image=nginx- Générez le fichier YAML du manifeste d'un pod (-o yaml), sans le créer (--dry-run):
kubectl run nginx --image=nginx --dry-run=client -o yaml- Générer un déploiement avec 4 réplicas:
kubectl create deployment nginx --image=nginx --replicas=4La méthode impérative
- Mise à l'échelle d'un déploiement à l'aide de la commande
kubectl scale:
kubectl scale deployment nginx --replicas=4- Il est possible aussi d'enregistrer la définition YAML dans un fichier et de le modifier:
kubectl create deployment nginx --image=nginx --dry-run=client -o yaml > nginx-deployment.yaml- Ensuite mettre à jour le fichier YAML avec les réplicas ou tout autre champ avant de créer le déploiement.
La méthode impérative
- Créer un service nommé redis-service de type ClusterIP pour exposer le pod redis sur le port 6379:
kubectl expose pod redis --port=6379 --name redis-service --dry-run=client -o yaml- Créer un service nommé nginx de type NodePort pour exposer le port 80 du pod nginx sur le port 30080 des nœuds:
kubectl expose pod nginx --type=NodePort --port=80 --name=nginx-service --dry-run=client -o yaml- Cela utilisera automatiquement les labels du pod comme sélecteurs, sans possibilité de spécifier le port du nœud. Avec le fichier généré, ajoutez le port de nœud manuellement avant de créer le service avec le pod.
- Ou:
kubectl create service nodeport nginx --tcp=80:80 --node-port=30080 --dry-run=client -o yamlCeci n'utilisera pas les labels des pods comme sélecteurs.
Quand utiliser quelle méthode ?
- Méthode impérative:
- Pour des tâches ponctuelles ou des dépannages.
- Lorsque vous avez besoin d'un contrôle très précis sur les ressources.
- Méthode déclarative:
- Pour la gestion quotidienne des ressources.
- Pour automatiser les déploiements et les mises à jour.
- Pour construire des pipelines CI/CD.
KUBERNETES : Networking
Kubernetes : Network plugins
Kubernetes : CNI
- Container Network Interface
- Projet dans la CNCF
- Standard pour la gestion du réseau en environnement conteneurisé
- Les solutions précédentes s'appuient sur CNI
- Flexibilité: Il offre une grande flexibilité pour choisir le type de réseau à utiliser (bridge, VLAN, VXLAN, etc.) et les fonctionnalités associées (routage, NAT, etc.).
Plugin: Un CNI est implémenté sous forme de plugin, ce qui permet de choisir le plugin adapté aux environnements et besoins.
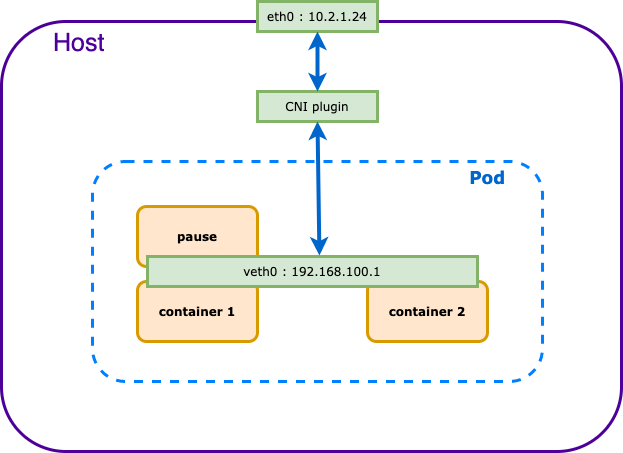
- Rôle d'un CNI dans Kubernetes
- Création d'interfaces réseau: Lorsqu'un pod est créé, le CNI est appelé pour créer une ou plusieurs interfaces réseau pour les conteneurs du pod.
- Configuration IP: Le CNI attribue une adresse IP à chaque interface réseau et configure les routes nécessaires.
- Gestion des réseaux: Le CNI gère la configuration réseau au cours du cycle de vie du pod (création, modification, suppression).
Kubernetes : POD Networking
Kubernetes : Services
- Une abstraction de niveau supérieur qui expose un ensemble de pods sous un nom et une adresse IP stables.
- Permet d'accéder à un groupe de pods de manière uniforme, même si les pods individuels sont créés, mis à jour ou supprimés.
- Rendre un ensemble de pods accessibles depuis l'extérieur
- Load Balancing entre les pods d'un même service
Kubernetes : Services
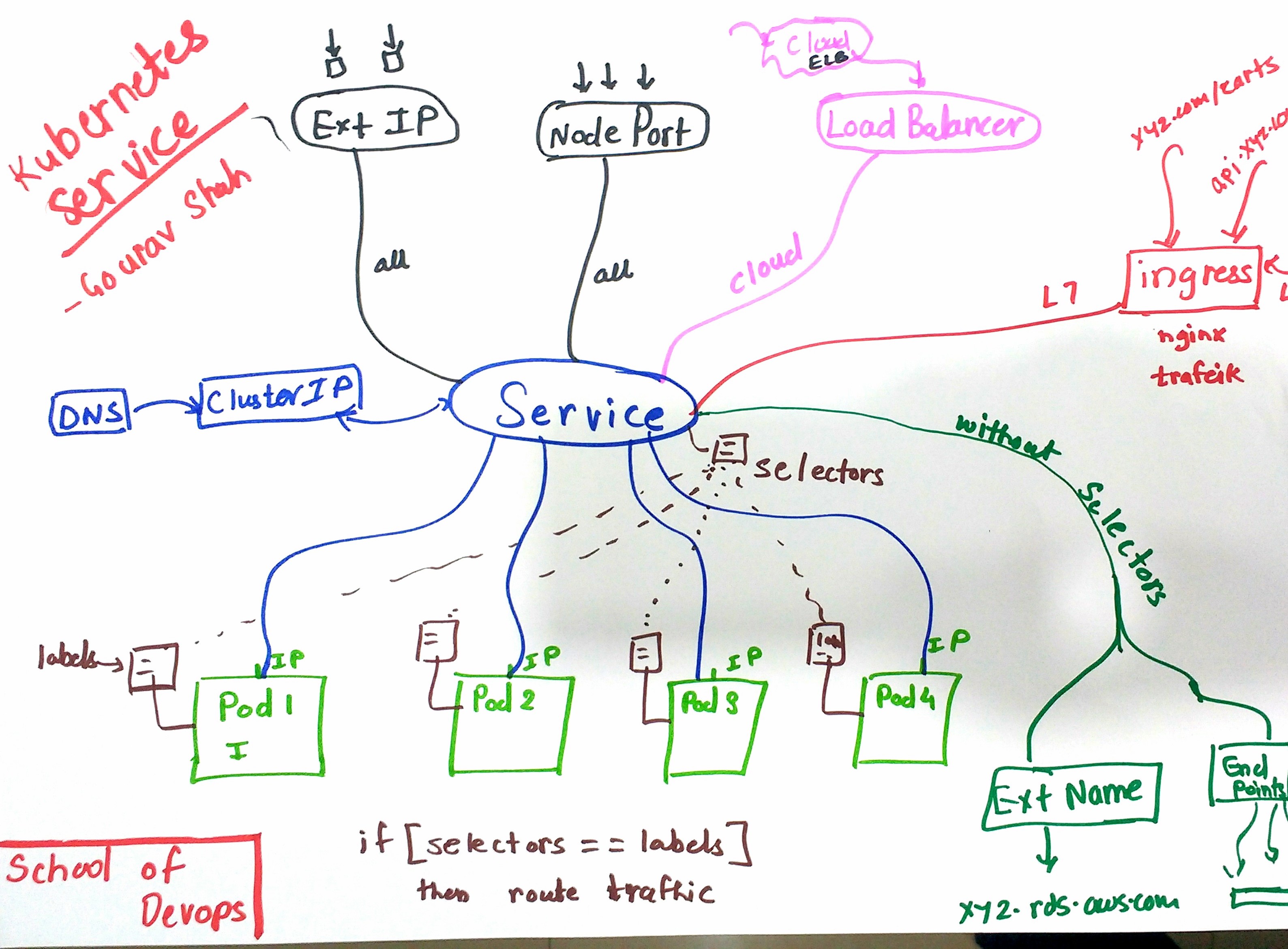
Kubernetes : Services : ClusterIP
ClusterIP:- C'est le service par défaut
- Attribue une adresse IP interne accessible uniquement au sein du cluster, cette adresse est accessible dans le cluster par les pods et les noeuds
- Expose le service pour les connexions depuis l'intérieur du cluster
- L'application peut utiliser le port de l'application directement
Kubernetes : Services : ClusterIP
apiVersion: v1
kind: Service
metadata:
name: the-service
spec:
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
app: web# déploiement
kubectl create deployment web --image=nginx
# service
# par défaut type= ClusterIP
kubectl expose deploy web --port=80 --target-port=8080Kubernetes : Services : HeadLess ClusterIP
Headless ClusterIP:- Il n'y pas de load balancing
- Le service renvoie sur une requête DNS la liste des IP des pods et non pas l'IP du service
- Le service donc envoi les requêtes sur les pods même ceux-ci ne fonctionnent pas
- C'est donc à l'application de gérer la tolérance de panne et le routage

Kubernetes : Services : HeadLess ClusterIP
apiVersion: v1
kind: Service
metadata:
name: my-headless-service
spec:
clusterIP: None # <--
selector:
app: test-app
ports:
- protocol: TCP
port: 80
targetPort: 3000# déploiement
kubectl create deployment web --image=nginx
# service
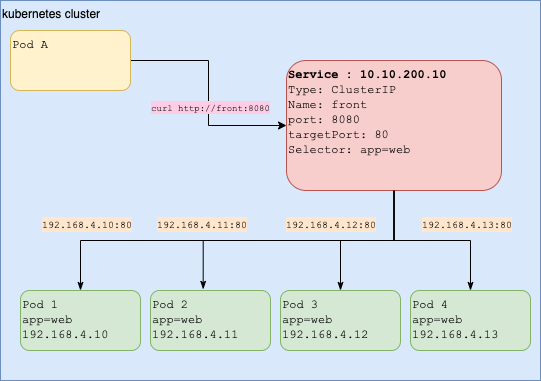
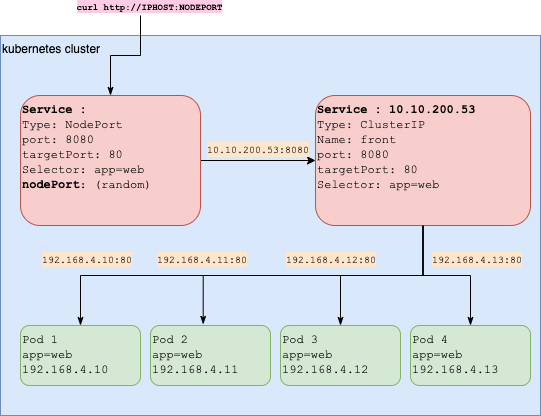
kubectl expose deploy web --port=80 --target-port=8080 --cluster-ip noneKubernetes : Services : NodePort
NodePort:- chaque noeud du cluster ouvre un port statique (entre 30000-32767 par défaut) et redirige le trafic vers le port indiqué
- Un service de type ClusterIP est créé automatiquement lors de la création du Service NodePort
- Expose le service au trafic externe
- Expose le service sur un port sur chaque nœud du cluster
- Pb : le code doit être changé pour accéder au bon n° de port
Kubernetes : Services : NodePort
apiVersion: v1
kind: Service
metadata:
name: my-nginx
spec:
type: NodePort
ports:
- port: 8080
targetPort: 80
protocol: TCP
name: http
selector:
app: my-nginx# déploiement
kubectl create deployment web --image=nginx
# service
kubectl expose deploy web --type NodePort --protocol TCP --port 80 --target-port 8080Kubernetes : Services : LoadBalancer
LoadBalancer: expose le service à l'externe en utilisant le loadbalancer d'un cloud provider (AWS, Google, Azure)- Expose des services au trafic externe
- Expose le service sur chaque nœud (comme NodePort)
- Fournit un répartiteur de charge
Kubernetes : Services : LoadBalancer
Service de type Spécial
- Load Balancing : intégration avec des cloud provider :
- AWS ELB
- GCP
- Azure Kubernetes Service
- OpenStack
- ...
apiVersion: v1
kind: Service
metadata:
name: myapp
spec:
ports:
- port: 9000
targetPort: 1234
selector:
app: myapp
type: LoadBalancer# déploiement
kubectl create deployment web --image=myapp
# service
kubectl expose deploy web --type LoadBalancer --protocol TCP --port 9000 --target-port 1234Kubernetes : Services : ExternalName
ExternalName- Un alias vers un service externe en dehors du cluster
- La redirection se produit au niveau DNS, il n'y a aucune proxyfication ou forward
Exemples d'utilisation concrets :
- Intégration avec des services tiers:
- Base de données externe: Vous avez une base de données hébergée sur un service cloud comme AWS RDS. Au lieu d'utiliser l'adresse IP ou l'URL complète, vous pouvez créer un service ExternalName qui pointera vers le nom DNS de cette base de données. Cela facilite la configuration de vos applications dans le cluster.
- API externe: Vous souhaitez consommer une API publique (comme une API météo ou une API de paiement). En créant un service ExternalName qui pointe vers l'URL de cette API, vous pouvez y accéder depuis vos pods comme si c'était un service interne.
- Migration progressive:
- Transition vers un nouveau service: Vous êtes en train de migrer vers un nouveau service et souhaitez maintenir l'ancien pendant un certain temps. Vous pouvez créer un service ExternalName qui pointera alternativement vers l'ancien ou le nouveau service, selon votre configuration.
- Abstraction de noms DNS complexes:
- Noms DNS longs ou difficiles à retenir: Si vous avez des noms DNS très longs ou complexes, un service ExternalName peut servir d'alias plus court et plus facile à mémoriser.
- Microservices:
- Simplifie les interactions entre différents microservices qui peuvent être déployés sur des infrastructures différentes.
- Tests:
- Permet de simuler des environnements de test en pointant vers des services de test.
Kubernetes : Services : ExternalName
Il est aussi possible de mapper un service avec un nom de domaine en spécifiant le paramètre spec.externalName.
kind: Service
apiVersion: v1
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.comEn ligne de commande :
kubectl create service externalname my-service --external-name my.database.example.comKubernetes : Services : External IPs
On peut définir une IP externe permettant d'accèder à un service interne
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app: nginx
name: nginx
spec:
externalIPs:
- 1.2.3.4
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginxEn ligne de commande :
kubectl expose deploy nginx --port=80 --external-ip=1.2.3.4Kubernetes : Services Résumé
ClusterIP: C'est le type de service par défaut. Il fournit une IP virtuelle stable accessible uniquement à l'intérieur du cluster, parfait pour la communication entre microservices.NodePort: Il étend ClusterIP en exposant le service sur un port spécifique de chaque nœud du cluster. C'est utile pour le développement ou les environnements de test.LoadBalancer: Idéal pour la production, il étend NodePort en provisionnant automatiquement un load balancer externe (souvent fourni par le cloud provider).ExternalName: Un cas particulier qui permet de créer un alias CNAME vers un service externe au cluster.Headless Service: A Utiliser quand vous avez besoin d'une découverte de service fine, sans Load Balancing. Très utile pour les bases de données distribuées.ExternalIPs: Permet d'exposer un service Kubernetes sur une adresse IP spécifique qui existe déjà sur l'un des nœuds du cluster, offrant ainsi un accès direct depuis l'extérieur sans passer par un LoadBalancer.
Kubernetes : Quand utiliser tel ou tel type de service ?
Choisir le bon type de service dans Kubernetes est essentiel pour l'architecture de votre application. Voici un guide pour vous aider à décider :
ClusterIP- Quand l'utiliser ? Pour la communication interne au cluster. C'est le type par défaut et le plus courant.
- Cas d'usage typique : Un pod frontend qui doit communiquer avec un pod backend (par exemple, une API ou une base de données) à l'intérieur du même cluster. Le service n'est pas exposé à l'extérieur.
NodePort- Quand l'utiliser ? Pour exposer un service à l'extérieur du cluster à des fins de développement, de test ou de démonstration. Il n'est généralement pas recommandé pour la production.
- Cas d'usage typique : Vous développez une application sur Minikube ou un cluster on-premise et vous avez besoin d'un accès rapide à un service depuis votre machine locale via
http://<IP_DU_NOEUD>:<NODE_PORT>.
LoadBalancer- Quand l'utiliser ? Pour exposer une application à Internet en production, en particulier sur un fournisseur de cloud (AWS, GCP, Azure).
- Cas d'usage typique : Une application web ou une API que les utilisateurs finaux doivent pouvoir atteindre. Le fournisseur de cloud provisionne automatiquement un load balancer externe qui distribue le trafic vers vos services.
ExternalName- Quand l'utiliser ? Lorsque vous souhaitez qu'un service Kubernetes soit un alias pour un service externe (en dehors du cluster).
- Cas d'usage typique : Votre application dans le cluster doit se connecter à une base de données externe gérée (comme Amazon RDS) ou à une API tierce. Au lieu de coder en dur l'URL externe, vous créez un service
ExternalName(database.local) qui pointe vers l'endpoint externe (xxxx.rds.amazonaws.com).
Headless Service- Quand l'utiliser ? Lorsque vous n'avez pas besoin de load balancing et que vous voulez que les clients se connectent directement aux pods. La découverte de service renvoie les IPs de tous les pods.
- Cas d'usage typique : Pour les applications StatefulSets comme les bases de données distribuées (par exemple, Cassandra, MongoDB) où les pods ont des identités réseau stables et doivent pouvoir se découvrir et communiquer entre eux.
ExternalIPs- Quand l'utiliser ? Un cas d'usage plus avancé où vous voulez assigner une IP externe statique que vous gérez vous-même à un service. Le trafic arrivant sur cette IP sur n'importe quel noeud est routé vers le service.
- Cas d'usage typique : Vous avez un cluster on-premise et un routeur externe qui peut diriger le trafic vers les IPs de vos nœuds. Vous pouvez alors exposer un service sur une IP spécifique de ce routeur.
Kubernetes : Services Discovery
- Kubernetes prend en charge 2 modes principaux de "service discovery"
- Variables d'environnement
- DNS
- Variables d'environnement
- {SERVICE_NAME} _SERVICE_HOST
- {SERVICE_NAME} _SERVICE_PORT
- DNS
- Ensemble d'enregistrements DNS pour chaque service
Kubernetes : Services Discovery
- Exemple
- Active service : my-app
- Variables d'environnement
- MY_APP_SERVICE_HOST=
<Cluster IP Address> - MY_APP_SERVICE_PORT=
<Service Port>
- MY_APP_SERVICE_HOST=
Kubernetes : Services Discovery
- exemple :
kubectl get svc
web ClusterIP 10.96.163.5 <none> 80/TCP 3m56s
kubectl exec web-96d5df5c8-lfmhs -- env | sort
WEB_SERVICE_HOST=10.96.163.5
WEB_SERVICE_PORT=80Kubernetes : Services Discovery
- Exemple name: my-app namespace: default
- Les application dans les pods peuvent utiliser le nom
my-appcomme nom d'hôte dans le mêmenamespace - Les application dans les pods peuvent utiliser le nom
my-app.defaultcomme nom d'hôte dans d'autresnamespace
- Les application dans les pods peuvent utiliser le nom
- Syntaxe FQDN -
<svc name>.<ns>.svc.cluster.local
ex: my-app.default.svc.cluster.local
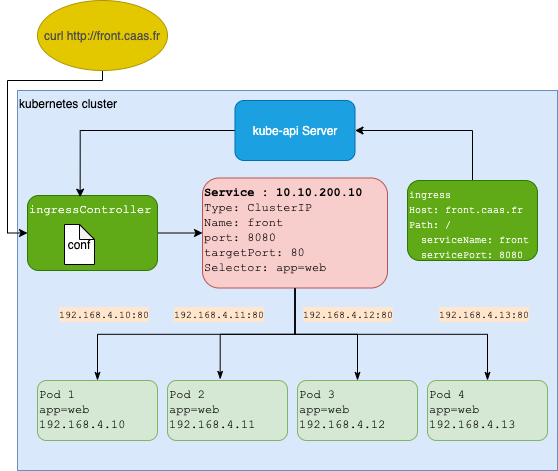
Kubernetes: Ingress
- L'objet
Ingresspermet d'exposer un service à l'extérieur d'un cluster Kubernetes - Il sont faits pour les services de type HTTP (et pas pour UDP et TCP)
- Il permet de fournir une URL visible permettant d'accéder un Service Kubernetes
- Il permet d'avoir des terminations TLS, de faire du Load Balancing, etc...
- Ils ont besoin d'un ingress Controller pour fonctionner
Kubernetes : Ingress
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
cert-manager.io/cluster-issuer: le
meta.helm.sh/release-name: argocd
meta.helm.sh/release-namespace: argocd
labels:
app.kubernetes.io/component: server
app.kubernetes.io/instance: argocd
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: argocd-server
app.kubernetes.io/part-of: argocd
app.kubernetes.io/version: v2.10.1
helm.sh/chart: argo-cd-6.0.14
name: argocd-server
namespace: argocd
spec:
ingressClassName: nginx
rules:
- host: argocd.caas.fr
http:
paths:
- backend:
service:
name: argocd-server
port:
number: 443
path: /
pathType: Prefix
tls:
- hosts:
- argocd.caas.fr
secretName: argocd-server-tlsKubernetes : Ingress Controller
Pour utiliser un Ingress, il faut un Ingress Controller
Il existe plusieurs solutions OSS ou non :
- Traefik : https://github.com/containous/traefik
- Istio : https://github.com/istio/istio
- Linkerd : https://github.com/linkerd/linkerd
- Contour : https://www.github.com/heptio/contour/
- Nginx Controller : https://github.com/kubernetes/ingress-nginx
⚠︎ Note : Il est possible d'avoir plusieurs Ingress Controller sur un cluster il suffira dans les objets ingress de préciser sur quelle classe d'ingress on souhaite le créer.
Ca se fait par l'attribut ingressClassName.
Ces classes sont créees au moment de l'installation du contrôleur.
Les Ingress vont bientôt être dépréciés en faveur des Gateway API qui sont la nouvelle génération de Kubernetes Ingress, Load Balancing, et Service Mesh APIs.
Plus d'informations ici : https://gateway-api.sigs.k8s.io/
Kubernetes : Gateway API
Les Gateway APIs sont une évolution des Ingress Controllers, offrant une approche plus moderne et flexible pour gérer le trafic entrant dans un cluster Kubernetes. Voici les points essentiels :
Architecture en layers:
- GatewayClass : Définit l'implémentation (comme NGINX, Traefik, etc.)
- Gateway : Instance spécifique qui gère le trafic entrant
- Route : Définit les règles de routage (HTTP, TCP, etc.)
Avantages principaux:
- Configuration plus fine et granulaire
- Support natif de plusieurs protocoles
- Meilleure séparation des responsabilités
- API plus extensible et cohérenteCas d'utilisation:
- Multi-tenancy avec isolation du trafic
- Gestion avancée du routage
- Configuration du TLS
- Gestion du trafic nord-sud et est-ouestDifférence avec les Ingress:
Les Gateway APIs offrent plus de fonctionnalités que les Ingress traditionnels :
- Support multi-protocole natif
- Meilleure extensibilité
- Configuration plus détaillée
- Meilleure séparation des rôlesKubernetes : Gateway API
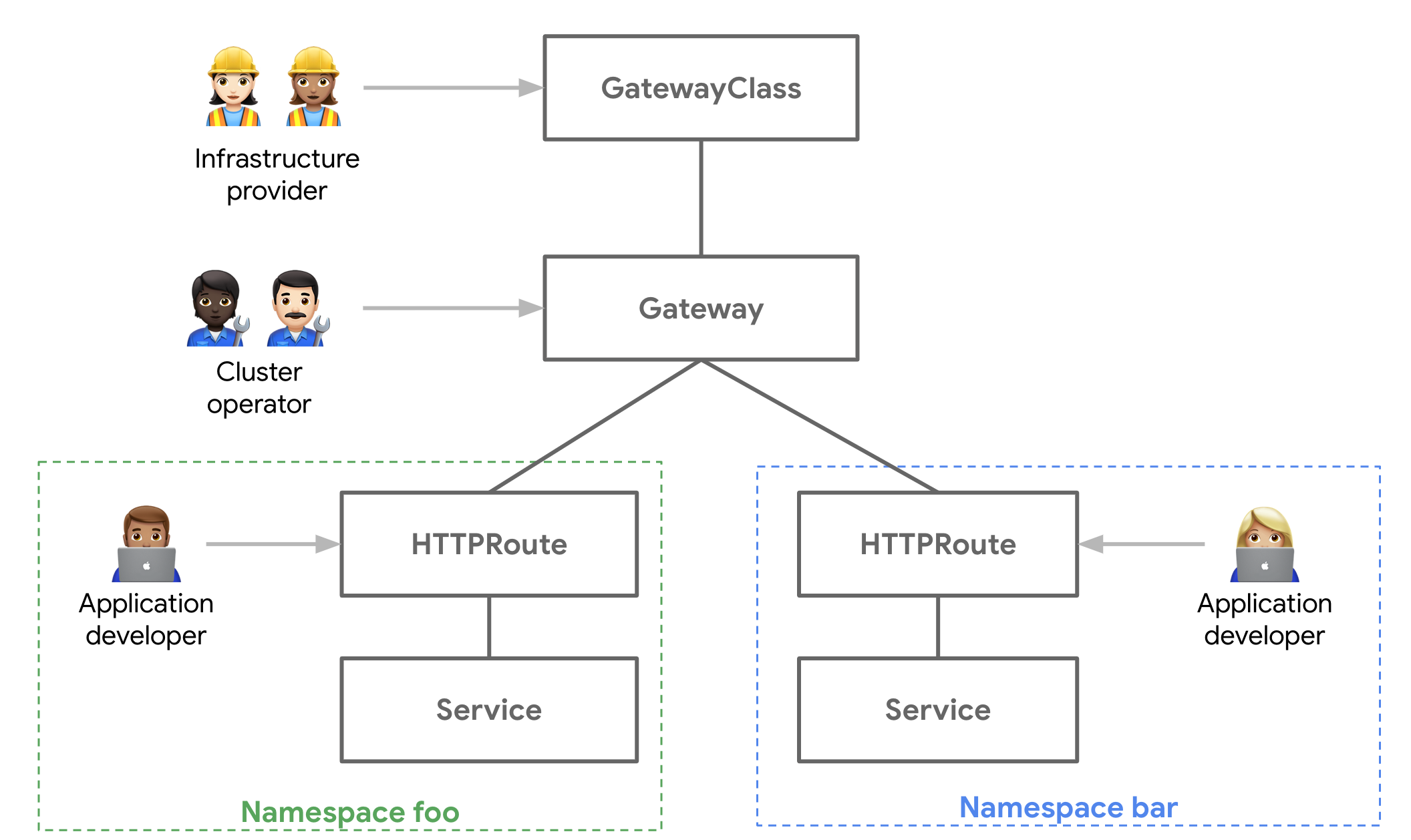
- En savoir plus : Evolving Kubernetes networking with the Gateway API
KUBERNETES : Stockage
Kubernetes : CSI
- Container Storage Interface
- CSI est une interface standard pour connecter Kubernetes à différents fournisseurs de stockage.
- Équivalent de CNI mais pour les volumes
- Avant Kubernetes 1.13, tous les drivers de volumes étaient in tree
- Le but de la séparation est de sortir du code du core de Kubernetes
- GA depuis Kubernetes 1.13
- Permet d'utiliser des solutions de stockage variées (cloud, locales, etc.) de manière transparente.
- Simplifie l'intégration de nouveaux systèmes de stockage.
Kubernetes : CSI
- La plupart des volumes supportés dans Kubernetes supportent maintenant CSI:
- Amazon EBS
- Google PD
- Cinder
- GlusterFS
- La liste exhaustive est disponible ici
- Drivers CSI: Chaque système de stockage nécessite un driver CSI spécifique pour s'intégrer à Kubernetes.
- Points de montage: Les drivers CSI créent des points de montage que Kubernetes peut ensuite attacher aux pods.
- Cycle de vie des volumes: Le CSI gère le cycle de vie complet des volumes (provisionnement, attachement, détachement, suppression).
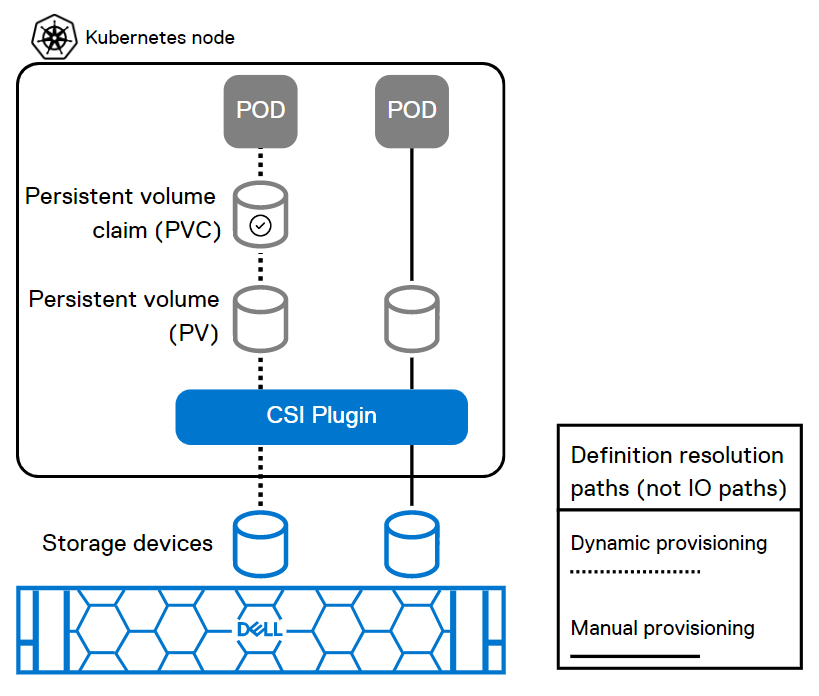
Kubernetes : Volumes
- Fournir du stockage persistent aux PODs
- Défini au niveau pod
- On le même cycle de vie que le pod
- Quand le pod est supprimé le volume aussi
- Les différents type de volumes sont implémentés comme des plugins
- Les comportement sous-jacents dépendent du backend
- Fonctionnent de la même façon que les volumes Docker pour les volumes hôte :
EmptyDir~= volumes dockerHostPath~= volumes hôte
Type de Volumes
- emptyDir
- hostPath
- gcePersistentDisk
- awsElasticBlockStore
- nfs
- iscsi
- fc (fibre channel)
- flocker
- glusterfs
- rbd
- cephfs
- secret
- persistentVolumeClaim
- downwardAPI
- projected
- azureFileVolume
- azureDisk
- vsphereVolume
- Quobyte
- PortworxVolume
- ScaleIO
- StorageOS
- local
Kubernetes : Volumes
- On déclare d'abord le volume et on l'affecte à un "service" (container) :
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
volumeMounts:
- name: redis-persistent-storage
mountPath: /data/redis
volumes:
- name: redis-persistent-storage
emptyDir: {}Kubernetes : Volumes
- Autre exemple
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
volumeMounts:
- name: redis-persistent-storage-host
mountPath: /data/redis
volumes:
- name: redis-persistent-storage-host
hostPath:
path: /mnt/data/redisType de stockage
Persistent Volume(PV) : Représentation de bas niveau d'un volume de stockage.Persistent Volume Claim(PVC) : binding entre un Pod et un Persistent Volume (PV).Storage Class: Permet de provionner dynamiquement d'un Persistent Volumes (PV).
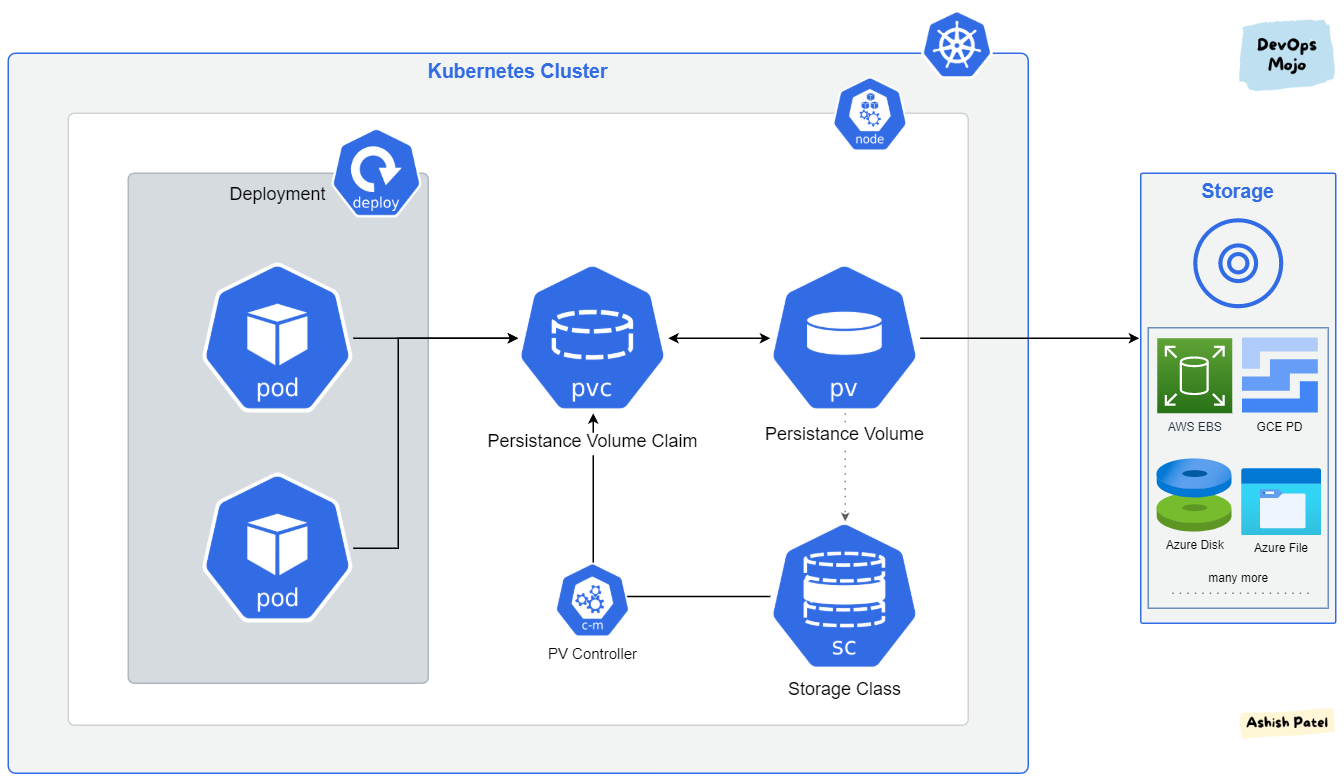
Kubernetes : Storage Class
- Permet de définir les différents types de stockage disponibles
- StorageClass permet le provisionnement dynamique des volumes persistants, lorsque PVC le réclame.
- Utilisé par les
Persistent Volumespour solliciter un espace de stockage au travers desPersistent Volume Claims - StorageClass utilise des provisionneurs spécifiques à la plate-forme de stockage ou au fournisseur de cloud pour donner à Kubernetes l'accès au stockage physique.
- Chaque backend de stockage a son propre provisionneur. Le backend de stockage est défini dans le composant StorageClass via l'attribut provisioner.
Kubernetes : Storage Class
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
zones: us-east-1d, us-east-1c
iopsPerGB: "10"Kubernetes : Storage Class
Autre exemple
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-premium
labels:
addonmanager.kubernetes.io/mode: EnsureExists
kubernetes.io/cluster-service: "true"
parameters:
cachingmode: ReadOnly
kind: Managed
storageaccounttype: Premium_LRS
provisioner: kubernetes.io/azure-disk
reclaimPolicy: Delete
volumeBindingMode: Immediate
allowVolumeExpansion: trueKubernetes : Storage Class
Autre exemple
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
annotations:
storageclass.kubernetes.io/is-default-class: "true"
name: local-path
provisioner: rancher.io/local-path
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumerKubernetes : PersistentVolume
- Composant de stockage dans le cluster kubernetes
- Stockage externe aux noeuds du cluster
- Cycle de vie d'indépendant du pod qui le consomme
- Peut être provisionné manuellement par un administrateur ou dynamiquement grâce une
StorageClass - Supporte différent mode d'accès
- RWO - read-write par un noeud unique
- ROX - read-only par plusieurs noeuds
- RWX - read-write par plusieurs noeuds
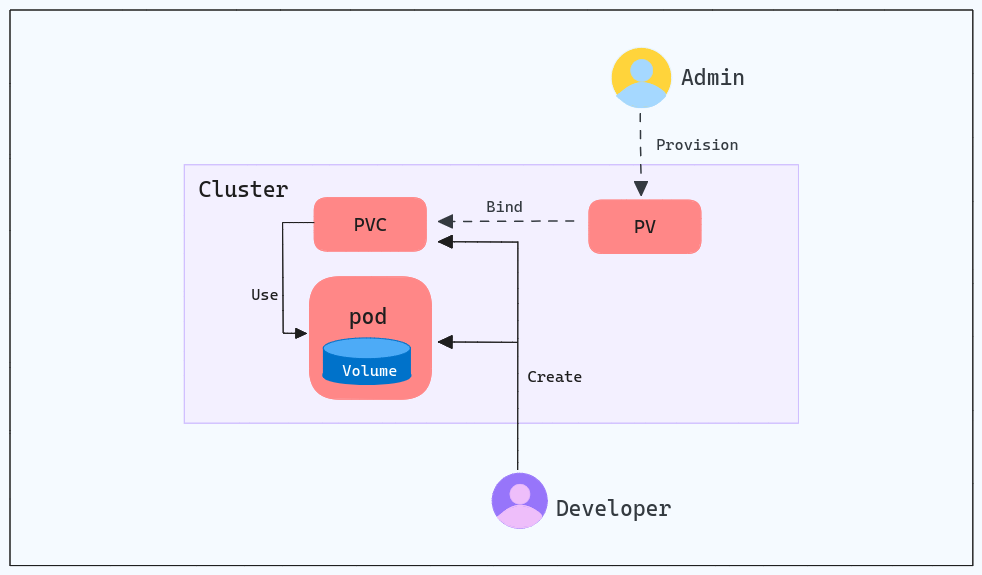
Kubernetes : PersistentVolume
apiVersion: v1
kind: PersistentVolume
metadata:
name: persistent-volume-1
spec:
storageClassName: slow
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/tmp/data"Reclaim Policy
- Les PV qui sont créés dynamiquement par une
StorageClassauront la politique de récupération spécifiée dans le champreclaimPolicyde la classe, qui peut êtreDeleteouRetain. Si aucun
reclaimPolicyn'est spécifié lors de la création d'un objetStorageClass, il sera par défautdelete.Les PV qui sont créés manuellement et gérés via une
StorageClassauront la politique de récupération qui leur a été attribuée lors de la création.La stratégie de récupération s'applique aux volumes persistants et non à la classe de stockage elle-même. Les PV et les PVC créés à l'aide de cette
StorageClasshériteront de la stratégie de récupération définie dansStorageClass.
Kubernetes : PersistentVolumeClaims
- Le PVC est un binding entre un
podet unPV. Le pod demande le volume via le PVC. - Le liage est géré automatiquement par Kubernetes.
- Ressource utilisée et vue comme une requête utilisateur pour solliciter du stockage persistant en définissant :
- une quantité de stockage
- un type d'accès
- un namespace pour le montage
- Offre aux PV une variété d'options en fonction du cas d'utilisation
- Kubernetes recherche un PV qui répond aux critères définis dans le PVC, et s'il y en a un, il fait correspondre la demande au PV.
- Utilisé par les
StatefulSetspour solliciter du stockage (Utilisation du champvolumeClaimTemplates) - Le PVC doit se trouver dans le même namespace que le pod. Pour chaque pod, un PVC effectue une demande de stockage dans un namespace.
- Les "Claim"" peuvent demander une taille et des modes d'accès spécifiques (par exemple, elles peuvent être montées ReadWriteOnce, ReadOnlyMany ou ReadWriteMany).
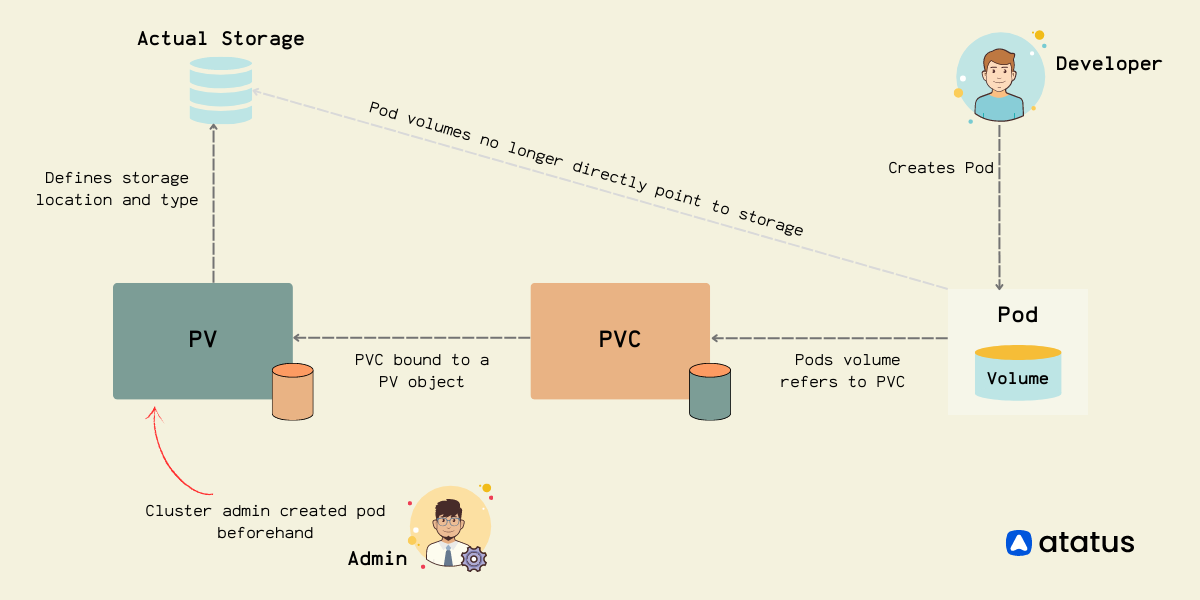
Kubernetes : PersistentVolumeClaims
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: storage-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: "slowl"
selector:
matchLabels:
release: "stable"
matchExpressions:
- {key: capacity, operator: In, values: [10Gi, 20Gi]}Kubernetes : PersistentVolumeClaims
Utilisation d'un PVC dans un pod
apiVersion: v1
kind: Pod
metadata:
name: myapp
spec:
containers:
- name: myapp
image: nginx
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: mywebsite
volumes:
- name: mywebsite
persistentVolumeClaim:
claimName: myclaimKubernetes : Provisionnement Dynamique
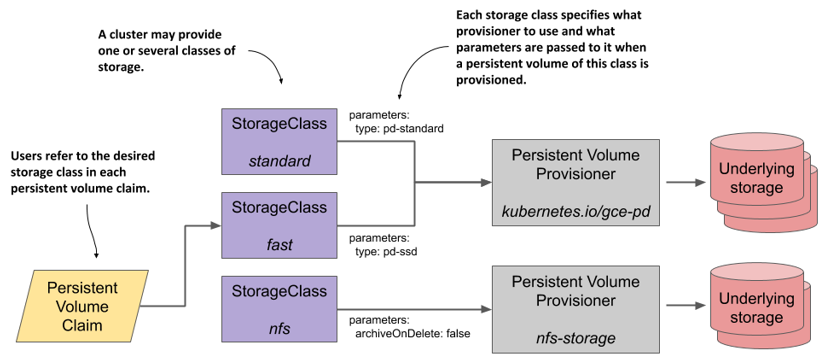
KUBERNETES : Gestion de la Configuration des Applications
Kubernetes : ConfigMaps
- Objet Kubernetes permettant stocker séparer les fichiers de configuration
- Il peut être créé d'un ensemble de valeurs ou d'un fichier ressource Kubernetes (YAML ou JSON)
- Un
ConfigMappeut être sollicité (utilisé) par plusieurspods - Limité à 1MiB de data
- Non sécurisé: Les données sont stockées en clair dans le cluster.
Kubernetes : ConfigMaps
- Exemple pour être utilisé comme fichier de configuration
apiVersion: v1
kind: ConfigMap
metadata:
name: redis-config
data:
redis-config: |
maxmemory 2mb
maxmemory-policy allkeys-lruKubernetes : ConfigMaps
- Exemple pour être utilisé dans des variables d'environnements
- Utilisation de clés valeurs individuelles
apiVersion: v1
kind: ConfigMap
metadata:
name: redis-env
data:
redis_host: "redis_svc"
redis_port: "6349"Kubernetes : ConfigMap environnement
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: k8s.gcr.io/busybox
command: [ "/bin/sh", "-c", "env" ]
env:
- name: REDIS_HOST
valueFrom:
configMapKeyRef:
name: redis-env
key: redis_host
- name: LOG_LEVEL
valueFrom:
configMapKeyRef:
name: env-config
key: log_level
restartPolicy: NeverKubernetes: ConfigMap volume
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: k8s.gcr.io/busybox
command: [ "/bin/sh", "-c", "ls /etc/config/" ]
volumeMounts:
- name: redis-conf-volume
mountPath: /etc/config
volumes:
- name: redis-conf-volume
configMap:
# Provide the name of the ConfigMap containing the files you want
# to add to the container
name: redis-config
restartPolicy: NeverAutres solution pour créer des ConfigMaps
- En utilisant le contenu complet d'un répertoire
kubectl create configmap my-config --from-file=./my/dir/path/- En utilisant le contenu d'un fichier d'un répertoire
kubectl create configmap my-config --from-file=./my/dir/path/myfile.txt- En utilisant des clés valeurs
kubectl create configmap my-config --from-literal=key1=value1 --from-literal=key2=value2Kubernetes : Secrets
- Objet Kubernetes de type
secretutilisé pour stocker des informations sensibles comme les mots de passe, les tokens, les clés SSH... - Similaire à un
ConfigMap, à la seule différence que le contenu des entrées présentes dans le champdatasont encodés en base64. - Il est possible de directement créer un
Secretspécifique à l'authentification sur un registre Docker privé. - Il est possible de directement créer un
Secretà partir d'un compte utilisateur et d'un mot de passe. - Limité à 1MiB de data
Kubernets : Secrets
- S'utilisent de la même façon que les ConfigMap
- La seule différence est le stockage en base64
- 3 types de secrets:
Generic: valeurs arbitraire comme dans une ConfigMaptls: certificat et clé pour utilisation avec un serveur webdocker-registry: utilisé en tant queimagePullSecretpar un pod pour pouvoir pull les images d'une registry privée
Kubernetes : Secrets
$ kubectl create secret docker-registry mydockerhubsecret \
--docker-username="employeeusername" --docker-password="employeepassword" \
--docker-email="employee.email@organization.com"kubectl create secret generic dev-db-secret --from-literal=username=devuser --from-literal=password='S!B\*d$zDsb'Kubernetes : Secrets
apiVersion: v1
kind: Secret
metadata:
creationTimestamp: 2016-01-22T18:41:56Z
name: mysecret
namespace: default
resourceVersion: "164619"
uid: cfee02d6-c137-11e5-8d73-42010af00002
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2RmKUBERNETES : Gestion des Ressources
Pods resources : requests et limits
- Permettent de gérer l'allocation de ressources au sein d'un cluster
- Par défaut, un pod/container sans request/limits est en best effort
- Request: allocation minimum garantie (réservation)
- Limit: allocation maximum (limite)
Se base sur le CPU et la RAM
- Relation entre requests et limits
- Requests <= Limits: La valeur de la request doit toujours être inférieure ou égale à celle de la limit.
- Qualité de service (QoS): Les valeurs de requests et limits définissent le niveau de QoS d'un pod (BestEffort, Burstable, Guaranteed).
QoS
- BestEffort :
- Pas de limites ni de requests définies: Le pod peut consommer autant de ressources que disponibles, mais il n'a aucune garantie.
- Conséquences: Le pod peut être évincé à tout moment si les ressources du nœud sont insuffisantes, ce qui peut entraîner des interruptions de service.
- Burstable :
- Requests définies: Le pod a une garantie minimale de ressources (requests).
- Pas de limites strictes: Le pod peut dépasser ses requests si les ressources sont disponibles, mais il peut être évincé si d'autres pods Guaranteed ont besoin de ressources.
- Conséquences: Le pod bénéficie d'une certaine priorité, mais il peut être impacté par les besoins des pods Guaranteed.
- Guaranteed :
- Requests et limites définies: Le pod a une garantie minimale de ressources (requests) et une limite maximale (limits).
- Priorité élevée: Le pod a la plus haute priorité et ne peut pas être évincé tant qu'il respecte ses limites.
- Conséquences: Le pod bénéficie d'une garantie de ressources stable, ce qui est idéal pour les applications critiques.
Exemple concret :
Un nœud Kubernetes avec 4 cœurs CPU.
- Pod BestEffort: Il peut utiliser 0, 1, 2, 3 ou 4 cœurs, selon la disponibilité.
- Pod Burstable (requests: 2 cœurs, pas de limits): Il est garanti d'avoir au moins 2 cœurs, mais il peut en utiliser jusqu'à 4 s'ils sont disponibles. Si un pod Guaranteed a besoin de 2 cœurs, le pod Burstable peut en perdre 2.
- Pod Guaranteed (requests: 2 cœurs, limits: 2 cœurs): Il a toujours 2 cœurs garantis et ne peut pas en utiliser plus.Pods resources : CPU
- 1 CPU est globalement équivalent à un cœur
- L'allocation se fait par fraction de CPU:
1: 1 vCPU entier100m: 0.1 vCPU0.5: 1/2 vCPU- Lorsqu'un conteneur atteint la limite CPU, celui ci est throttled
Pods resources : RAM
- L'allocation se fait en unité de RAM:
M: en base 10Mi: en base 2- Lorsqu'un conteneur atteint la limite RAM, celui ci est OOMKilled
Pods resources : requests et limits
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: db
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "password"
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: wp
image: wordpress
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"LimitRanges
- l'objet
LimitRangepermet de définir les valeurs minimales et maximales des ressources utilisées par les containers et les pods pour les requests et limits de CPU, de mémoire et de stockage - l'objet
LimitRanges'applique au niveau dunamespace - les limites spécifiées s'appliquent à chaque pod/container créé dans le
namespace - le
LimitRangene limite pas le nombre total de ressources disponibles dans le namespace
LimitRanges
apiVersion: v1
kind: LimitRange
metadata:
name: limit-example
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256 Mi
type: ContainerResourceQuotas
- un objet
ResourceQuotalimite le total des ressources de calcul consommées par les pods ainsi que le total de l'espace de stockage consommé par lesPersistentVolumeClaimsdans un namespace - il permet aussi de limiter le nombre de
pods,PVC, réplicas, services et autres objets qui peuvent être créés dans unnamespace
ResourceQuotas
apiVersion: v1
kind: ResourceQuota
metadata:
name: cpu-and-ram
spec:
hard:
requests.cpu: 400m
requests.memory: 200Mi
limits.cpu: 600m
limits.memory: 500MiResourceQuotas
apiVersion: v1
kind: ResourceQuota
metadata:
name: quota-for-objects
spec:
hard:
pods: 200
services: 10
secrets: 20
configmaps: 40
persistentvolumeclaims: 40
services.nodeports: 0
services.loadbalancers: 0
count/roles.rbac.authorization.k8s.io: 10ResourceQuotas
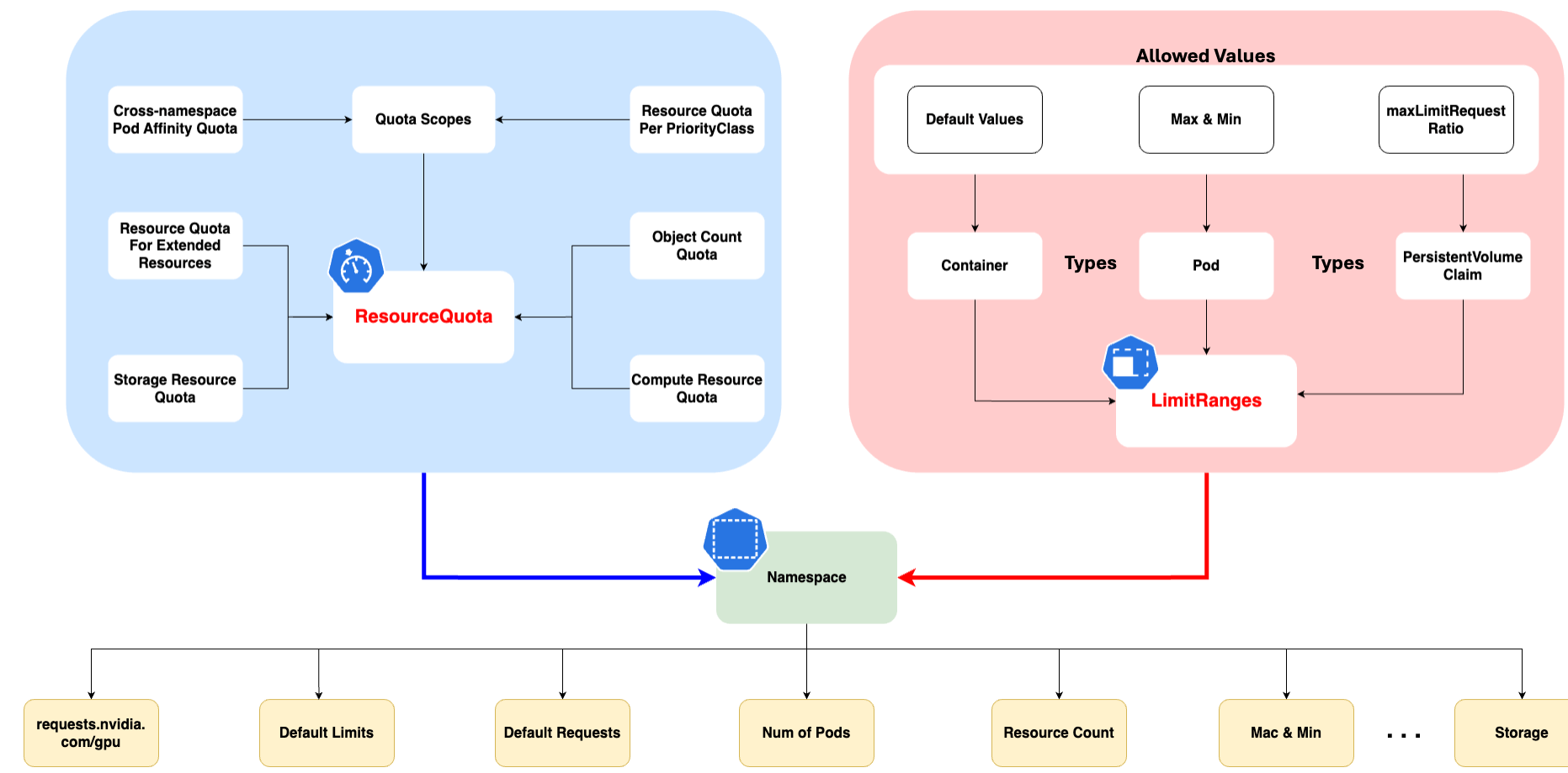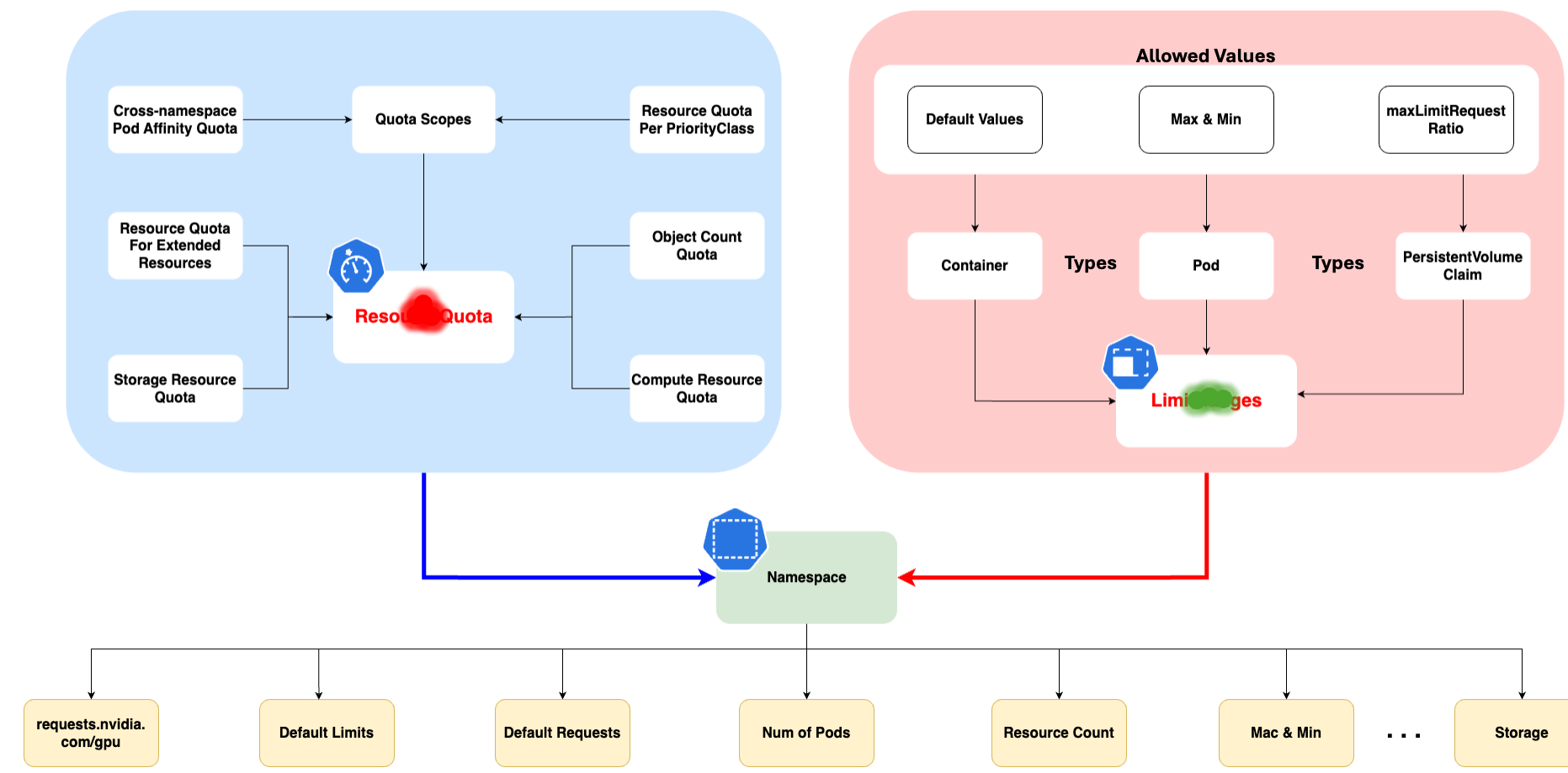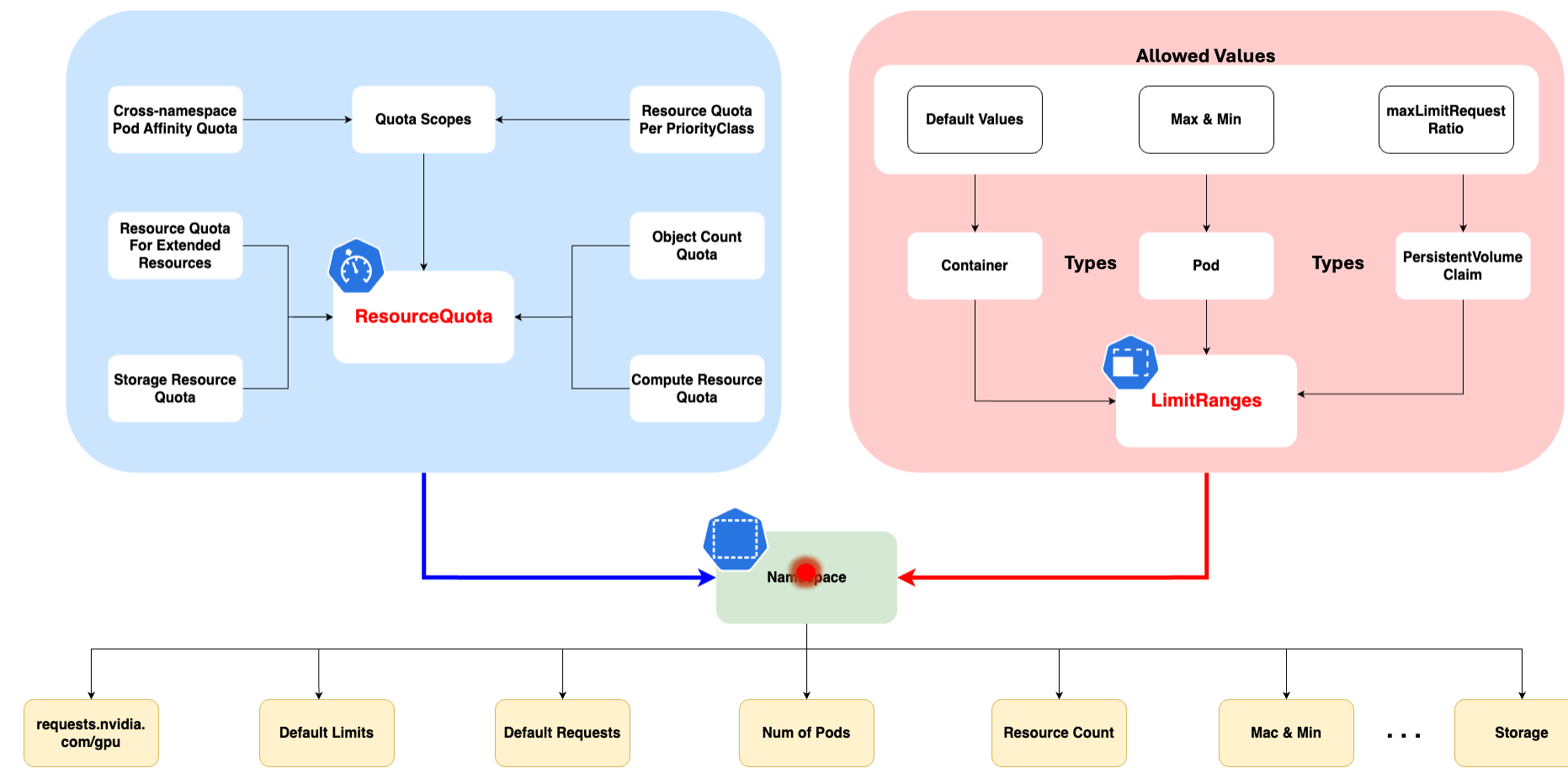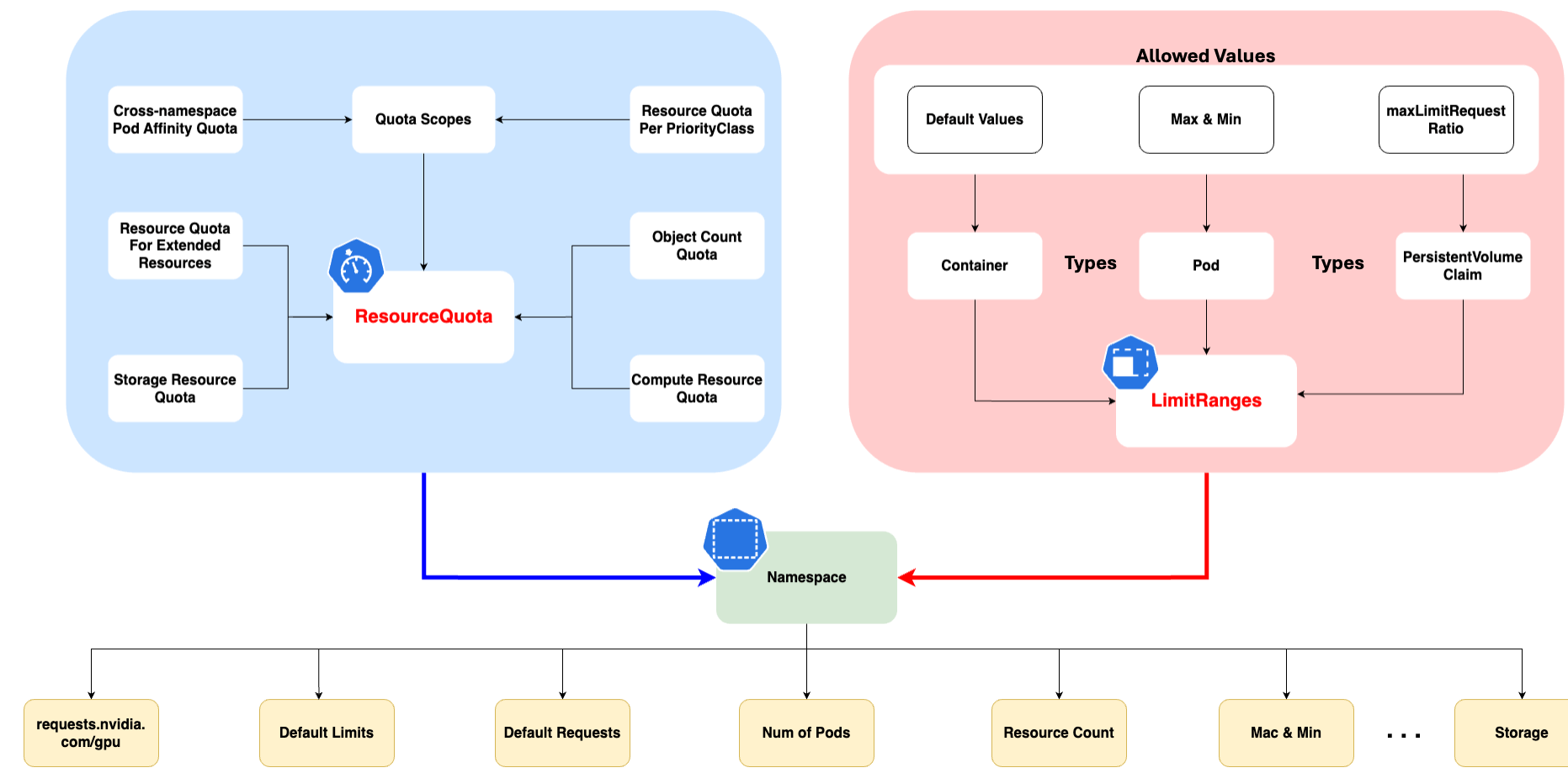
KUBERNETES : Observabilité et Monitoring
Sondes : Readiness, Liveness et StartUP
- Permettent à Kubernetes de sonder l'état d'un pod et d'agir en conséquence
- 3 types de sonde : Readiness, Liveness, StartUp
- 4 manières de sonder :
- TCP : ping TCP sur un port donné
- HTTP: http GET sur une url donnée
- Command: Exécute une commande dans le conteneur
- grpc : standard GRPC Health Checking Protocol
Sondes : Startup
- Disponible en bêta à partir de la version 1.18
- Utiles pour les applications qui ont un démarrage lent
- Permet de ne pas augmenter les
initialDelaySecondsdes Readiness et Liveness - Elle sert à savoir quand l'application est prête
- Les 3 sondes combinées permet de gérer très finement la disponibilité de l'application
Sondes : Readiness
- Gère le trafic à destination du pod
- Un pod avec une sonde readiness NotReady ne reçoit aucun trafic
- Permet d'attendre que le service dans le conteneur soit prêt avant de router du trafic
- Un pod Ready est ensuite enregistrer dans les endpoints du service associé
Sondes : Liveness
- Gère le redémarrage du conteneur en cas d'incident
- Un pod avec une sonde liveness sans succès est redémarré au bout d'un intervalle défini
- Permet de redémarrer automatiquement les pods "tombés" en erreur
Différents types de sondes : httpGet
- Effectuer une requête HTTP GET vers le conteneur
- La requête sera effectuée par la Kubelet (ne nécessite pas de binaires supplémentaires dans l'image du conteneur)
- Le paramètre port doit être spécifié
- Les paramètres
pathethttpHeaderssupplémentaires peuvent être spécifiés de manière optionnelle - Kubernetes utilise le code de statut HTTP de la réponse :
- 200-399 = succès
- tout autre code = échec
Différents types de sondes : exec
- Exécute un programme arbitraire à l'intérieur du conteneur (comme avec kubectl exec ou docker exec)
- Le programme doit être disponible dans l'image du conteneur
- Kubernetes utilise le code de sortie du programme (convention UNIX standard : 0 = succès, toute autre valeur = échec)
Différents types de sondes : tcpSocket
- Kubernetes vérifie si le port TCP indiqué accepte des connexions
- Il n'y a pas de vérification supplémentaire 🫥 Il est tout à fait possible qu'un processus soit défaillant, tout en continuant à accepter des connexions TCP !
Différents types de sondes : grpc
- Disponible en version bêta depuis Kubernetes 1.24
- Exploite le protocole standard GRPC Health Checking
apiVersion: v1
kind: Pod
metadata:
name: test-grpc
spec:
containers:
- name: agnhost
image: registry.k8s.io/e2e-test-images/agnhost:2.35
command: ["/agnhost", "grpc-health-checking"]
ports:
- containerPort: 5000
- containerPort: 8080
readinessProbe:
grpc:
port: 5000Plus d'informations : https://kubernetes.io/blog/2022/05/13/grpc-probes-now-in-beta/
Sondes : Exemples
aapiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
containers:
- name: my-app-container
image: my-image
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Authorization
value: Bearer my-token
initialDelaySeconds: 15
periodSeconds: 5
timeoutSeconds: 1
failureThreshold: 3
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 2
failureThreshold: 5
startupProbe:
exec:
command:
- cat /etc/nginx/nginx.conf
initialDelaySeconds: 10
timeoutSeconds: 5Sondes : gérer les délais et seuils
initialDelaySeconds
- Une probe peut avoir un paramètre
initialDelaySeconds(défaut : 0). - Kubernetes attendra ce délai avant d'exécuter le probe pour la première fois.
- Il est généralement préférable d'utiliser un startupProbe à la place. (mais ce paramètre existait avant l'implémentation des startup probes)
- Une probe peut avoir un paramètre
temps et seuils
- Les probes sont exécutées à intervalles de periodSeconds (défaut : 10).
- Le délai d'expiration d'un probe est défini avec timeoutSeconds (défaut : 1).
- Si une probe prend plus de temps que cela, il est considéré comme un ÉCHEC.
- Pour les probes de liveness et de startup, cela entraîne la terminaison et le redémarrage du conteneur.
- Une probe est considérée comme réussi après successThreshold succès (défaut : 1).
- Une probe est considérée comme en échec après failureThreshold échecs (défaut : 3).
- Tous ces paramètres peuvent être définis indépendamment pour chaque probe.
Sondes : Startup Probe Bonnes pratiques
Si une startupProbe échoue, Kubernetes redémarre le conteneur correspondant.
En d'autres termes : avec les paramètres par défaut, le conteneur doit démarrer en 30 secondes. (failureThreshold × periodSeconds)
C'est pourquoi il faut presque toujours ajuster les paramètres d'une startupProbe. (spécifiquement, son failureThreshold)
Parfois, il est plus facile d'utiliser une readinessProbe à la place.(voir la prochaine diapositive pour plus de détails)
Sondes : Liveness Probe Bonnes pratiques
N'utilisez pas de probes de liveness pour des problèmes qui ne peuvent pas être résolus par un redémarrage. Sinon, les pods redémarrent sans raison, créant une charge inutile.
Ne dépendez pas d'autres services au sein d'une probe de liveness. Sinon, Possibilités d'échecs en cascade.(exemple : probe de liveness d'un serveur web qui effectue des requêtes vers une base de données)Assurez-vous que les probes de liveness répondent rapidement.
Le délai d'expiration par défaut des probes est de 1 seconde (cela peut être ajusté).
Si la probe prend plus de temps que cela, il finira par provoquer un redémarrage.
Une startupProbe nécessite généralement de modifier le
failureThreshold.Une
startupProbenécessite généralement également unereadinessProbe.Une seule
readinessProbepeut remplir les deux rôles.
Sondes : Readiness Probe Bonnes pratiques
- Presque toujours bénéfique.
- Sauf pour :
- les service web qui n'ont pas de route dédiée "health" ou "ping".
- toutes les requêtes sont "coûteuses" (par exemple, nombreux appels externes).
Sondes : Exemple Kubernetes API
L'API Kubernetes inclut également des points de terminaison de contrôle d'état : healthz (obsolète), readyz, livez.
kubectl get --raw='/readyz?verbose'Sondes : Exemple Kubernetes API
Point de terminaison readyz
[+]ping ok
[+]log ok
[+]etcd ok
[+]informer-sync ok
[+]poststarthook/start-kube-apiserver-admission-initializer ok
[+]poststarthook/generic-apiserver-start-informers ok
[+]poststarthook/priority-and-fairness-config-consumer ok
[+]poststarthook/priority-and-fairness-filter ok
[+]poststarthook/start-apiextensions-informers ok
[+]poststarthook/start-apiextensions-controllers ok
[+]poststarthook/crd-informer-synced ok
[+]poststarthook/bootstrap-controller ok
[+]poststarthook/rbac/bootstrap-roles ok
[+]poststarthook/scheduling/bootstrap-system-priority-classes ok
[+]poststarthook/priority-and-fairness-config-producer ok
[+]poststarthook/start-cluster-authentication-info-controller ok
[+]poststarthook/aggregator-reload-proxy-client-cert ok
[+]poststarthook/start-kube-aggregator-informers ok
[+]poststarthook/apiservice-registration-controller ok
[+]poststarthook/apiservice-status-available-controller ok
[+]poststarthook/kube-apiserver-autoregistration ok
[+]autoregister-completion ok
[+]poststarthook/apiservice-openapi-controller ok
[+]shutdown ok
readyz check passedSondes : Exemple Kubernetes API
Point de terminaison livez
kubectl get --raw='/livez?verbose'Sondes : Exemple Kubernetes API
+]ping ok
[+]log ok
[+]etcd ok
[+]poststarthook/start-kube-apiserver-admission-initializer ok
[+]poststarthook/generic-apiserver-start-informers ok
[+]poststarthook/priority-and-fairness-config-consumer ok
[+]poststarthook/priority-and-fairness-filter ok
[+]poststarthook/start-apiextensions-informers ok
[+]poststarthook/start-apiextensions-controllers ok
[+]poststarthook/crd-informer-synced ok
[+]poststarthook/bootstrap-controller ok
[+]poststarthook/rbac/bootstrap-roles ok
[+]poststarthook/scheduling/bootstrap-system-priority-classes ok
[+]poststarthook/priority-and-fairness-config-producer ok
[+]poststarthook/start-cluster-authentication-info-controller ok
[+]poststarthook/aggregator-reload-proxy-client-cert ok
[+]poststarthook/start-kube-aggregator-informers ok
[+]poststarthook/apiservice-registration-controller ok
[+]poststarthook/apiservice-status-available-controller ok
[+]poststarthook/kube-apiserver-autoregistration ok
[+]autoregister-completion ok
[+]poststarthook/apiservice-openapi-controller ok
livez check passedKUBERNETES : Gestion des placements de pods
Scheduling manuel
Taints et Tolerations
Un nœud avec un taint empêche l'exécution sur lui-même des pods qui ne tolèrent pas ce taint
- Les taints et tolerations fonctionnent ensemble
- Les taints sont appliqués aux nœuds
- Les tolerations sont décrites aux niveau des pods
- On peut mettre plusieurs taints sur un nœuds (il faudra que le pod tolère tous ces taints)
- Les taints sont définis ainsi :
key=value:Effect
Taints et Tolerations : Champ "Effect"
Ce champ peut avoir 3 valeurs : NoSchedule, PreferNoSchedule, NoExecute
- NoSchedule : Contrainte forte, seuls les pods supportant le taint pourront s'exécuter sur le nœud.
- PreferNoSchedule: Contrainte faible, le scheduler de kubernetes évitera de placer un pod qui ne tolère pas ce taint sur le nœud, mais pourra le faire si besoin
- NoExecute : Contrainte forte, les pods seront expulsés du nœud / ne pourront pas s'exécuter sur le nœuds
Taints et Tolerations : Operateur
- Par valeur par défaut est
Equal(key=value:Effect) - Mais peut avoir aussi comme valeur
Exist(keyExist:Effect)
Taints et Tolerations : Utilisation des taints
En ligne de commande
- Ajouter un taint
kubectl taint nodes THENODE special=true:NoExecutekubectl taint node worker-0 node-role.kubernetes.io/master="":NoSchedulekubectl taint node worker-2 test:NoSchedule
- Supprimer un taint
kubectl taint nodes THENODE special=true:NoExecute-kubectl taint node worker-0 node-role.kubernetes.io/master-kubectl taint node worker-2 test:NoSchedule-
- Lister les tains d'un nœud
kubectl get nodes THENODE -o jsonpath="{.spec.taints}"[{"effect":"NoSchedule","key":"node-role.kubernetes.io/master"}]
Taints et Tolerations : Utilisation des tolerations
Les tolerations peuvent être décrites au niveau des pods ou au niveau des templates de pods dans les replicaset, daemonset, statefulset et deployment.
Ces tolerations permettront aux pods de s'exécuter sur les nœuds qui ont le taint correspondant.
Taints et Tolerations : Exemples
- Quand il n'y a pas de valeur (value) dans le taint
apiVersion: v1
kind: Pod
metadata:
...
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoScheduleTaints et Tolerations : Exemples (suite)
- Quand il y a une valeur (value)
apiVersion: v1
kind: Pod
metadata:
...
spec:
tolerations:
- key: special
value: "true"
effect: NoExecute
Operator: EqualTaints et Tolerations : Cas particulier
Une clé vide avec un opérateur Exist fera en sorte que le pod s'exécutera sur tous les nœuds quelque soit leurs taints
exemple :
tolerations:
- operator: "Exists"nodeSelector
- Champs clé valeur au niveau des podSpecs
- Pour que le pod puisse s'exécuter il faut que le nœud ait l'ensemble des labels correspondants
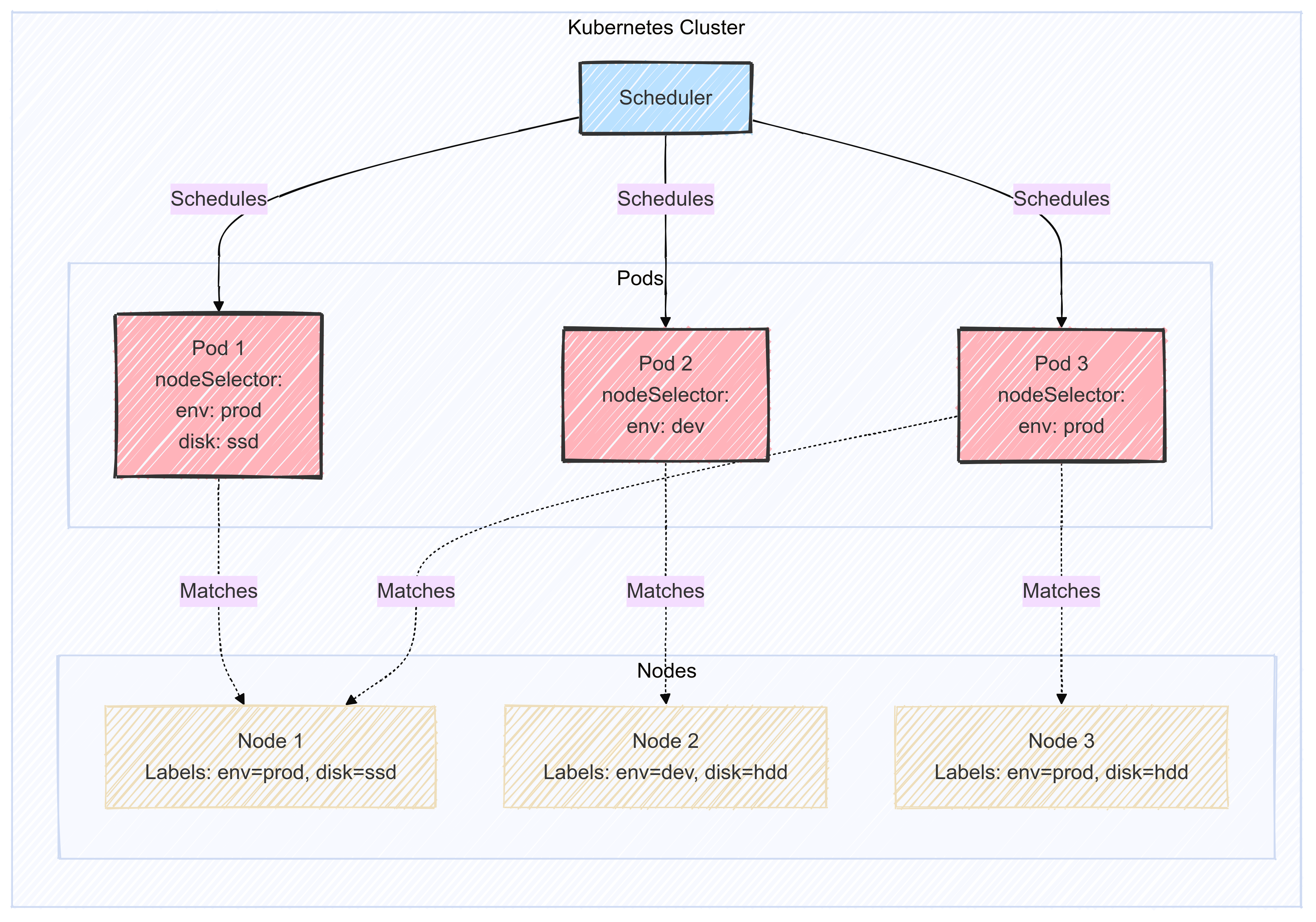
nodeSelector exemple
Exemples
- Pose du label sur un nœud
kubectl label nodes <node-name> <label-key>=<label-value>- ex:
kubectl label nodes worker-0 disktype=ssd
- Utilisation dans un pod
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeSelector:
disktype: ssdAffinité / Anti-affinité
Ce système permet de gérer très finement les règles de placement des pods en regard de la simplicité du nodeSelector
- Le langage permettant d'exprimer les affinités / anti-affinités est riche de possibilités
- Possibilité de d'écrire des préférences
soft(pod déployé malgré tout) ouhard(pod déployé uniquement si les règles sont respectées) - Contraintes dépendantes de labels présents dans d'autres pods
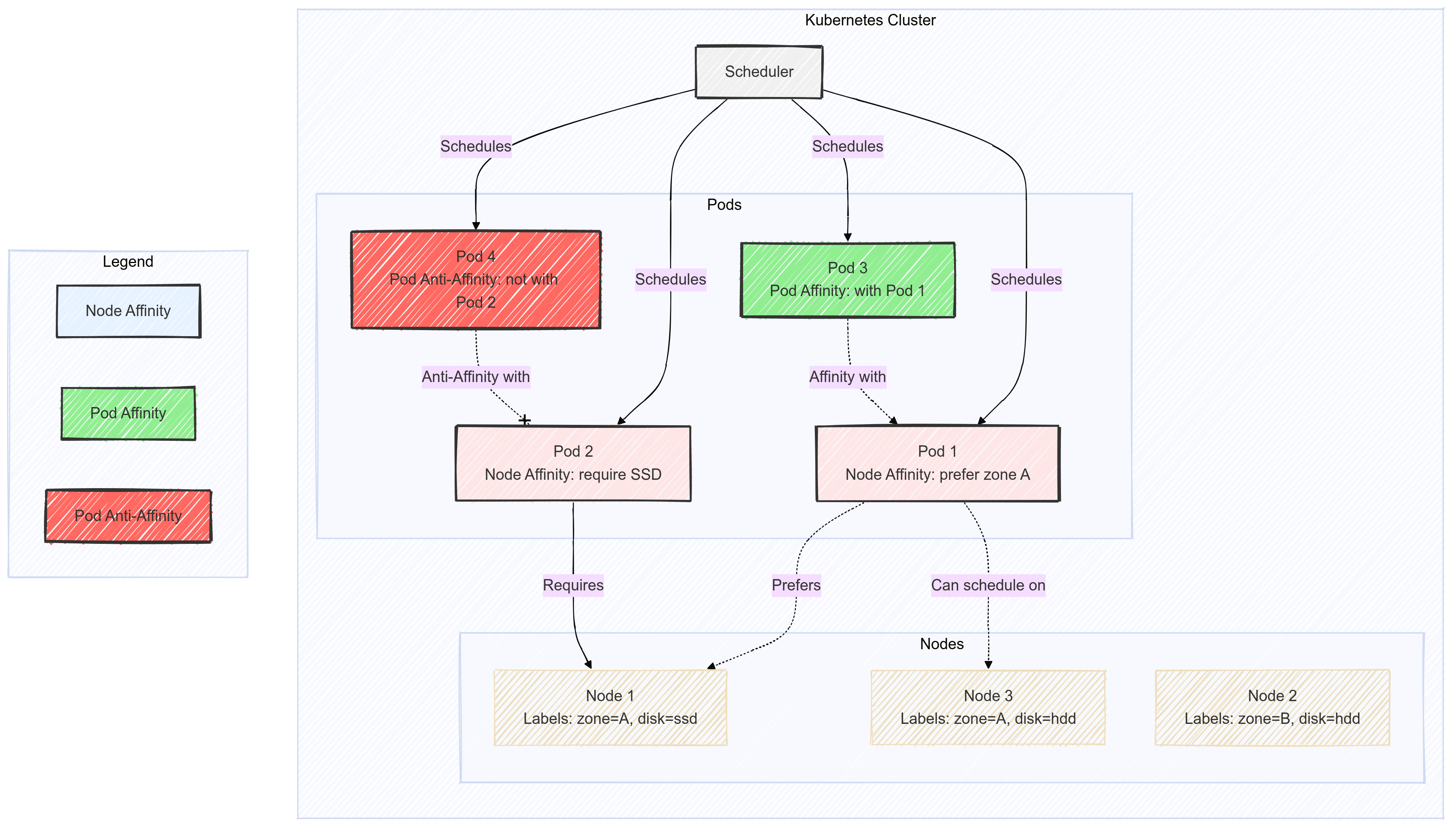
Node Affinity
- Égal conceptuellement au nodeSelector, mais avec la possibilité de faire du soft (should) ou hard (must)
- Soft :
preferredDuringSchedulingIgnoredDuringExecution - Hard :
requiredDuringSchedulingIgnoredDuringExecution
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In # (NotIn, Exists, DoesNotExist, Gt, Lt)
values:
- e2e-az1
- e2e-az2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In # (NotIn, Exists, DoesNotExist, Gt, Lt)
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0Un autre exemple
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0Pod Affinity
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0Pod anti-Affinity
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: k8s.gcr.io/pause:2.0KUBERNETES : logging et monitoring
Monitoring du cluster
- Le monitoring est nécessaire pour connaitre l'utilisation des ressources du cluster (CPU, RAM, Stockage, etc)
- Kubernetes n'intègre pas nativement de solution de monitoring
- Il existe des solutions open source telles que: Metric-Server, Prometheus, Elastic Stack
- Et des solutions propriétaires: Datadog, Dynatrace
Monitoring du cluster
- Il est recommandé d'avoir un server de métrique sur chaque cluster
- Les métriques sont récupérés, stockés et peuvent être consultés suivant la solution de monitoring utilisée.
- Un composant du Kubelet appelé cAdvisor récupère les métriques des pods sur chaque noeud
Monitoring du cluster
- Les performances des pods et des noeuds peuvent être affichées avec la commande
kubectl top podsetkubectl top nodes
$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
gke-cka-pool1-8e771340-lzju 86m 4% 736Mi 13%
gke-cka-pool1-f884d89f-pnbx 155m 8% 811Mi 14%$ kubectl -n lab top pods
NAME CPU(cores) MEMORY(bytes)
lab-middleware-c46cd576f-5vltl 1m 40Mi
lab-middleware-c46cd576f-7zckz 1m 43MiLogging
- Tout comme docker, Kubernetes permet d'afficher les logs générés par les applications avec la commande
kubectl logs - L'option
-fpermet de diffusion en direct des logs - Pour les pods multi-conteneurs, il est nécessaire de spécifier le conteneur dont on veut visualiser les logs
Logging
$ kubectl -n lab get pods
NAME READY STATUS RESTARTS AGE
lab-middleware-c46cd576f-5vltl 1/1 Running 0 17d
lab-middleware-c46cd576f-7zckz 1/1 Running 0 17d$ kubectl -n lab logs lab-middleware-c46cd576f-5vltl
info: serving app on http://0.0.0.0:3333
[bugsnag] Loaded!
[bugsnag] Bugsnag.start() was called more than once. Ignoring.
[bugsnag] Bugsnag.start() was called more than once. Ignoring.
[bugsnag] Bugsnag.start() was called more than once. Ignoring.KUBERNETES : Stratégie de mise à jour des Applications
Stratégie
Voici quelques stratégies de mise à jour des applications
- RollingUpdate simple Déploiement
- Canary Déploiement
- Blue-Green Déploiement
Rolling Update
Caractéristiques du RollingUpdate :
- Mise à jour progressive :
- Les pods sont mis à jour un par un ou par petits lots, plutôt que tous en même temps.
- Cela permet de minimiser les temps d'arrêt et de garantir que le service reste disponible pendant la mise à jour.
- Paramètres configurables :
- maxUnavailable : Définit le nombre maximum de pods qui peuvent être indisponibles pendant la mise à jour. Par exemple, maxUnavailable: 1 signifie qu'au maximum un pod peut être hors ligne à tout moment pendant la mise à jour.
- maxSurge : Définit le nombre maximum de pods supplémentaires qui peuvent être créés au-delà du nombre souhaité de pods pendant la mise à jour. Par exemple, maxSurge: 1 signifie qu'un pod supplémentaire peut être créé pendant la mise à jour.
- Maintien de la disponibilité :
- Le déploiement RollingUpdate garantit que certaines instances de l'application restent disponibles pour traiter les requêtes pendant la mise à jour.
- Cela réduit le risque de temps d'arrêt et améliore l'expérience utilisateur.
- Facilité de retour en arrière :
- Si un problème est détecté avec la nouvelle version, Kubernetes permet de revenir facilement à la version précédente des pods.
- Vous pouvez utiliser la commande kubectl rollout undo pour revenir à une version antérieure du déploiement.
- Surveillance et gestion des erreurs :
- Kubernetes surveille l'état des pods pendant la mise à jour. Si un pod ne parvient pas à démarrer ou à devenir sain, Kubernetes arrêtera la mise à jour et conservera les pods en cours d'exécution.
- Vous pouvez surveiller la progression de la mise à jour avec la commande kubectl rollout status.
- Compatibilité avec les applications sans état :
- La stratégie RollingUpdate est particulièrement bien adaptée aux applications sans état où les instances de pod sont interchangeables.
- Pour les applications avec état, des stratégies supplémentaires peuvent être nécessaires pour gérer les états et les données.
Rolling Update
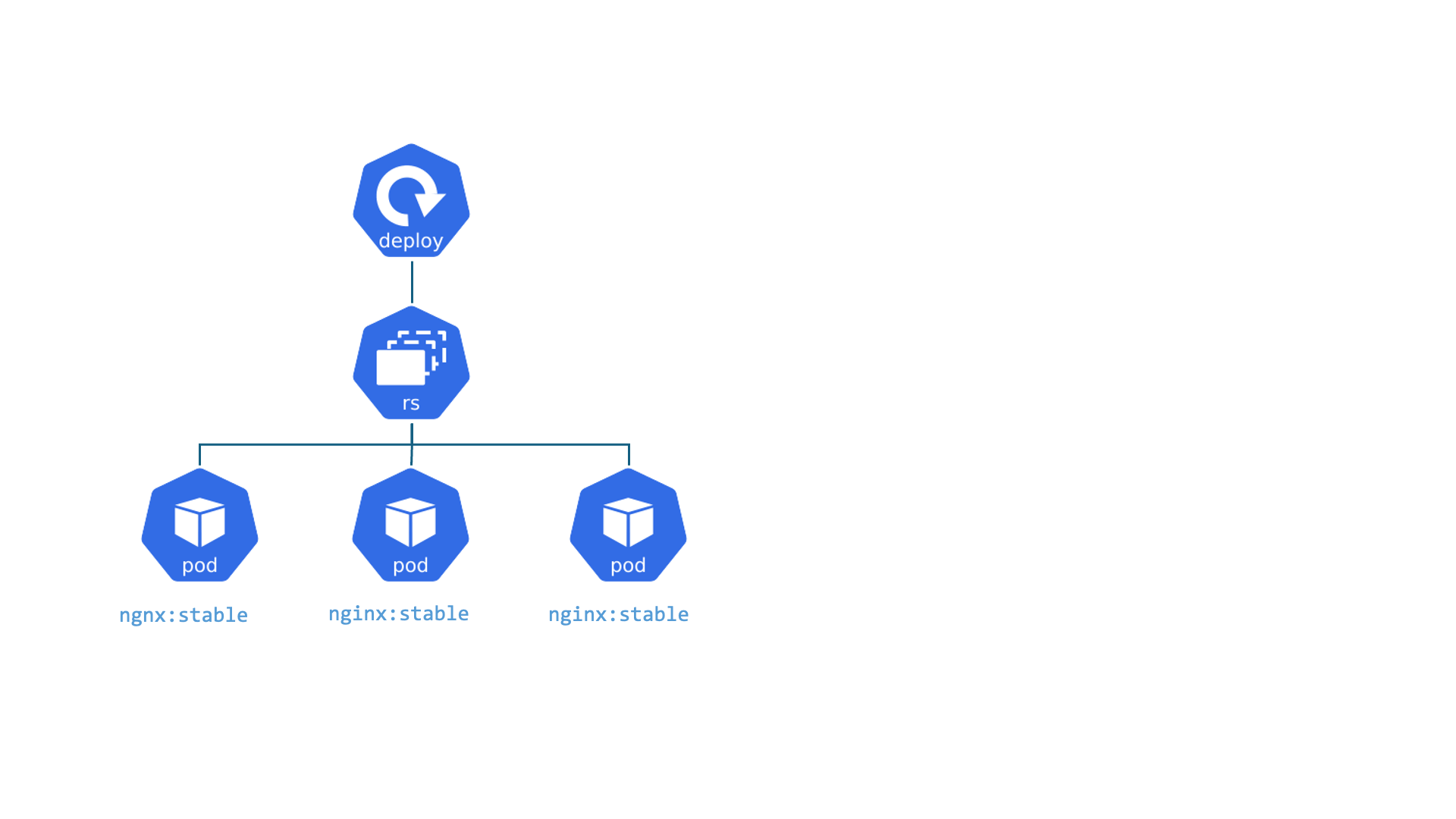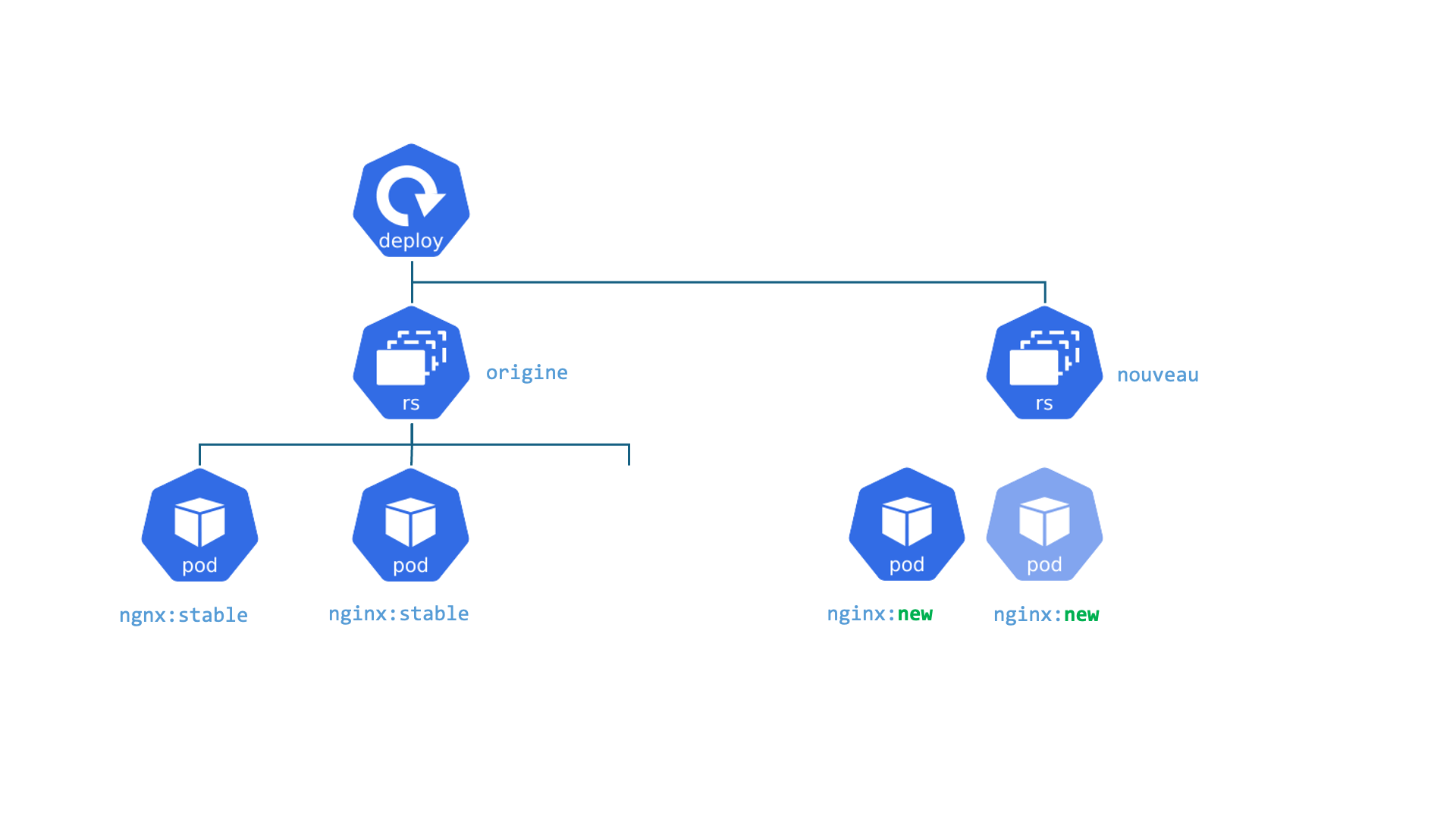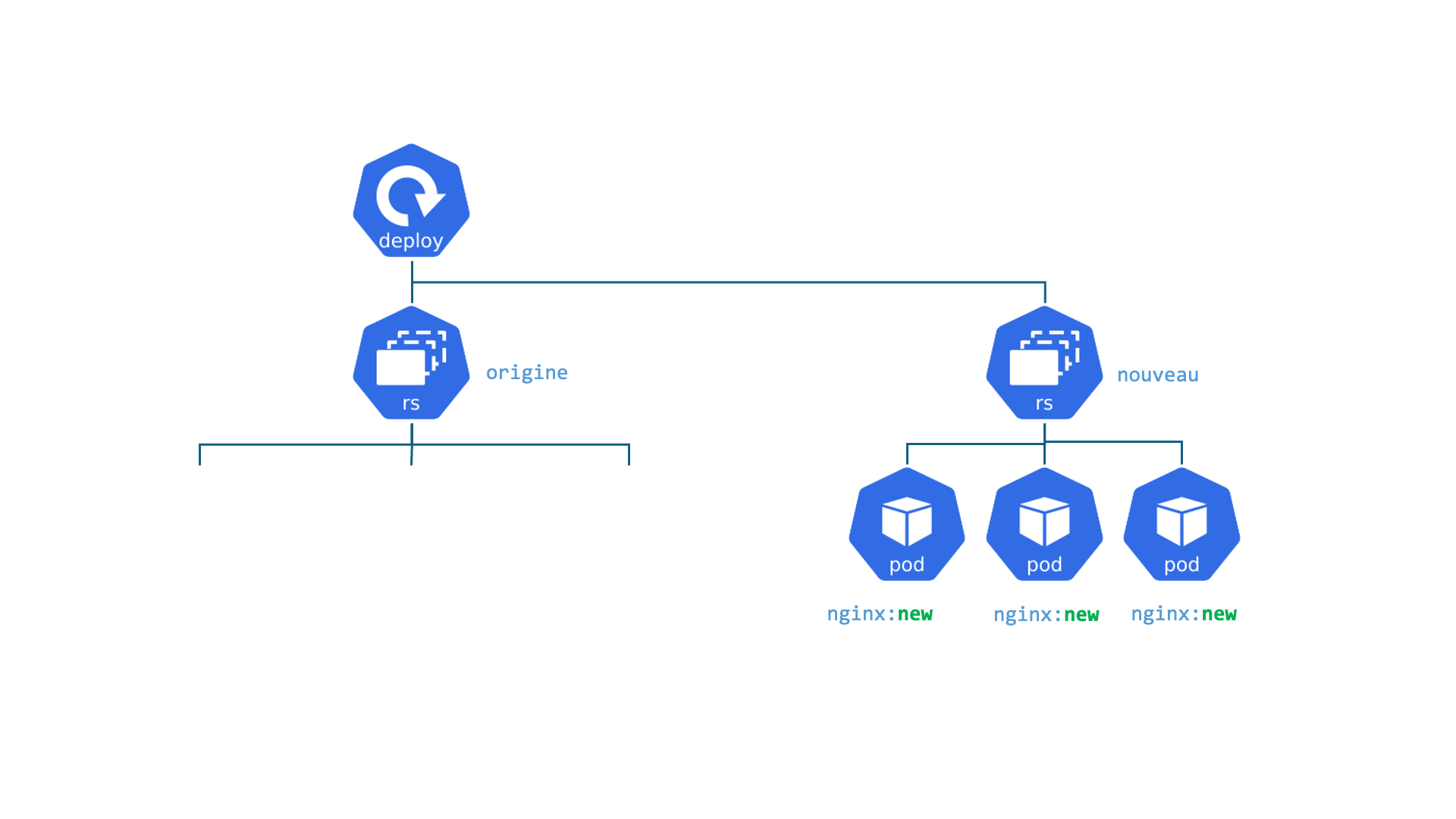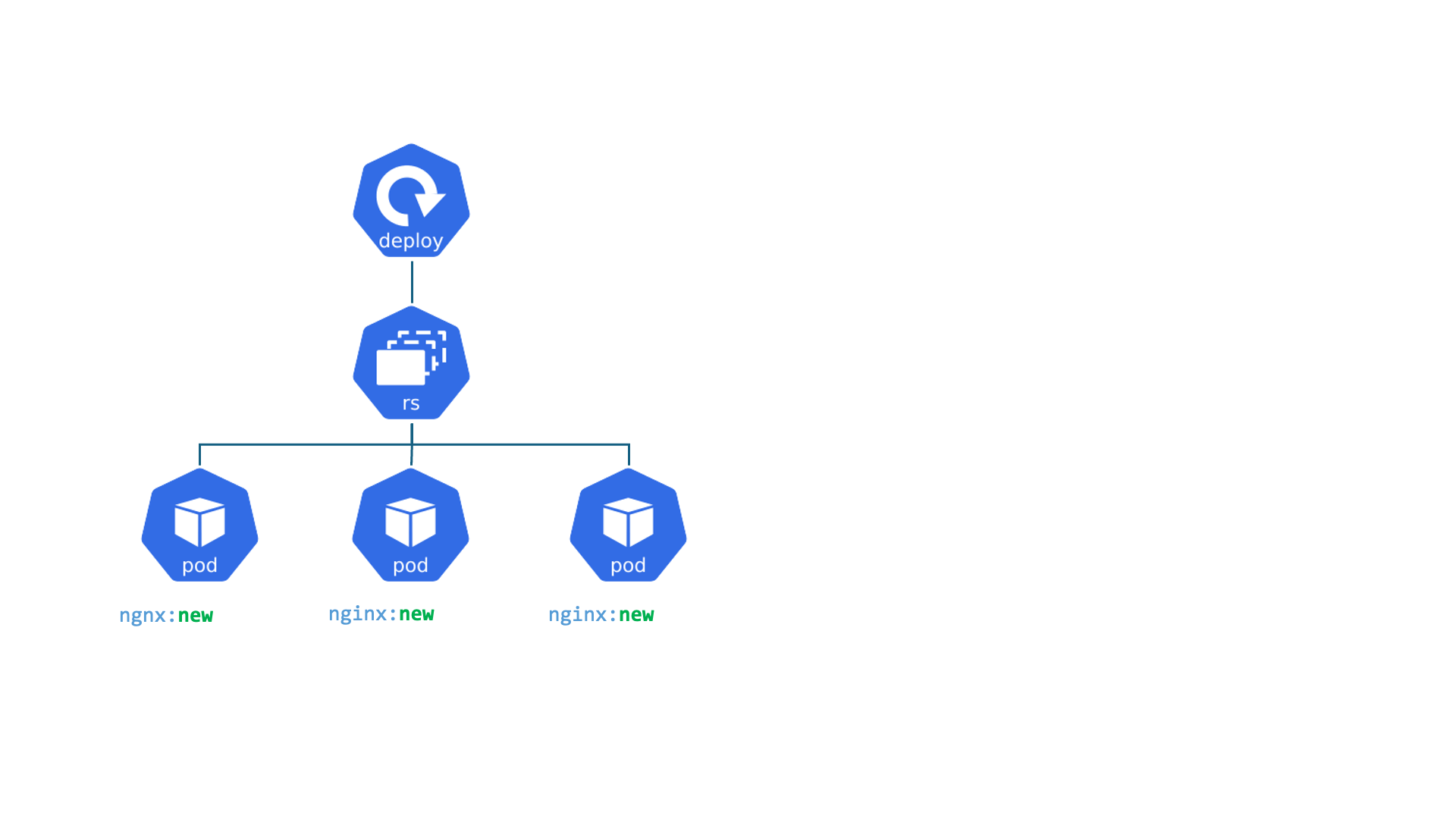
Blue Green
Caractéristiques du Blue-Green Deployment :
- Deux Environnements Distincts :
- Environnement Blue : L'environnement de production actuel qui reçoit tout le trafic des utilisateurs.
- Environnement Green : L'environnement où la nouvelle version de l'application est déployée et testée avant de recevoir du trafic.
- Isolation Complète :
- Les environnements Blue et Green sont complètement isolés l'un de l'autre. Cela permet de tester la nouvelle version (Green) sans affecter l'environnement de production actuel (Blue).
- Redirection du Traffic :
- Une fois que l'environnement Green est prêt et testé, le trafic est redirigé de l'environnement Blue vers l'environnement Green.
- Cette redirection peut être effectuée au niveau du service, du load balancer ou du DNS.
- Facilité de Retour en Arrière :
- Si un problème survient après la bascule vers l'environnement Green, il est facile de revenir à l'environnement Blue en redirigeant simplement le trafic vers l'ancien environnement.
- Minimisation des Temps d'Arrêt :
- Le déploiement Blue-Green minimise les temps d'arrêt car la bascule du trafic entre les environnements est généralement rapide et transparente pour les utilisateurs.
- Test en Conditions Réelles :
- L'environnement Green peut être testé dans des conditions réelles avant de recevoir le trafic de production. Cette approche permet de détecter et de corriger les problèmes potentiels avant la mise en production.
- Gestion des Données :
- Les bases de données et les états partagés doivent être gérés avec soin pour s'assurer que les deux environnements peuvent accéder aux mêmes données sans conflit.
- Des migrations de base de données peuvent être nécessaires, et il est essentiel de s'assurer que les deux versions de l'application sont compatibles avec le schéma de données.
- Ressources Supplémentaires :
- Le déploiement Blue-Green nécessite des ressources supplémentaires car les deux environnements doivent fonctionner en parallèle pendant la phase de test et de transition.
blue green
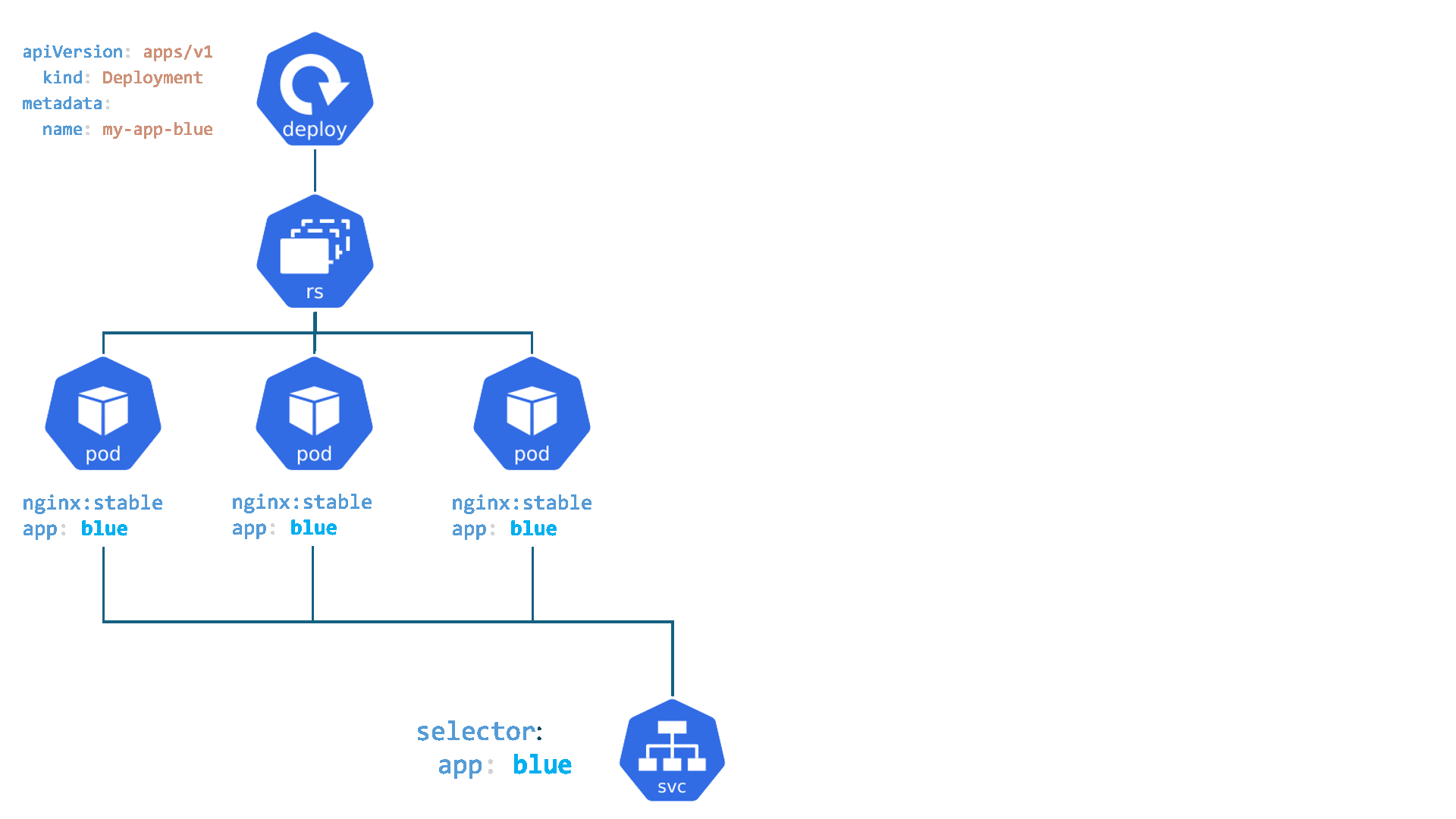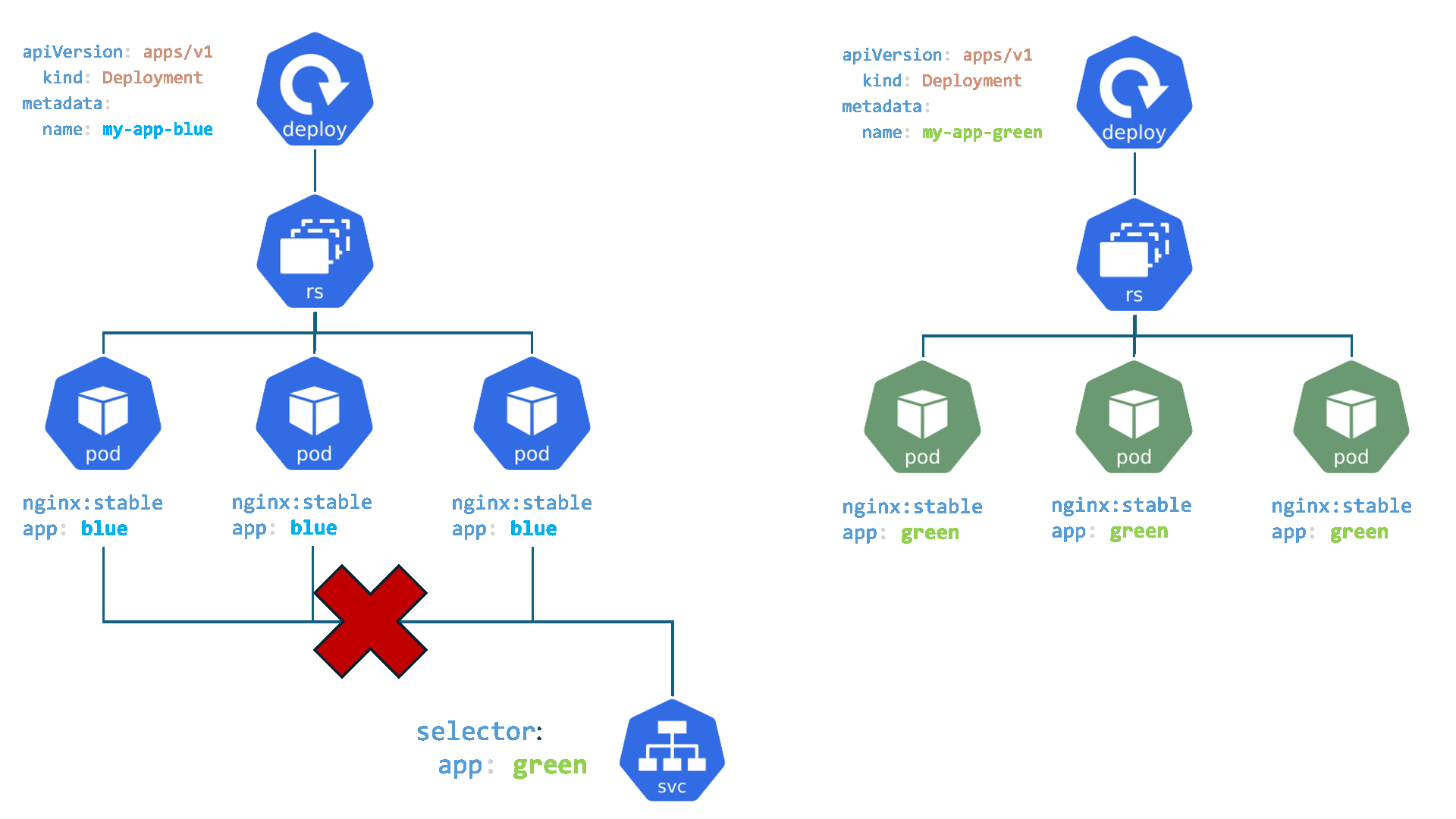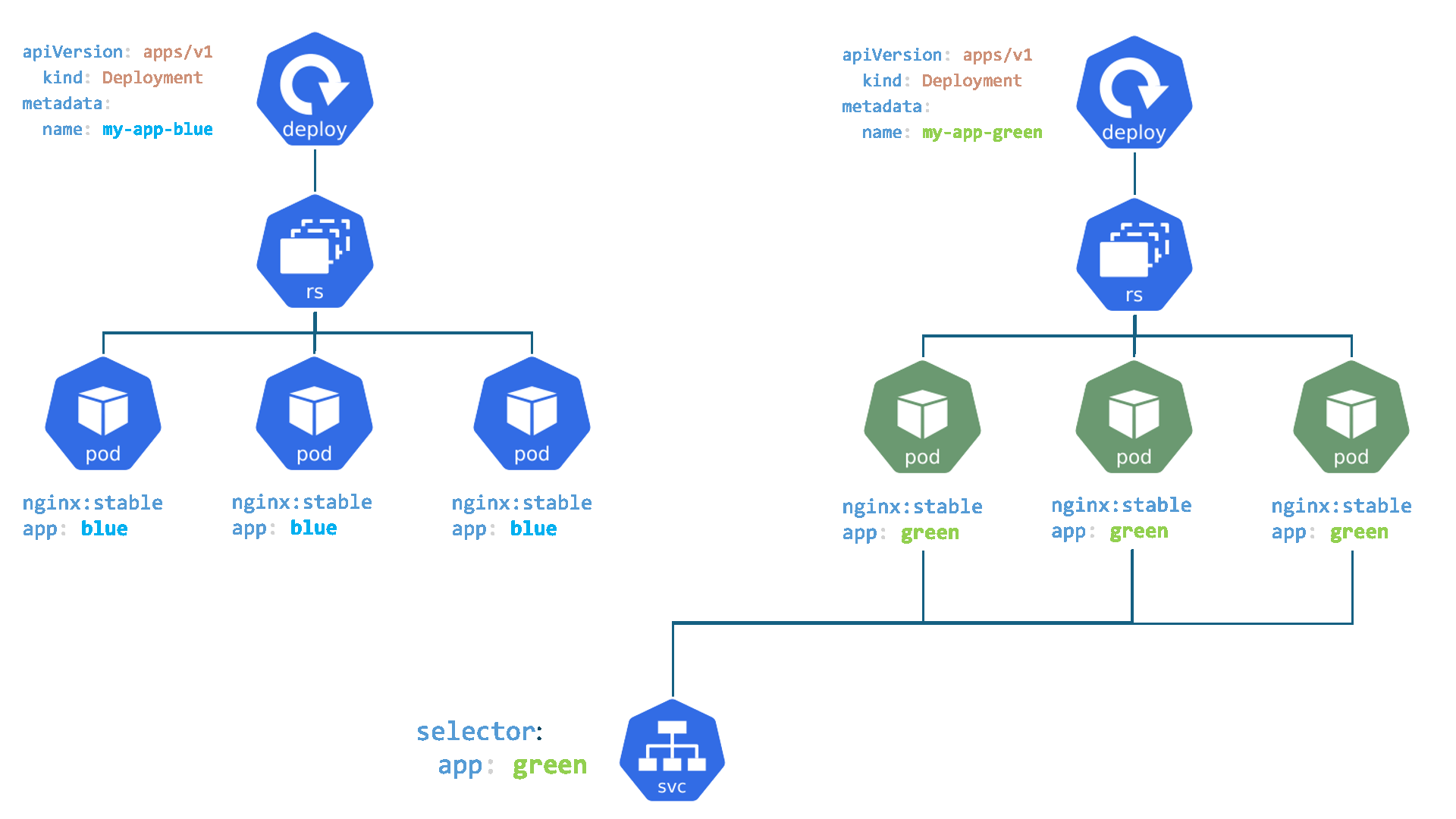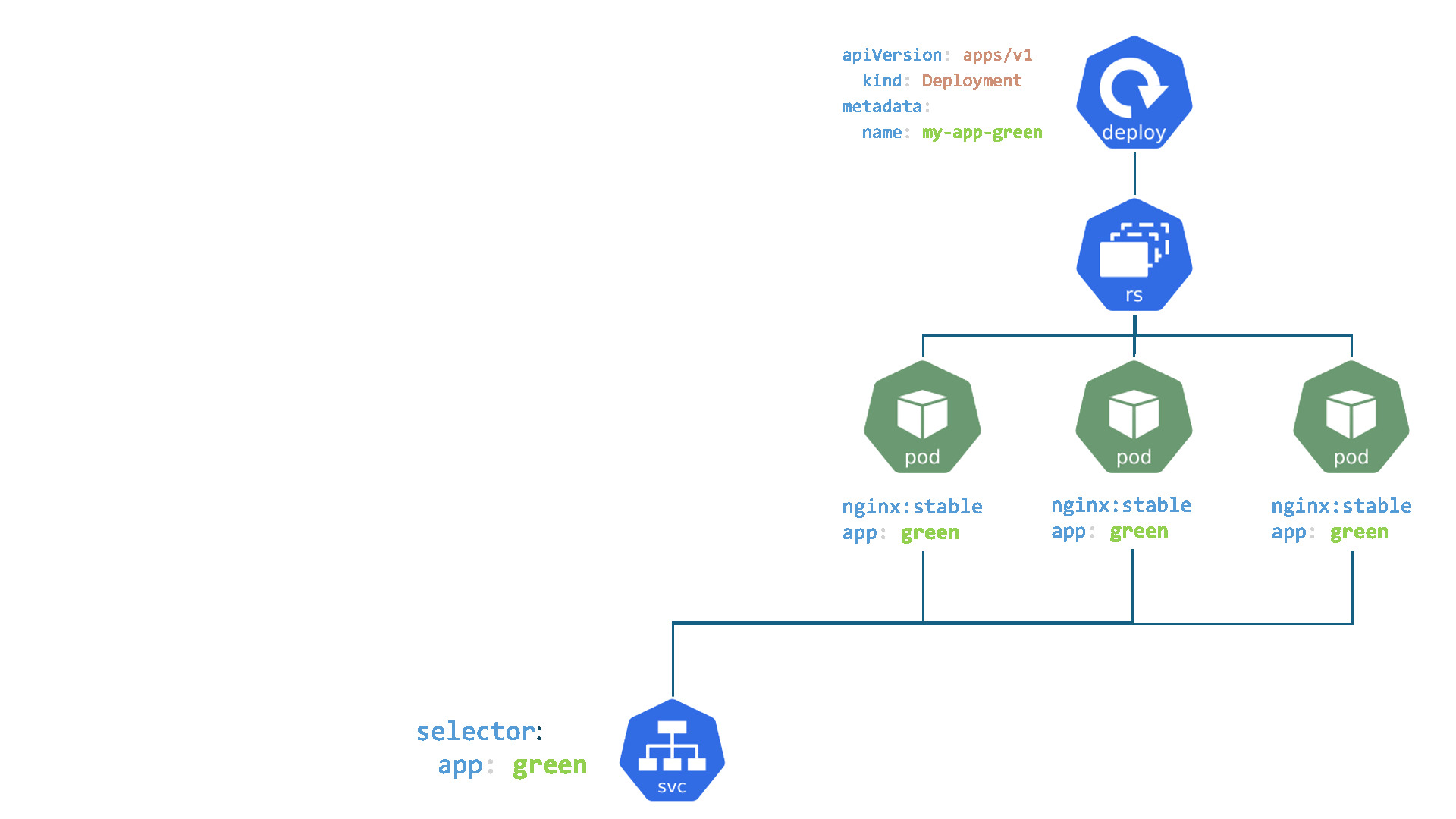
Recreate
Le mode de mise à jour "Recreate" dans Kubernetes est une stratégie utilisée pour déployer de nouvelles versions d'applications. Voici ses principales caractéristiques :
- Arrêt Complet Avant Redéploiement :
- Arrêt des Pods Existants : Tous les Pods de l'ancienne version de l'application sont arrêtés avant que les nouveaux Pods soient créés.
- Création des Nouveaux Pods : Une fois que tous les anciens Pods sont complètement arrêtés, les nouveaux Pods sont créés et déployés.
- Downtime :
- Ce mode entraîne une période de downtime, car il n'y a pas de Pods en cours d'exécution pendant la transition entre les anciennes et les nouvelles versions.
- Simplicité :
- La stratégie "Recreate" est simple à comprendre et à implémenter. Elle est souvent utilisée lorsque le downtime est acceptable ou lorsque l'application ne peut pas supporter plusieurs versions en même temps.
- Consistance :
- Assure qu’il n’y a qu’une seule version de l’application en cours d’exécution à tout moment, ce qui peut être crucial pour certaines applications qui ne peuvent pas fonctionner correctement avec plusieurs versions déployées simultanément.
- Risque Minimal d’Incompatibilité :
- Réduit les risques d’incompatibilité qui peuvent survenir lorsque plusieurs versions de l’application fonctionnent simultanément.
Recreate
Voici un exemple de configuration pour utiliser la stratégie "Recreate" dans un fichier de déploiement Kubernetes (deployment.yaml) :
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
strategy:
type: Recreate
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: my-app-image:latest
ports:
- containerPort: 80Cette configuration spécifie que Kubernetes doit utiliser la stratégie "Recreate" pour mettre à jour l'application my-app.
Canary Deployment
Si vous avez un ingress controller nginx faire du canary release est très simple.
Caractéristiques du Canary Deployment :
- Déploiement Graduel :
- La nouvelle version de l'application est d'abord déployée à un petit pourcentage de l'ensemble des utilisateurs.
- Le pourcentage de trafic dirigé vers la nouvelle version est progressivement augmenté.
Test en Conditions Réelles : -La nouvelle version est testée en conditions réelles avec un sous-ensemble d'utilisateurs, ce qui permet de détecter les problèmes et de les corriger avant un déploiement complet.
- Réduction du Risque :
- En cas de problème, il est facile de rediriger le trafic vers l'ancienne version, ce qui réduit le risque d'interruption de service pour l'ensemble des utilisateurs.
- Monitoring et Feedback :
- Une surveillance étroite est nécessaire pour évaluer les performances et la stabilité de la nouvelle version.
- Les métriques et les logs sont utilisés pour décider si le déploiement peut continuer ou s'il doit être annulé.
- Automatisation :
- Les outils de déploiement continu (CD) peuvent automatiser le processus de déploiement Canary, y compris la redirection du trafic et la surveillance.
Canary Deployment Exemple
Voir le lab dédié
Mise en place de l'autoscaling dans Kubernetes
Introduction
Qu'est-ce que l'autoscaling?
L'autoscaling est une technique qui permet d'ajuster automatiquement les ressources informatiques en fonction de la demande.
Dans le contexte de Kubernetes, l'autoscaling permet de :
Ajouter ou supprimer des Pods (unité de déploiement de Kubernetes) en fonction de l'utilisation des ressources.
Ajouter ou supprimer des nœuds (machines physiques ou virtuelles) dans le cluster pour répondre aux besoins de capacité.
Pourquoi est-ce important dans Kubernetes?
Optimisation des coûts : Réduire les coûts en ajustant dynamiquement les ressources en fonction de la demande réelle.
Haute disponibilité : Assurer que les applications restent disponibles et performantes en augmentant les ressources en cas de pics de charge.
Gestion efficace des ressources : Éviter le sur-provisionnement ou le sous-provisionnement des ressources.
Horizontal Pod Autoscaler (HPA)
Utilisé pour ajuster dynamiquement le nombre de pods en fonction de l'utilisation des ressources (CPU, mémoire, etc.).
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: example-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: example-deployment
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50En ligne de commande
kubectl apply -f https://k8s.io/examples/application/php-apache.yaml
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10Cluster Autoscaler
Ajuste le nombre de nœuds dans le cluster en fonction des besoins des pods.
Nécessite une intégration avec le fournisseur de cloud (GCP, AWS, Azure, etc.).
Exemple:
Configuration pour GCP.
apiVersion: autoscaling.k8s.io/v1
kind: ClusterAutoscaler
metadata:
name: cluster-autoscaler
spec:
scaleDown:
enabled: true
scaleUp:
enabled: trueVertical Pod Autoscaler (VPA)
VPA n'est pas natif à kubernetes il faut installer un contrôleur
https://github.com/kubernetes/autoscaler.git
Ajuste les ressources allouées à un pod en fonction de l'utilisation réelle.
Contrairement à l'Horizontal Pod Autoscaler (HPA), qui ajuste le nombre de pods, le VPA ajuste les ressources des pods existants.
Pourquoi utiliser le VPA ?
- Optimisation des ressources : Ajuste dynamiquement les ressources pour éviter le surprovisionnement et le - sous-provisionnement.
- Simplification de la gestion des ressources : Évite aux administrateurs de devoir ajuster manuellement les ressources allouées aux pods.
- Amélioration des performances : Assure que les pods ont suffisamment de ressources pour fonctionner efficacement, même avec des charges de travail variables.
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: example-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: example-deployment
updatePolicy:
updateMode: "Auto"KUBECTL : Usage Avancé
Kubectl : Usage avancé
- Certaines commandes qui modifient un déploimement accepte un flag optionnel
--record - Ce flag stocke la ligne de commande dans le déploiement
- Et est copié aussi dans le
replicaSet(annotation) - Cela permet de suivre quelle commande a créé ou modifié ce
replicatset
$ kubectl create -f nginx.yaml --record
deployment.apps/nginx created
# Voir les informations
kubectl rollout historyKubectl : Usage avancé
- Utiliser le flag
--record
# déployer l'image worker:v0.2
kubectl create deployment worker --image=dockercoins/worker:v0.2
# Roll back `worker` vers l'image version 0.1:
kubectl set image deployment worker worker=dockercoins/worker:v0.1 --record
# Le remettre sur la version 0.2:
kubectl set image deployment worker worker=dockercoins/worker:v0.2 --record
# Voir l'historique des changement:
kubectl rollout history deployment workerKubectl : Usage avancé
- Il est possible d'augmenter le nombre de pods avec la commande
kubectl scale:
kubectl scale --replicas=5 deployment nginx- Il est possible de changer l'image d'un container utilisée par un Deployment :
kubectl set image deployment nginx nginx=nginx:1.15Kubectl : Usage avancé
- Dry run. Afficher les objets de l'API correspondant sans les créer :
kubectl run nginx --image=nginx --dry-run=client
kubectl run nginx --image=nginx --dry-run=server- Démarrer un container en utilisant une commande différente et des arguments différents :
kubectl run nginx --image=nginx \
--command -- <cmd> <arg1> ... <argN>- Démarrer un Cron Job qui calcule π et l'affiche toutes les 5 minutes :
kubectl run pi --schedule="0/5 * * * ?" --image=perl --restart=OnFailure \
-- perl -Mbignum=bpi -wle 'print bpi(2000)'Kubectl : Usage avancé
- Se connecter à un container:
kubectl run -it busybox --image=busybox -- sh- S'attacher à un container existant :
kubectl attach my-pod -i- Accéder à un service via un port :
kubectl port-forward my-svc 6000- Mettre en place de l'auto-scaling ex: Mise à l'échelle automatique avec un minimum de 2 et un maximum de 10 réplicas lorsque l'utilisation du processeur est égale ou supérieure à 70 %
kubectl autoscale deployment my-Deployments --min=2 --max=10 --cpu-percent=70 Kubectl : Logging
- Utiliser
kubectlpour diagnostiquer les applications et le cluster kubernetes :
kubectl cluster-info
kubectl get events --sort-by='.lastTimestamp'
kubectl describe node <NODE_NAME>
kubectl describe node <node-name> | grep Taints
kubectl logs (-f) <POD_NAME>Kubectl : Logs
- Voir les logs containers
kubectl logs - Il est possible de donner un nom de pod ou un type/nom par exemple si l'on donne un nom de déploiement ou de replica set, les logs correspondront au premier pod
- Par défaut les logs affichées sont celles du premier container dans le pod.
# exemple :
kubectl logs deploy/nginx- Faire un
CTRL-Cpour arrêter la sortie
Kubectl : Afficher les logs en temps réel
kubectl logs supporte les options suivantes : - -f/--follow pour suivre les affichage des logs en temps réel (comme pour tail -f) - --tail pour n'afficher que les n lignes à partir de la fin de la sortie - --since pour n'afficher que les logs à partir d'une certaine date - --timestampsaffichera le timestamp du message
# exemple :
kubectl logs deploy/pingpong --tail 100 --follow --since=5s
# Affichera toutes les logs depuis 5 secondes et commencera au 100eme messages et continuera l'affichage des nouveaux messagesKubectl : Afficher les logs de plusieurs pods
Lorsque on spécifie un nom de déploiement, seuls les logs d'un seul pod sont affichés
Pour afficher les logs de plusieurs pod il faudra utiliser un
selecteur(label)
kubectl logs -l app=my-app --tail 100 # -f Kubectl : un outil très pratique pour les logs :

Kubectl : Maintenance
- Obtenir la liste des noeuds ainsi que les informations détaillées :
kubectl get nodes
kubectl describe nodesKubectl : Maintenance
- Marquer le noeud comme unschedulable (+ drainer les pods) et schedulable :
kubectl cordon <NODE_NAME>
kubectl drain <NDOE_NAME>
kubectl uncordon <NODE_NAME>Kubectl : Contexts
- Dans le cas ou votre kubeconfig comporte plusieurs clusters
# lister les contextes
kubectl config get-contexts
# Se déplacer dans un contexte
kubectl config use-context <nom-du-contexte>
# ou
alias kubectx='kubectl config use-context '
# ex: kubectx <nom-du-cluster>Kubectl : Se déplacer dans un NS de manière permanente
Évite de toujours préciser le flag -n
kubectl get ns
kubectl config set-context --current --namespace <nom-du-namespace>
# ou
alias kubens='kubectl config set-context --current --namespace '
# ex: kubens kube-system Kubectl : Installer des plugins
krew est un manager de plugins pour kubectl
installation de krew (https://krew.sigs.k8s.io/docs/user-guide/setup/install/)
kubectl krew install example
kubectl example deployListe des plugins : https://krew.sigs.k8s.io/plugins/ très utiles :
neat: permet de d'avoir un ouput "propre" d'une resource kubernetes - très utile pour créer des manifestes à partir de resources existantesctx: permet de changer de contexte facilementns: permet de changet de namespace facilementnode-shell: Créer un shell racine sur un nœud via kubectl, très pratique sur les CSPdf-pv: Afficher l'utilisation du disque (comme la commande df) pour les volumes persistantspopeye: Analyse vos clusters pour détecter d'éventuels problèmes de ressources
KUBERNETES : Sécurité et Contrôle d'accès
Authentication & Autorisation
Authentication
Authentication (Qui êtes-vous ?):
- Vérifie l'identité de l'utilisateur
Méthodes principales :
- Certificats clients X.509
- Tokens Bearer (JWT)
- Service Accounts pour les pods
- OpenID Connect / OAuth2
- Fichiers de configuration statiques
Résultat : identité confirmée ou requête rejetée
RBAC (Autorisation)
Authorization (Que pouvez-vous faire ?):
- Vérifie les permissions de l'utilisateur authentifié
- Utilise principalement RBAC (Role-Based Access Control)
Composants clés :
- Roles : définissent les permissions dans un namespace
- ClusterRoles : permissions à l'échelle du cluster
- RoleBindings : lient les rôles aux utilisateurs dans un namespace
- ClusterRoleBindings : lient les rôles aux utilisateurs au niveau cluster
3 entités sont utilisées :
- Utilisateurs représentés par les
Usersou lesServiceAccounts - Ressources représentées par les
Deployments,Pods,Services, etc... - les différentes opérations possibles :
create, list, get, delete, watch, patch
RBAC
- L'authentification précède toujours l'autorisation
- Une requête doit passer les deux contrôles pour être acceptée
- Les deux mécanismes sont indépendants mais complémentaires
- RBAC est le standard de facto pour l'autorisation dans Kubernetes

Service Accounts
- Objet Kubernetes permettant d'identifier une application s'exécutant dans un pod
- Par défaut, un
ServiceAccountparnamespace - Le
ServiceAccountest formatté ainsi :system:serviceaccount:<namespace>:<service_account_name>
Service Accounts
apiVersion: v1
kind: ServiceAccount
metadata:
name: default
namespace: defaultRole
- L'objet
Roleest un ensemble de règles permettant de définir quelle opération (ou verbe) peut être effectuée et sur quelle ressource - Le
Rolene s'applique qu'à un seulnamespaceet les ressources liées à cenamespace
Role
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]RoleBinding
- L'objet
RoleBindingva allouer à unUser,ServiceAccountou un groupe les permissions dans l'objetRoleassocié - Un objet
RoleBindingdoit référencer unRoledans le mêmenamespace. - L'objet
roleRefspécifié dans leRoleBindingest celui qui crée le liaison
RoleBinding
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: read-pods
namespace: default
subjects:
- kind: User
name: jane
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.ioClusterRole
- L'objet
ClusterRoleest similaire auRoleà la différence qu'il n'est pas limité à un seulnamespace - Il permet d'accéder à des ressources non limitées à un
namespacecomme lesnodes
ClusterRole
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: secret-reader
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "watch", "list"]ClusterRoleBinding
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: salme-reads-all-pods
subjects:
- kind: User
name: jsalmeron
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.ioRBAC
kubectl auth can-i get pods /
--namespace=default /
--as=spesnova@example.comNetworkPolicies
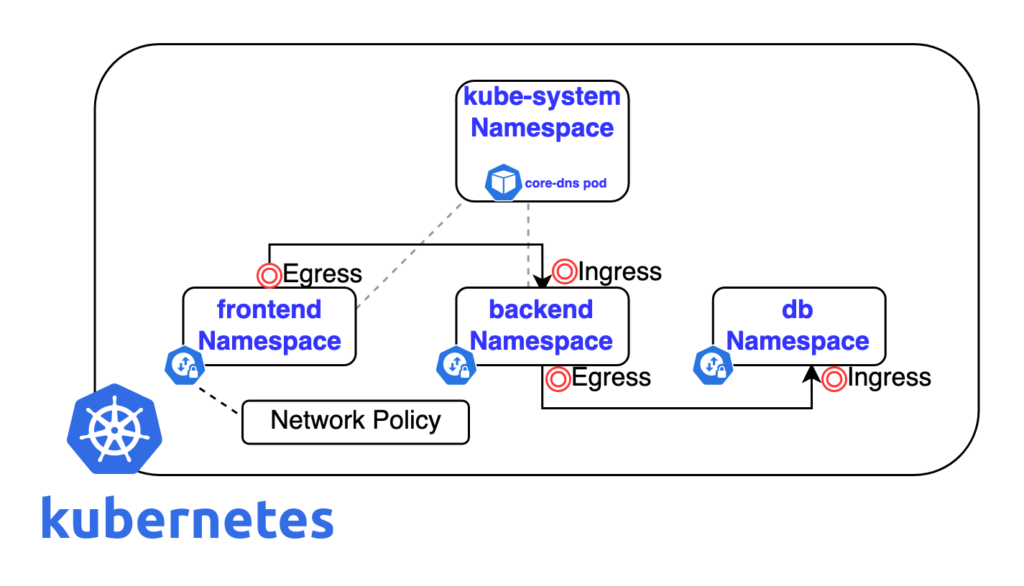
NetworkPolicies
La ressource
NetworkPolicyest une spécification permettant de définir comment un ensemble depodscommuniquent entre eux ou avec d'autres endpointsLe
NetworkPolicyutilisent les labels pour sélectionner les pods sur lesquels s'appliquent les règles qui définissent le trafic alloué sur les pods sélectionnésLe
NetworkPolicyest générique et fait partie de l'API Kubernetes. Il est nécessaire que le plugin réseau déployé supporte cette spécification
NetworkPolicies
- DENY tout le trafic sur une application
- LIMIT le trafic sur une application
- DENY les trafic entrant et sortant dans un namespace
- DENY tout le trafic venant d'autres namespaces
- exemples de Network Policies : https://github.com/ahmetb/kubernetes-network-policy-recipes
NetworkPolicies
- Exemple de
NetworkPolicypermettant de bloquer le trafic entrant :
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: web-deny-all
spec:
podSelector:
matchLabels:
app: web
ingress: []NetworkPolicies : outils : Cilium Network Policy Editor
Cilium Network Policy Editor : https://editor.networkpolicy.io/?id=xJYCeLwGmAGxTqjm
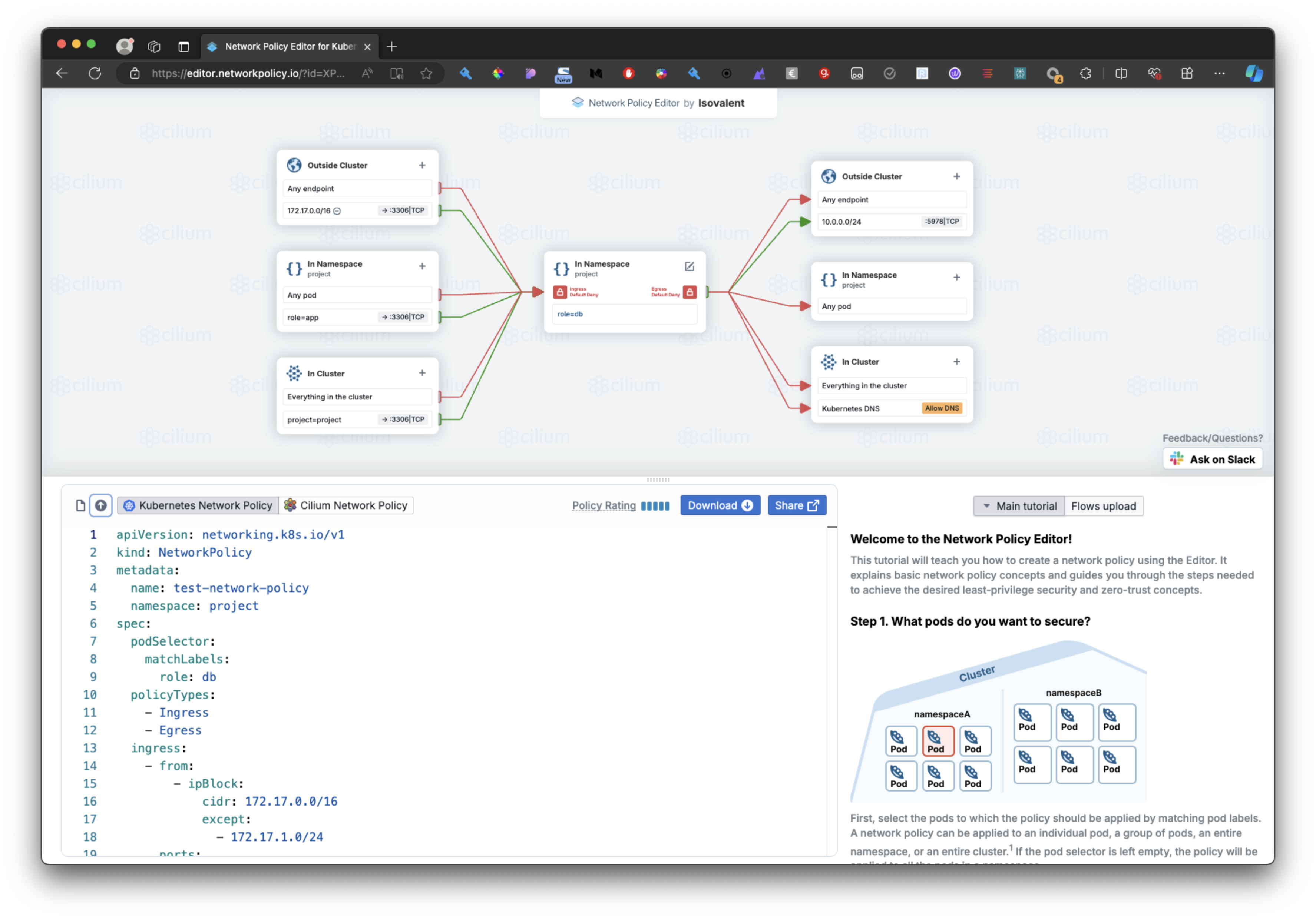
NetworkPolicies : outils : Tufin Network Policy Viewer
Tufin Network Policy Viewer : https://orca.tufin.io/netpol/
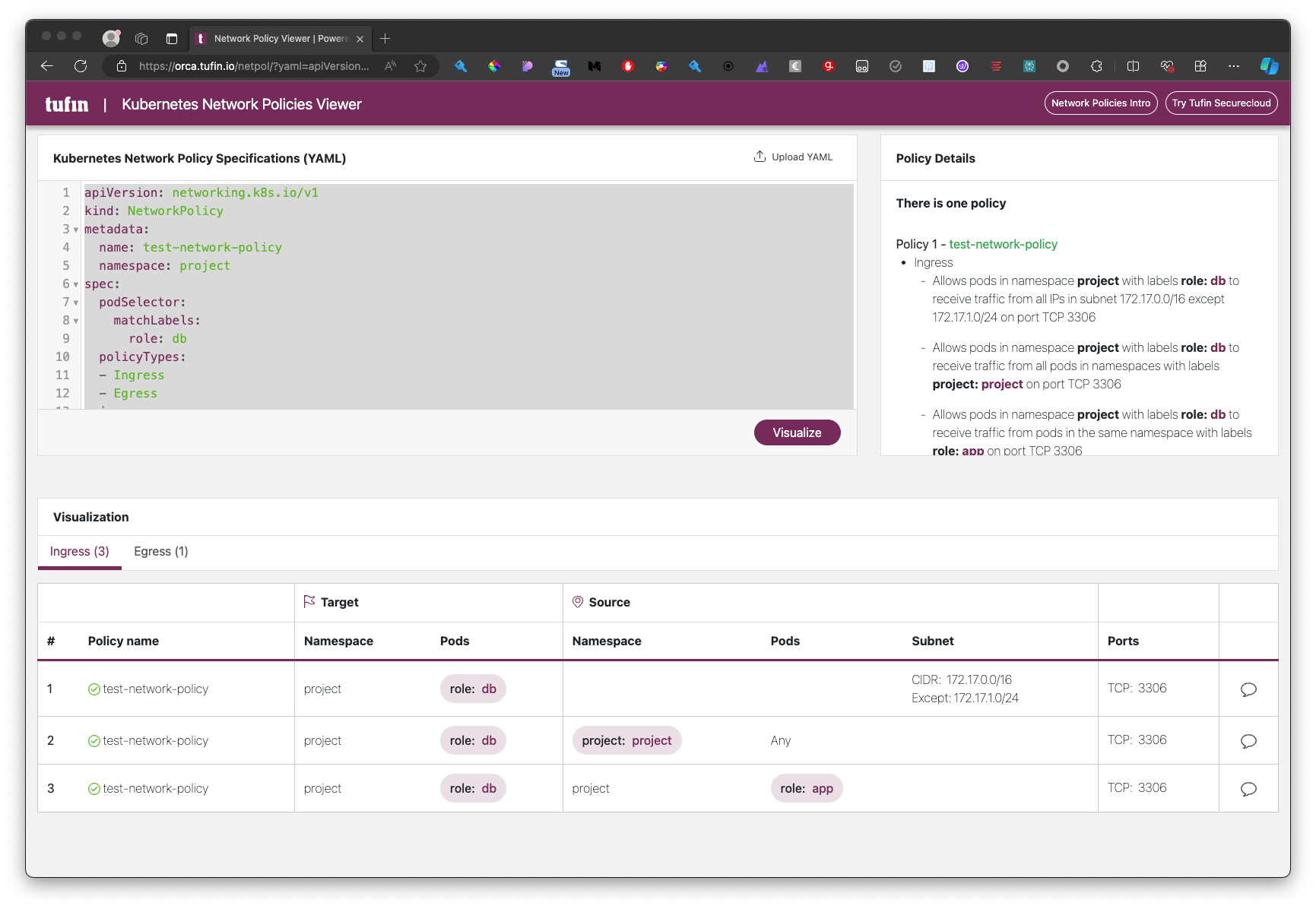
NetworkPolicies : outils : Kubernetes NetworkPolicy viewer
Kubernetes NetworkPolicy viewer : https://artturik.github.io/network-policy-viewer/
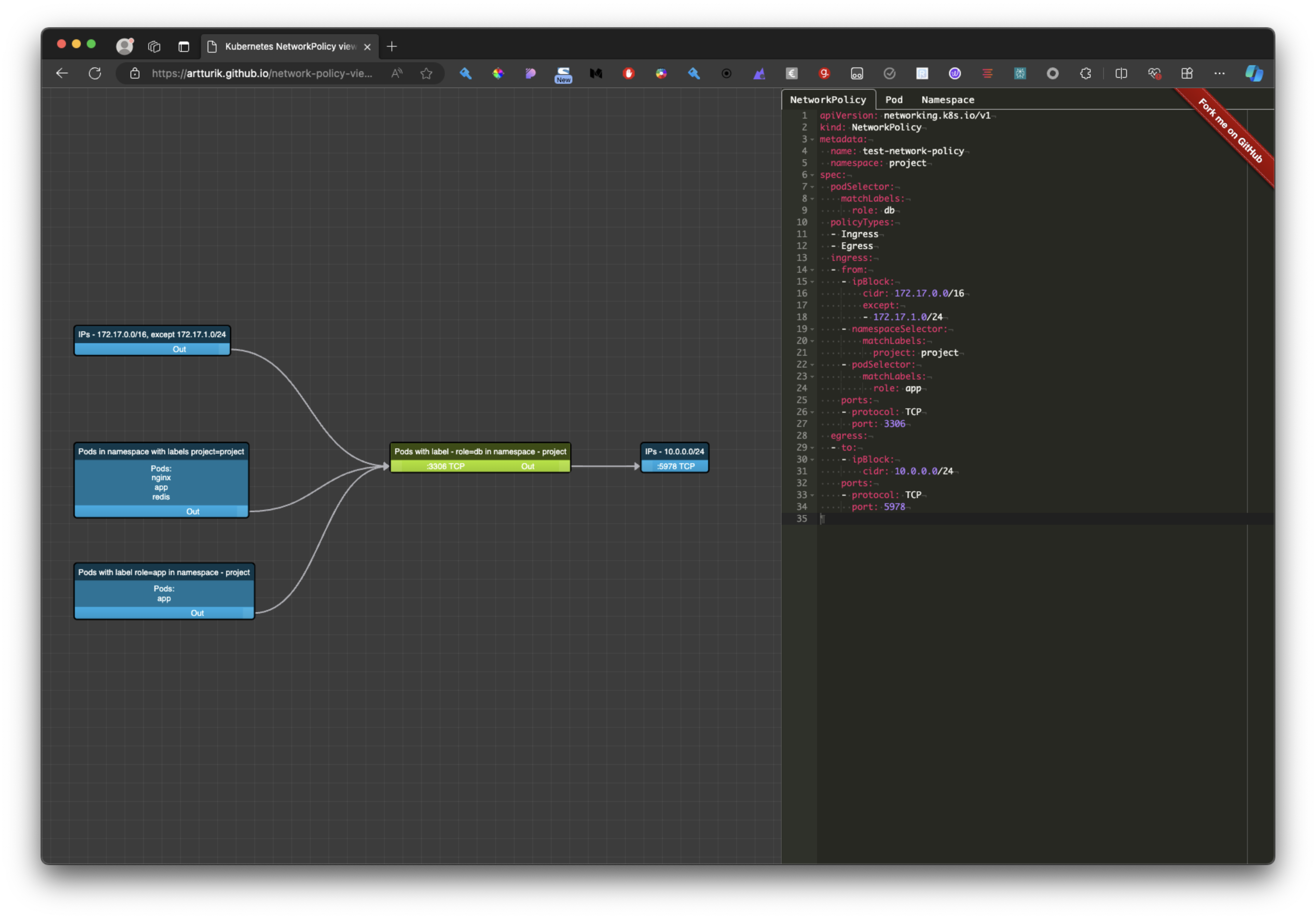
Pod Security Admission
Alpha en 1.22, GA depuis la 1.25
Plus simple que les PSP.
- S'appuie sur les standards de sécurité des pods (Pod Security Standards - PSS).
- Définit trois politiques :
- privileged (peut tout faire ; pour les composants système)
- peut tout faire
- restricted (pas d'utilisateur root ; presque aucune capacité)
- La politique Restricted vise à appliquer les meilleures pratiques actuelles de renforcement des Pods, au détriment d'une certaine compatibilité.
- Elle est destinée aux opérateurs et développeurs d'applications critiques pour la sécurité, ainsi qu'aux utilisateurs à faible niveau de confiance.
- baseline (intermédiaire avec des valeurs par défaut raisonnables)
- La politique Baseline vise à faciliter l'adoption pour les charges de travail conteneurisées courantes tout en prévenant les escalades de privilèges connues.
- Cette politique est destinée aux opérateurs d'applications et aux développeurs d'applications non critiques.
- privileged (peut tout faire ; pour les composants système)
- Labels sur les namespaces pour indiquer quelles politiques sont autorisées.
- Supporte également la définition de valeurs par défaut globales.
- Supporte les modes enforce, audit et warn.
Pod Security Admission : Namespace labels
Trois labels optionnels peuvent être ajoutés aux namespaces :
- pod-security.kubernetes.io/enforce
- pod-security.kubernetes.io/audit
pod-security.kubernetes.io/warn
- enforce = empêche la création de pods
- warn = autorise la création mais inclut un avertissement dans la réponse de l'API (sera visible par exemple dans la sortie de kubectl)
audit = autorise la création mais génère un événement d'audit de l'API (sera visible si l'audit de l'API a été activé et configuré)
Les valeurs possibles sont :
- baseline,
- restricted,
- privileged
(définir la valeur à privileged n'a pas vraiment d'effet)
Pod Security Admission : Exemple
apiVersion: v1
kind: Namespace
metadata:
labels:
kubernetes.io/metadata.name: formation-k8s
pod-security.kubernetes.io/enforce: baseline
pod-security.kubernetes.io/audit: restricted
pod-security.kubernetes.io/warn: restricted
name: formation-k8sLes trois lignes suivantes définissent les labels:
pod-security.kubernetes.io/enforce=baseline :
- Applique la politique de sécurité "baseline" en mode "enforce".
- Cela empêchera la création de pods qui ne respectent pas les critères de sécurité de base.
pod-security.kubernetes.io/audit=restricted :
- Configure l'audit en mode "restricted".
- Cela générera des événements d'audit pour les pods qui ne respectent pas les critères de sécurité restrictifs.
pod-security.kubernetes.io/warn=restricted :
- Active les avertissements en mode "restricted".
- Cela produira des avertissements lors de la création de pods qui ne respectent pas les critères de sécurité restrictifs.Pod Security Admission : Revenir en arriere
apiVersion: v1
kind: Namespace
metadata:
labels:
kubernetes.io/metadata.name: formation-k8s
pod-security.kubernetes.io/enforce: privileged
pod-security.kubernetes.io/audit: privileged
pod-security.kubernetes.io/warn: privileged
name: formation-k8s- Typiquemement les pod dans kube-system doivent pouvoir être en mode privileged.
- Si vous ne définissez pas de PSA les pod privilégiés sont autorisés.
KUBERNETES : Introduction à Helm
kubernetes : Helm admission à la CNCF
- Le 30 avril 2020, Helm était le 10e projet à être diplômé (graduate) au sein de la CNCF
(aux côtés de Containerd, Prometheus et Kubernetes lui-même)
- Il s'agit d'une reconnaissance de la CNCF pour les projets qui
- démontrent une adoption florissante, un processus de gouvernance ouvert,
- qui ont un engagement fort envers la communauté, la durabilité et l'inclusivité.
A voir :
Kubernetes : Helm différence entre charts et packages
- Une application conçue pour faciliter l'installation et la gestion des applications sur Kubernetes.
- Il utilise un format de paquetage appelé
Charts. - Il est comparable à apt/yum/homebrew.
- Un chart contient des manifestes yaml
- Sur la plupart des distributions, un package ne peut être installé qu'une seule fois (l'installation d'une autre version remplace celle installée)
- Un chart peut être installé plusieurs fois
- Chaque installation est appelée une version
- Cela permet d'installer par ex. 10 instances de MongoDB (avec des versions et configurations potentiellement différentes)
Kubernetes : Concepts de Helm
helmest un outil CLIIl est utilisé pour trouver, installer, mettre à jour des charts
Un
Chartest une archive contenant des bundles YAML modélisés. Un chart est pratiquement un regroupement de ressources Kubernetes pré-configurées.Release: Une instance d'un chart helm s'exécutant dans un cluster Kubernetes.Repository: répertoire ou espace (public ou privé) où sont regroupés lescharts.Les charts sont versionnés
Les charts peuvent être stockés sur des référentiels privés ou publics
Kubernetes : Structure d'un Helm Chart
- Structure par défaut d'un chart
mychart/
├── Chart.yaml
├── charts
├── templates
│ ├── NOTES.txt
│ ├── _helpers.tpl
│ ├── deployment.yaml
│ ├── hpa.yaml
│ ├── ingress.yaml
│ ├── service.yaml
│ ├── serviceaccount.yaml
│ └── tests
│ └── test-connection.yaml
└── values.yamlKubernetes : Helm Chart : Mode de fonctionnement
Kubernetes : Helm installation premiers pas
Installer Helm (sur une distribution Linux):
curl \ https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get-helm-3 | bash- Voir la liste des
chartsdisponibles sur les répertoires officiels :helm search - Afficher la liste des
chartsdisponibles pour prometheus :helm search prometheus Afficher les options disponibles dans un
chartHelm:helm inspect stable/prometheus
Kubernetes : Helm - Charts et repositories
Un repository (repo) est une collection de charts
- C'est simplement un ensemble de fichiers locaux ou hébergés sur un serveur web statiquement
- On peut ajouter des repos à helm en leur donnant un surnom
Le surnom sert à référencer les charts de ce repo
(they can be hosted by a static HTTP server, or on a local directory) - Par exemple helm install hello/world : le chart world dans le repo hello, hello peut être quelque chose comme https://alterway.fr/charts/
Kubernetes : Helm - Manager les repositories
Vérifions quels référentiels nous avons et ajoutons le référentiel stable
(le repo stable contient un ensemble des charts officiels)
# Lister vos repos:
helm repo list
# Ajouter the `stable` repo:
helm repo add stable https://charts.helm.sh/stableKubernetes : Helm - Chercher les Charts disponibles
On peut chercher les charts avec la commande suivante
helm searchIl faut spécifier ou chercher
repoouhub
# Chercher nginx dans tous les repos ajoutés précédemment
helm search repo nginx
# Chercher nginx sur le hub Helm:
helm search hub nginxHelm Hub indexe tout un tas de repo, en utilisant le serveur Monocular.
Kubernetes : Helm - Charts et releases
"Installer un chart" veut dire installer une release
Il faut donner un nom à cette Release
(ou utiliser le flag --generate-name pour que helm le fasse automatiquement pour nous)
# Installer le chart nginx :
helm install nginx stable/nginx
# List the releases:
helm listKubernetes : Helm - Voir les ressources d'une release
- Il est possible d'utiliser un sélecteur (label)
# Lister toutes les resources créées dans une release
kubectl get all --selector=release=nginxKubernetes : Helm - Configurer une release
Par défaut, le chart
stable/nginxcrée un service de typeLoadBalancerOn veut changer cela en un
NodePorton peut utiliser
kubectl edit service nginx-nginx, mais ...
... nos modifications seraient écrasées la prochaine fois qu'on met à jour ce Chart !
On va pour cela définir une valeur pour le type de service
Les valeurs sont des paramètres que le Chart peut utiliser pour modifier son comportement
Les valeurs ont des valeurs par défaut
Chaque Chart peut de définir ses propres valeurs et leurs valeurs par défaut
Kubernetes : Helm - Voir les différentes valeurs
- Il est possible d'inspecter une release avec les commandes
helm showorhelm inspect
# Look at the README for nginx:
helm show readme stable/nginx
# Look at the values and their defaults:
helm show values stable/nginxLes values n'ont peut être pas de commentaires utiles.
Le fichier readme peut ou pas, donner des informations sur ces values.
Kubernetes : Helm - Changer les valeurs
Les valeurs peuvent être définies lors de l'installation d'un Chart ou lors de sa mise à jour
helm installhelm upgradeDans notre exemple, on va mettre à jour
nginxpour changer le type de service
# Update `nginx`:
helm upgrade nginx stable/nginx --set service.type=NodePortKubernetes : Helm - Créer un chart
- Utilisation de la commande :
helm create myappva permettre de créer la structure de répertoire et de fichiers d'un chart "standard" - Par défaut, ce Chart déploie un
nginxen templétisant lesservices,deployment,serviceAccount, etc... - C'est une bonne base pour démarrer
Kubernetes : Helm - A quoi d'autre peut servir un chart Helm
- Outre le fait de déployer des applications, on peut gérer d'autres choses avec helm, grâce à la puissance du langage de template
- Gérer facilement les Roles / Rolebinding / ClusterRole / ClusterRoleBinding
- Des paramétrages d'opérateurs
- ...
KUBERNETES : Introduction à Kustomize
kubernetes : kustomize
- Kustomize permet de transformer des manifestes yaml contenant des ressources kubernetes
- Les manifestes d'origine restent inchangés et donc utilisables tels quels (
kubectl apply/create/delete -f) - On créé des
kustomizations - Une
kustomizationspeut se voir comme une superposition (overlay) (ajout ou modification) - Les
kustomizationssont définies dans un fichierkustomizations.yaml
kubernetes : kustomizations
- Une kustomization peut contenir:
- d'autres kustomizations
- des ressources kubernetes définies en yaml
- des patchs de ressources kubernetes
- des ajouts de
labelsouannotationspour toutes les ressources - des définitions de
configmapsousecrets
kubernetes : kustomizations : exemple 1
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
patchesStrategicMerge:
- scale-deployment.yaml
- ingress-hostname.yaml
resources:
- deployment.yaml
- service.yaml
- ingress.yamlkubernetes : kustomizations : exemple 2
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
commonLabels:
add-this-to-all-my-resources: please
patchesStrategicMerge:
- prod-scaling.yaml
- prod-healthchecks.yaml
bases:
- api/
- frontend/
- db/
- github.com/example/app?ref=tag-or-branch
resources:
- ingress.yaml
- permissions.yaml
configMapGenerator:
- name: appconfig
files:
- global.conf
- local.conf=prod.confkubernetes : kustomizations : Glossaire
https://kubectl.docs.kubernetes.io/references/kustomize/glossary/
base: Unebaseest une kustomisation référencée par une autre kustomisationoverlay: unoverlayest une kustomization qui dépend d'une autre kustomizationkustomization: Unekustomizationpeut être à la fois unebaseet unoverlaypatch: unpatchdécrit comment modifier une ressource existantevariant: unevarianteest le résultat, dans un cluster, de l'application d'unoverlayà unebase
kubernetes : kustomizations : Structure
├── base
│ ├── deployment.yaml
│ ├── kustomization.yaml
│ └── service.yaml
└── overlays
├── dev
│ ├── kustomization.yaml
│ └── patch.yaml
├── prod
│ ├── kustomization.yaml
│ └── patch.yaml
└── staging
├── kustomization.yaml
└── patch.yamlIntroduction à ArgoCD
Qu'est-ce qu'ArgoCD ?
ArgoCD est un outil de déploiement continu (CD) déclaratif pour Kubernetes. - Conçu pour implémenter le GitOps - Open source et partie de la CNCF - Permet de synchroniser l'état souhaité (Git) avec l'état réel (Kubernetes)
ArgoCD : Avantages Clés
- GitOps natif: Votre code Git devient la source unique de vérité
- Automatisation: Déploiements automatiques lors des changements dans Git
- Visibilité: Interface utilisateur intuitive pour surveiller les déploiements
- Sécurité: Gestion fine des accès et audit complet des changements
ArgoCD: Architecture
┌─────────────┐
│ │
│ Git │
│ │
└──────┬──────┘
│
▼
┌──────────────┐ ┌──────────────┐ ┌─────────────┐
│ ArgoCD │ │ ArgoCD │ │ │
│ API │◄──┤ Controller │──►│ Kubernetes │
│ Server │ │ │ │ Cluster │
└──────────────┘ └──────────────┘ └─────────────┘ArgoCD : Concepts Fondamentaux

1. Applications
- Groupe de ressources Kubernetes à déployer ensemble
- Définies de manière déclarative
- Peuvent être liées à différentes sources (Git, Helm)
2. Projets
- Regroupement logique d'applications
- Permet de définir des restrictions et des permissions
- Isolation des ressources par équipe/environnement
3. Synchronisation
- Automatique ou manuelle
- Détection des dérives de configuration
- Rollback automatique possible
Exemple de Configuration
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: mon-app
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/mon-org/mon-app.git
targetRevision: HEAD
path: k8s
destination:
server: https://kubernetes.default.svc
namespace: productionBonnes Pratiques
- Structure des Repositories
- Séparer le code applicatif des manifestes Kubernetes
- Utiliser des branches pour les différents environnements
- Sécurité
- Implémenter RBAC strict
- Utiliser des secrets externes
- Activer SSO quand possible
- Monitoring
- Configurer des alertes sur les échecs de synchronisation
- Surveiller les métriques ArgoCD
- Mettre en place des notifications
Pour Aller Plus Loin
- Documentation officielle : https://argo-cd.readthedocs.io/
- Projets complémentaires :
- Argo Rollouts pour les déploiements avancés
- Argo Events pour l'event-driven
Argo Workflows pour l'orchestration
Exposer les services HTTP avec les ressources Ingress
Exposer les services HTTP avec les ressources Ingress
Les services nous permettent d'accéder à un pod ou à un ensemble de pods
- Les services peuvent être exposés au monde extérieur:
- avec le type NodePort (sur un port> 30000)
- avec le type LoadBalancer (allocation d'un répartiteur de charge externe)
Qu'en est-il des services HTTP?
Exposer les services HTTP
Si nous utilisons les services NodePort, les clients doivent spécifier les numéros de port
(c'est-à-dire http: // xxxxx: 31234 au lieu de simplement http: // xxxxx)
Les services LoadBalancer sont bien, mais:
ils ne sont pas disponibles dans tous les environnements
ils entraînent souvent un coût supplémentaire (par exemple, ils fournissent un ELB)
ils nécessitent une étape supplémentaire pour l'intégration DNS (en attendant que le
LoadBalancersoit provisionné; puis en l'ajoutant au DNS)
Ressources Ingress
Ressource API Kubernetes (
kubectl get ingress / ingresses / ing)Conçu pour exposer les services HTTP
- Caractéristiques de base:
- l'équilibrage de charge
- Terminaison SSL
- vhost basé sur le nom
- Peut également router vers différents services en fonction de:
- Chemin URI (par exemple / api → api-service, / static → assets-service)
- En-têtes client, y compris les cookies (pour les tests A / B, déploiement canary ...)
- ...
Principe de fonctionnement
- Étape 1: déployer un
Ingress Controller
Ingress Controller = répartiteur de charge + boucle de contrôle
La boucle de contrôle surveille les Objects Ingress et configure le LB en conséquence
- Étape 2: configurer le DNS
Associer les entrées DNS à l'adresse du LB
- Étape 3: créer des Ingress
L'Ingress Controller prend ces ressources et configure le LB (load balancer)
- Étape 4: Votre Site est prêt à être utilisé !
À quoi ressemble une ressource Ingress?
Un exemple simple
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: podinfo-ing
namespace: podinfo
spec:
ingressClassName: nginx
rules:
- host: podinfo.formation.com
http:
paths:
- backend:
service:
name: podinfo
port:
number: 9898
path: /
pathType: Prefix
tls:
- hosts:
- podinfo.formation.com
secretName: podinfo.formation.com-tlsKUBERNETES : Maintenance du Cluster
Upgrade de l'OS
- Le retrait d'un noeud du cluster peut survenir suite à une panne ou pour des fins de maintenance comme des opérations de mise à jour, ou d'application de correctifs de sécurité.
- La commande
kubectl drainpermet de vider un noeud des pods qu'il héberge vers un autre noeud, puis de marquer le noeud "not schedulable". Ainsi au cours de l'opération de maintenance, aucun pod ne peut lui être affecté.
Upgrade de l'OS
- Avec
kubectl uncordon, le noeud est remis dans le cluster et peut à nouveau héberger des pods. - La commande
kubectl cordonmarque uniquement le noeud "not schedulable" tout en conservant les pods qu'il héberge. Il s'assure simplement que de nouveaux pods ne lui soient pas affectés.
Upgrade de l'OS
- Il est important de mettre à jour la version de kubernetes afin de bénéficier de nouvelles fonctinnalités.
- Ce process s'effectue par la mise à jour des composants du control plane
- Les composants du control plane peuvent avoir des versions différentes mais celle de l'API server doit toujours être suppérieure à celle des autre composants
- Le passage de version s'effectue de façon incrémentielle. On ne peut par exemple que passer de la version v1.19.x à la version v1.23.x
- Un upgrade de Kubeadm met à jour les composants du control plane sauf le kubelet. Il est nécessaire de le mettre à jour séparément pour un passage à niveau complet.
Upgrade de l'OS
- Voici les étapes à suivre pour une mise à niveau d'un cluster avec Kubeadm:
- La commande
kubeadm upgrade planfournit les informations sur la version actuelle de kubeadm installée, la version du cluster et la dernière version stable de Kubernetes disponible
kubectl drain worker-0
apt-get upgrade -y kubeadm=1.21.0-00
apt-get upgrade -y kubelet=1.21.0-00
apt-get upgrade node config --kubelet-version v1.21.0
systemctl restart kubelet
kubectl uncordon worker-0ETCD sauvegarde et restauration
- Il est recommandé de faire des sauvegardes régulières de la base de données ETCD. Une restauration peut être nécessaire après un désastre ou une maintenance.
etcdctlest un client en ligne de commande du service ETCD- Avec une installation par défaut de Kubeadm, la base de données clé-valeur ETCD est déployée en tant que pod statique sur le Master node.
- Les commandes
etcdctl snapshot save -h= sauvegarder la base de données.etcdctl snapshot restore -h= restaurer la base de données.
KUBERNETES : Troubleshouting
Troubleshooting des Pods
- Vérifier l'état des pods
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deploy-8fd84bbd6-b8d48 1/1 Running 0 45d
nginx-deploy-8fd84bbd6-fqmgk 1/1 Running 0 45d
nginx-deploy-8fd84bbd6-nvq5b 1/1 Running 0 45d
mysql-database 0/1 CrashLoopBackOff 1 18s
mysql-database1 0/1 ImagePullBackOff 0 6s
web-deploy-654fb8bb79-24nvd 0/1 Pending 0 2ssi l'état de votre pod n'est pas "Running", vous devrez suivre quelques étapes de débogageTroubleshooting des Pods
L'état de votre pod est en "CrashLoopBackOff"
Faites une description sur le pod et regardez la section "Events". Vous remarquerez peut-être un warning "Back-off restarting failed"
$ kubectl describe pods mysql-database
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m18s default-scheduler Successfully assigned default/mysql-database to gke-certif-test-default-pool-27dfc050-9bww
Normal Pulled 76s (x4 over 2m7s) kubelet, gke-certif-test-default-pool-27dfc050-9bww Successfully pulled image "mysql"
Normal Created 76s (x4 over 2m3s) kubelet, gke-certif-test-default-pool-27dfc050-9bww Created container mysql
Normal Started 75s (x4 over 2m2s) kubelet, gke-certif-test-default-pool-27dfc050-9bww Started container mysql
Warning BackOff 46s (x8 over 2m1s) kubelet, gke-certif-test-default-pool-27dfc050-9bww Back-off restarting failed container
Normal Pulling 32s (x5 over 2m17s) kubelet, gke-certif-test-default-pool-27dfc050-9bww Pulling image "mysql"Troubleshooting des Pods
Vous pouvez connaître la raison de l'échec en vérifiant les logs des conteneurs de votre pod $ kubectl logs mysql-database --container=mysql
2020-03-06 10:07:26+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 8.0.19-1debian10 started.
2020-03-06 10:07:26+00:00 [Note] [Entrypoint]: Switching to dedicated user 'mysql'
2020-03-06 10:07:26+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 8.0.19-1debian10 started.
2020-03-06 10:07:26+00:00 [ERROR] [Entrypoint]: Database is uninitialized and password option is not specified
You need to specify one of MYSQL_ROOT_PASSWORD, MYSQL_ALLOW_EMPTY_PASSWORD and MYSQL_RANDOM_ROOT_PASSWORDTroubleshooting des Pods
L'état de votre pod est en "ImagePullBackOff"
Faites une description sur le pod et regardez la section "Events". Vous pouvez remarquer l'erreur "ErrImagePull". Cela signifie que vous avez mis une mauvaise image de docker ou que vous avez une mauvaise autorisation d'accès au registre
$ kubectl describe pods mysql-database1
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 105s default-scheduler Successfully assigned default/mysql-database1 to gke-certif-test-default-pool-27dfc050-9bww
Normal SandboxChanged 103s kubelet, gke-certif-test-default-pool-27dfc050-9bww Pod sandbox changed, it will be killed and re-created.
Normal BackOff 31s (x6 over 103s) kubelet, gke-certif-test-default-pool-27dfc050-9bww Back-off pulling image "mysql:dert12"
Warning Failed 31s (x6 over 103s) kubelet, gke-certif-test-default-pool-27dfc050-9bww Error: ImagePullBackOff
Normal Pulling 16s (x4 over 104s) kubelet, gke-certif-test-default-pool-27dfc050-9bww Pulling image "mysql:dert12"
Warning Failed 15s (x4 over 104s) kubelet, gke-certif-test-default-pool-27dfc050-9bww Failed to pull image "mysql:dert12": rpc error: code = Unknown desc = Error response from daemon: manifest for mysql:dert12 not found: manifest unknown: manifest unknown
Warning Failed 15s (x4 over 104s) kubelet, gke-certif-test-default-pool-27dfc050-9bww Error: ErrImagePullTroubleshooting des Pods
L'état de votre pod est en "Pending"
Faites une description sur le pod et regardez la section "Events". Notez que le scheduler n'a pas de nœud dans lequel placer votre pod en raison d'une ressource insuffisante. Vous pouvez augmenter votre CPU ou votre mémoire (selon le message d'avertissement), cela peut se produire en ajoutant de nouveaux nœuds ou en diminuant le nombre de réplicas du déploiement
$ kubectl describe pods web-deploy-654fb8bb79-24nvd
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 90s (x2 over 95s) default-scheduler 0/2 nodes are available: 2 Insufficient cpu.
Normal NotTriggerScaleUp 65s cluster-autoscaler pod didn't trigger scale-up (it wouldn't fit if a new node is added): 1 max node group size reached
Warning FailedScheduling 20s default-scheduler 0/6 nodes are available: 6 Insufficient cpu.Troubleshooting des Pods
L'état de votre pod est en "waiting"
Si un pod est bloqué dans l'état "waiting", il a été planifié sur un nœud de travail, mais il ne peut pas s'exécuter sur cette machine. Encore une fois, les informations de kubectl describe... devraient être informatives. La cause la plus courante des pods en "waiting" est l'échec de l'extraction de l'image. Il y a trois choses à vérifier :
- Assurez-vous que le nom de l'image est correct. - Avez-vous poussé l'image vers le repository ? - Exécutez un docker pull <image> manuel sur votre machine pour voir si l'image peut être extraite.
Troubleshooting des Pods
- Commandes utiles
$ kubectl get pods
$ kubectl describe pods pod-name
$ kubectl logs pod-name --container=pods-containers-name
$ kubectl logs --previous pod-name --container=pods-containers-name
$ kubectl exec -it pod-name -- bashTroubleshooting des Services
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.16.0.1 <none> 443/TCP 46d
web-service LoadBalancer 10.16.7.129 34.68.167.93 80:30250/TCP 9m54sIl existe plusieurs problèmes courants qui peuvent empêcher les services de fonctionner correctement. Tout d'abord, vérifiez qu'il existe des endpoints pour le service. Pour chaque objet Service, l'API server met à disposition une ressource endpoint.
$ kubectl get endpoints web-service
NAME ENDPOINTS AGE
web-service 10.12.0.27:80,10.12.0.28:80,10.12.0.4:80 11mAssurez-vous que les endpoints correspondent au nombre de conteneurs que vous pensez être membres de votre service. Dans ce scénario, le service Web sert un déploiement Web avec 3 réplicas de pods.
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
web-deployment 3/3 3 3 4h43m Troubleshooting des Services
au cas où les endpoints du service sont manquants, vérifiez le sélecteur du service ...
spec:
- selector:
run: web-deploymentCe sélecteur doit correspondre aux labels des pods sinon le service ne pourra pas exposer les pods $ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
web-deployment-654fb8bb79-6n9q2 1/1 Running 0 4h53m run=web-deployment
web-deployment-654fb8bb79-ljnhw 1/1 Running 0 15m run=web-deployment
web-deployment-654fb8bb79-vpcwb 1/1 Running 0 15m run=web-deploymentSi la liste des pods correspond aux attentes, mais que les endpoints sont toujours vides, il est possible que les bons ports ne soient pas exposés. Si le service a un containerPort spécifié, mais que les pods sélectionnés n'ont pas ce port répertorié, ils ne seront pas ajoutés à la liste des endpoints.
Vérifiez que le containerPort du pod correspond au targetPort du serviceTroubleshooting du Control Plane
- Vérifier l'état des composants du Controlplane
$ kubectl get componentstatus
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok - Vérifier l'état des nœuds
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
worker-1 Ready worker 8d v1.21.0
worker-2 Ready worker 8d v1.21.0
master-1 Ready master 8d v1.21.0Troubleshooting du Control Plane
- Vérifier les pods du Controlplane
$ kubectl get pods -n kube-systems
NAME READY STATUS RESTARTS AGE
coredns-78fcdf6894-5dntv 1/1 Running 0 1h
coredns-78fcdf6894-knpzl 1/1 Running 0 1h
etcd-master 1/1 Running 0 1h
kube-apiserver-master 1/1 Running 0 1h
kube-controller-manager-master 1/1 Running 0 1h
kube-proxy-fvbpj 1/1 Running 0 1h
kube-proxy-v5r2t 1/1 Running 0 1h
kube-scheduler-master 1/1 Running 0 1h
weave-net-7kd52 2/2 Running 1 1h
weave-net-jtl5m 2/2 Running 1 1hTroubleshooting du Control Plane
- Vérifier les services du Controlplane
$ service kube-apiserver status
● kube-apiserver.service - Kubernetes API Server
Loaded: loaded (/etc/systemd/system/kube-apiserver.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2019-03-20 07:57:25 UTC; 1 weeks 1 days ago
Docs: https://github.com/kubernetes/kubernetes
Main PID: 15767 (kube-apiserver)
Tasks: 13 (limit: 2362)Répétez le même process pour les autres services tels que: kube-controller-manager, kube-scheduler, kubelet, kube-proxy Control Plane troubleshooting
- Vérifier les logs de service
$ kubectl logs kube-apiserver-master -n kube-system
I0401 13:45:38.190735 1 server.go:703] external host was not specified, using 172.17.0.117
I0401 13:45:38.194290 1 server.go:145] Version: v1.11.3
I0401 13:45:38.819705 1 plugins.go:158] Loaded 8 mutating admission controller(s) successfully in the following order:
NamespaceLifecycle,LimitRanger,ServiceAccount,NodeRestriction,Priority,DefaultTolerationSeconds,DefaultStorageClass,MutatingAdmissionWebhook.
I0401 13:45:38.819741 1 plugins.go:161] Loaded 6 validating admission controller(s) successfully in the following order:
LimitRanger,ServiceAccount,Priority,PersistentVolumeClaimResize,ValidatingAdmissionWebhook,ResourceQuota.
I0401 13:45:38.821372 1 plugins.go:158] Loaded 8 mutating admission controller(s) successfully in the following order:
NamespaceLifecycle,LimitRanger,ServiceAccount,NodeRestriction,Priority,DefaultTolerationSeconds,DefaultStorageClass,MutatingAdmissionWebhook.
I0401 13:45:38.821410 1 plugins.go:161] Loaded 6 validating admission controller(s) successfully in the following order:
LimitRanger,ServiceAccount,Priority,PersistentVolumeClaimResize,ValidatingAdmissionWebhook,ResourceQuota.
I0401 13:45:38.985453 1 master.go:234] Using reconciler: lease
W0401 13:45:40.900380 1 genericapiserver.go:319] Skipping API batch/v2alpha1 because it has no resources.
W0401 13:45:41.370677 1 genericapiserver.go:319] Skipping API rbac.authorization.k8s.io/v1alpha1 because it has no resources.
W0401 13:45:41.381736 1 genericapiserver.go:319] Skipping API scheduling.k8s.io/v1alpha1 because it has no resources.Troubleshooting des noeuds
- Vérifier l'état du nœud
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
worker-1 Ready <none> 8d v1.21.0
worker-2 NotReady <none> 8d v1.21.0 $ kubectl describe node worker-1
...
Conditions:
Type Status LastHeartbeatTime Reason Message
---- ------ ----------------- ------ -------
OutOfDisk False Mon, 01 Apr 2019 14:30:33 +0000 KubeletHasSufficientDisk kubelet has sufficient disk space available
MemoryPressure False Mon, 01 Apr 2019 14:30:33 +0000 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Mon, 01 Apr 2019 14:30:33 +0000 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Mon, 01 Apr 2019 14:30:33 +0000 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Mon, 01 Apr 2019 14:30:33 +0000 KubeletReady kubelet is posting ready status. AppArmor enabledTroubleshooting des noeuds
$ kubectl describe node worker-2
Conditions:
Type Status LastHeartbeatTime Reason Message
---- ------ ----------------- ------ -------
OutOfDisk Unknown Mon, 01 Apr 2019 14:20:20 +0000 NodeStatusUnknown Kubelet stopped posting node status.
MemoryPressure Unknown Mon, 01 Apr 2019 14:20:20 +0000 NodeStatusUnknown Kubelet stopped posting node status.
DiskPressure Unknown Mon, 01 Apr 2019 14:20:20 +0000 NodeStatusUnknown Kubelet stopped posting node status.
PIDPressure False Mon, 01 Apr 2019 14:20:20 +0000 KubeletHasSufficientPID kubelet has sufficient PID available
Ready Unknown Mon, 01 Apr 2019 14:20:20 +0000 NodeStatusUnknown Kubelet stopped posting node status. Troubleshooting des noeuds
- Vérifier les certificats :
$ openssl x509 -in /var/lib/kubelet/worker-1.crt -text
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
ff:e0:23:9d:fc:78:03:35
Signature Algorithm: sha256WithRSAEncryption
Issuer: <CN = KUBERNETES-CA>
Validity
Not Before: Mar 20 08:09:29 2019 GMT
<Not After : Apr 19 08:09:29 2019 GMT>
Subject: CN = system:node:worker-1, O = system:nodes
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
Modulus:
00:b4:28:0c:60:71:41:06:14:46:d9:97:58:2d:fe:
a9:c7:6d:51:cd:1c:98:b9:5e:e6:e4:02:d3:e3:71:
...Se préparer à la certification
CKA exam
La durée de l'examen est de 2h
Avec des exercices pratiques dans un cluster déjà opératinnel
Accès à la documentation officielle de Kubernetes est autorisé
- Quelques liens utiles:
- https://docs.linuxfoundation.org/tc-docs/certification/tips-cka-and-ckad
- https://docs.linuxfoundation.org/tc-docs/certification/lf-candidate-handbook
https://github.com/cncf/curriculum
Conclusion
CKA, CKAD et CKS
- Certified Kubernetes Application Developer (CKAD)
- Certified Kubernetes Administrator (CKA)
Certified Kubernetes Security Specialist (CKS)
Les programmes CKAD, CKA et CKS ont été développés par la Cloud Native Computing Foundation (CNCF), en collaboration avec la Linux Foundation, pour faciliter l'extension de l'écosystème
Kubernetesgrâce à des certifications standardisées.
https://www.cncf.io/certification/ckad/ https://www.cncf.io/certification/cka/ https://www.cncf.io/certification/cks/