openstack-ops
Concernant les supports de cours
Supports de cours
Les cours sont maintenus et donnés par : https://www.alterway.fr/cloud-consulting
- Copyright © 2014 - 2025 Alter Way Cloud Consulting
- Licence : Creative Commons BY-SA 4.0
- Sources : https://github.com/alterway/formations/

Introduction
Objectifs de la formation : OpenStack
- Connaitre le fonctionnement du projet OpenStack et ses possibilités
- Comprendre le fonctionnement de chacun des composants d’OpenStack
- Pouvoir faire les bons choix de configuration
- Savoir déployer manuellement un cloud OpenStack pour fournir du IaaS
- Connaitre les bonnes pratiques de déploiement d’OpenStack
- Être capable de déterminer l’origine d’une erreur dans OpenStack
- Savoir réagir face à un bug
Pré-requis de la formation
- Compétences d’administration système Linux tel qu’Ubuntu
- Gestion des paquets
- Manipulation de fichiers de configuration et de services
- LVM (Logical Volume Management) et systèmes de fichiers
- Notions :
- Virtualisation : KVM (Kernel-Based Virtual Machine), libvirt
- Réseau : iptables, namespaces
- SQL
- Optionnel :
- À l’aise dans un environnement Python
OpenStack : le projet
Tour d'horizon
Vue haut niveau
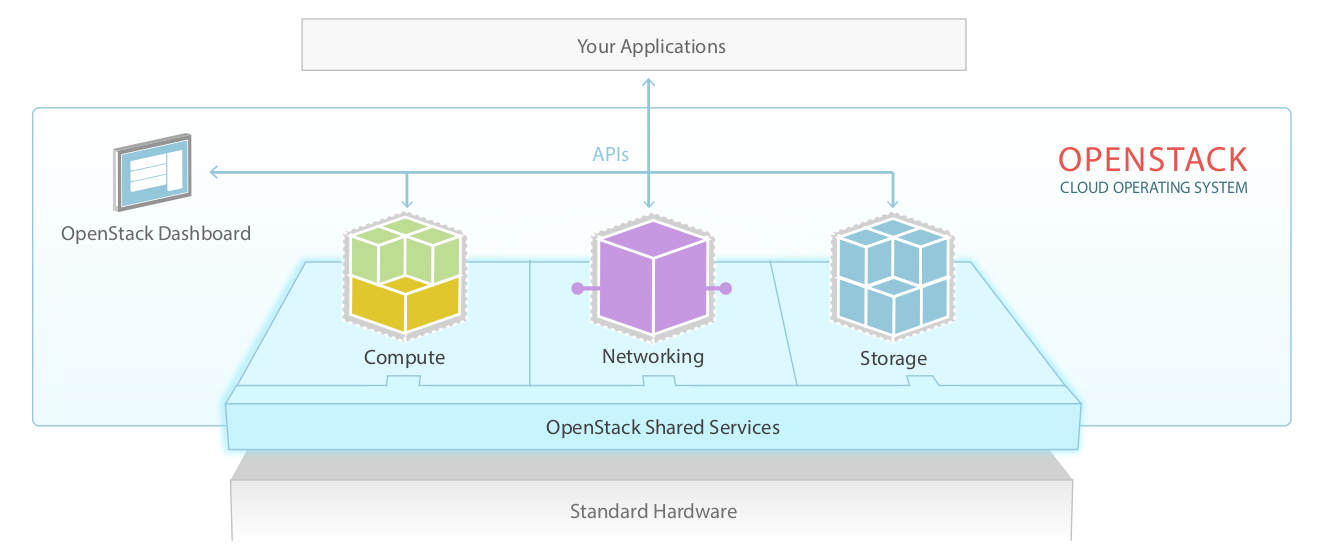
Historique
- Démarrage en 2010
- Objectif : le Cloud Operating System libre
- Fusion de deux projets de Rackspace (Storage) et de la NASA (Compute)
- Logiciel libre distribué sous licence Apache 2.0
- Naissance de la Fondation en 2012
Mission statement
To produce a ubiquitous Open Source Cloud Computing platform that is easy to use, simple to implement, interoperable between deployments, works well at all scales, and meets the needs of users and operators of both public and private clouds.
Les releases
- Austin (2010.1)
- Bexar (2011.1), Cactus (2011.2), Diablo (2011.3)
- Essex (2012.1), Folsom (2012.2)
- Grizzly (2013.1), Havana (2013.2)
- Icehouse (2014.1), Juno (2014.2)
- Kilo (2015.1), Liberty (2015.2)
- Mitaka (2016.1), Newton (2016.2)
- Ocata (2017.1), Pike (2017.2)
- Queens (2018.1), Rocky (2018.2)
- Stein (2019.1), Train (2019.2)
- Premier semestre 2020 : Ussuri
Quelques soutiens/contributeurs ...
- Editeurs : Red Hat, Suse, Canonical, Vmware, ...
- Constructeurs : IBM, HP, Dell, ...
- Constructeurs/réseau : Juniper, Cisco, ...
- Constructeurs/stockage : NetApp, Hitachi, ...
- En vrac : NASA, Rackspace, Yahoo, OVH, Citrix, SAP, ...
- Google ! (depuis juillet 2015)
... et utilisateurs
- Tous les contributeurs précédemment cités
- En France : Cloudwatt et Numergy
- Wikimedia
- CERN
- Paypal
- Comcast
- BMW
- Etc. Sans compter les implémentations confidentielles
Les différents sous-projets
https://www.openstack.org/software/project-navigator/
- OpenStack Compute - Nova
- OpenStack (Object) Storage - Swift
- OpenStack Block Storage - Cinder
- OpenStack Networking - Neutron
- OpenStack Image Service - Glance
- OpenStack Identity Service - Keystone
- OpenStack Dashboard - Horizon
- OpenStack Telemetry - Ceilometer
- OpenStack Orchestration - Heat
Les différents sous-projets (2)
- Mais aussi :
- Bare metal (Ironic)
- Queue service (Zaqar)
- Database Service (Trove)
- Data processing (Sahara)
- DNS service (Designate)
- Shared File Systems (Manila)
- Key management (Barbican)
- Container (Magnum)
- Autres
- Les clients CLI et bibliothèques
- Les outils de déploiement d'OpenStack
- Les bibliothèques utilisées par OpenStack
- Les outils utilisés pour développer OpenStack
APIs
- Chaque projet supporte son API OpenStack
- Certains projets supportent l'API AWS équivalente (Nova/EC2, Swift/S3)
Les 4 Opens
- Open Source
- Open Design
- Open Development
- Open Community
La Fondation OpenStack
- Entité de gouvernance principale et représentation juridique du projet
- Les membres du board sont issus des entreprises sponsors et élus par les membres individuels
- Tout le monde peut devenir membre individuel (gratuitement)
- Ressources humaines : marketing, événementiel, release management, quelques développeurs (principalement sur l’infrastructure)
- 600 organisations à travers le monde
- 80000 membres individuels dans 170 pays
La Fondation OpenStack

Open Infrastructure
- Récemment, la Fondation OpenStack s'élargit à l'Open Infrastructure
- Au-delà d'OpenStack, nouveaux projets chapeautés :
- Kata Containers
- Zuul
- Airship
- StarlingX
Ressources
- Annonces (nouvelles versions, avis de sécurité) : openstack-announce@lists.openstack.org
- Portail documentation : https://docs.openstack.org/
- API/SDK : https://developer.openstack.org/
- Gouvernance du projet : https://governance.openstack.org/
- Versions : https://releases.openstack.org/
- Support :
- https://ask.openstack.org/
- openstack-discuss@lists.openstack.org
- #openstack@Freenode
Ressources
- Actualités :
- Blog officiel : https://www.openstack.org/blog/
- Planet : http://planet.openstack.org/
- Superuser : http://superuser.openstack.org/
- Ressources commerciales : https://www.openstack.org/marketplace/ entre autres
- Job board : https://www.openstack.org/community/jobs/
User Survey
- Sondage réalisé régulièrement par la Fondation (tous les 6 mois)
- Auprès des déployeurs et utilisateurs
- Données exploitables : https://www.openstack.org/analytics
Certification Certified OpenStack Administrator (COA)
- La seule certification :
- Validée par la Fondation OpenStack
- Non liée à une entreprise particulière
- Contenu :
- Essentiellement orientée utilisateur de cloud OpenStack
- https://www.openstack.org/coa/requirements/
- Aspects pratiques :
- Examen pratique, passage à distance, durée : 2,5 heures
- Coût : $300 (deux passages possibles)
- Ressources
- https://www.openstack.org/coa/
- Tips : https://www.openstack.org/coa/tips/
- Handbook : http://www.openstack.org/coa/handbook
- Exercices (non-officiels) : https://github.com/AJNOURI/COA
Ressources - Communauté francophone et association

- https://openstack.fr/ - https://asso.openstack.fr/
- Meetups : Paris, Lyon, Toulouse, Montréal, etc.
- OpenStack Days France (Paris) : https://openstackdayfrance.fr/
- Présence à des événements tels que Paris Open Source Summit
- Canaux de communication :
- openstack-fr@lists.openstack.org
- #openstack-fr@Freenode
Fonctionnement interne
Architecture
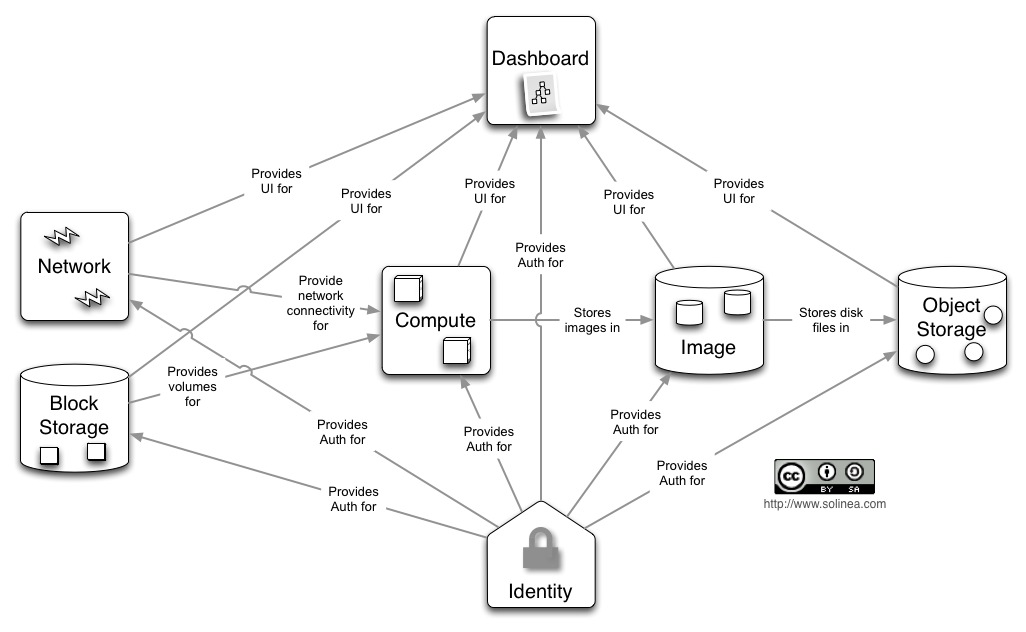
Implémentation
- Tout est développé en Python (Django pour la partie web)
- Chaque projet est découpé en plusieurs services (exemple : API, scheduler, etc.)
- Réutilisation de composants existants et de bibliothèques existantes
- Utilisation des bibliothèques
oslo.*(développées par et pour OpenStack) : logs, config, etc. - Utilisation de
rootwrappour appeler des programmes sous-jacents en root
Implémentation - dépendances
- Base de données : relationnelle SQL (MySQL/MariaDB)
- Communication entre les services : AMQP (RabbitMQ)
- Mise en cache : Memcached
- Stockage distribué de configuration (à venir) : etcd
Modèle de développement
Statistiques (2017)
- 2344 développeurs
- 65823 changements (commits)
https://www.openstack.org/assets/reports/OpenStack-AnnualReport2017.pdf
Développement du projet : en détails
- Ouvert à tous (individuels et entreprises)
- Cycle de développement de 6 mois
- Chaque cycle débute par un Project Team Gathering (PTG)
- Pendant chaque cycle a lieu un OpenStack Summit
Les outils et la communication
- Code : Git (GitHub est utilisé comme miroir)
- Revue de code (peer review) : Gerrit
- Intégration continue (CI: Continous Integration) : Zuul
- Blueprints/spécifications et bugs :
- Launchpad
- StoryBoard
- Communication : IRC et mailing-lists
- Traduction : Zanata
Développement du projet : en détails
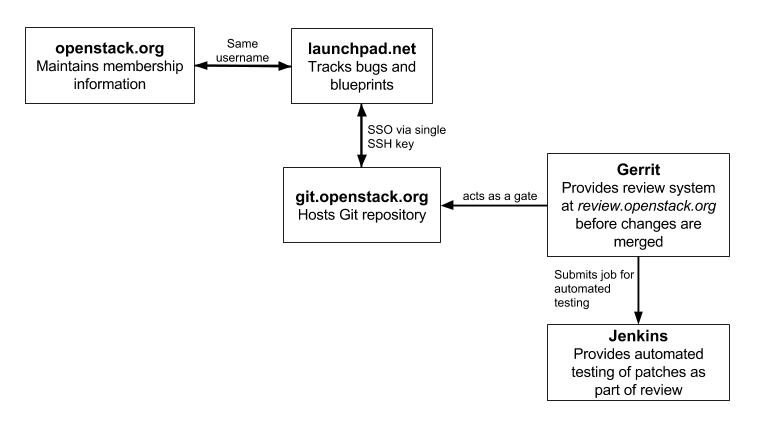
Cycle de développement : 6 mois
- Le planning est publié, exemple : https://releases.openstack.org/stein/schedule.html
- Milestone releases
- Freezes : Feature, Requirements, String
- RC releases
- Stable releases
- Cas particulier de certains composants : https://releases.openstack.org/reference/release_models.html
Projets
- Équipes projet (Project Teams) : https://governance.openstack.org/reference/projects/index.html
- Chaque livrable est versionné indépendamment - Semantic versioning
- https://releases.openstack.org/
Qui contribue ?
- Active Technical Contributor (ATC)
- Personne ayant au moins une contribution récente dans un projet OpenStack reconnu
- Droit de vote (TC et PTL)
- Core reviewer : ATC ayant les droits pour valider les patchs dans un projet
- Project Team Lead (PTL) : élu par les ATCs de chaque projet
- Stackalytics fournit des statistiques sur les contributions http://stackalytics.com/
Où trouver des informations sur le développement d’OpenStack
- Comment contribuer
- https://docs.openstack.org/project-team-guide/
- https://docs.openstack.org/infra/manual/
- Informations diverses, sur le wiki
- https://wiki.openstack.org/
- Les blueprints et bugs sur Launchpad/StoryBoard
- https://launchpad.net/openstack/
- https://storyboard.openstack.org/
- https://specs.openstack.org/
Où trouver des informations sur le développement d’OpenStack
- Les patchs proposés et leurs reviews sont sur Gerrit
- https://review.openstack.org/
- L’état de la CI (entre autres)
- http://status.openstack.org/
- Le code (Git) et les tarballs sont disponibles
- https://git.openstack.org/
- https://tarballs.openstack.org/
- IRC
- Réseau Freenode
- Logs discussions et infos réunions : http://eavesdrop.openstack.org/
- Mailing-lists
- http://lists.openstack.org/
Upstream Training
- Deux jours de formation
- Apprendre à devenir contributeur à OpenStack
- Les outils
- Les processes
- Travailler et collaborer de manière ouverte
OpenStack Infra
- Équipe projet en charge de l’infrastructure de développement d’OpenStack
- Travaille comme les équipes de dev d’OpenStack et utilise les mêmes outils
- Résultat : Infrastructure as code open source https://opensourceinfra.org/
- Utilise du cloud (hybride)
- Développe certains outils
- Zuul
- yaml2ical
OpenStack Summit
- Tous les 6 mois en milieu de cycle de développpement
- Aux USA jusqu’en 2013, aujourd'hui alternance Amérique de Nord et Asie/Europe
- Quelques dizaines au début à des milliers de participants aujourd’hui
- En parallèle : conférence (utilisateurs, décideurs) et Forum (développeurs/opérateurs, remplace une partie du précédent Design Summit)
- Détermine le nom de la prochaine release : lieu/ville à proximité du Summit
Exemple du Summit d’avril 2013 à Portland

Exemple du Summit d’octobre 2015 à Tokyo

Exemple du Summit d’octobre 2015 à Tokyo

Exemple du Summit d’octobre 2015 à Tokyo

Exemple du Summit d’octobre 2015 à Tokyo

Project Team Gathering (PTG)
- Depuis 2017
- Au début de chaque cycle
- Remplace une partie du précédent Design Summit
- Dédié aux développeurs
Traduction
- Équipe officielle i18n
- Seules certaines parties sont traduites, comme Horizon
- La traduction française est aujourd’hui une des plus avancées
- Utilisation d'une plateforme web basée Zanata : https://translate.openstack.org/
DevStack : faire tourner rapidement un OpenStack
Utilité de DevStack
- Déployer rapidement un OpenStack
- Utilisé par les développeurs pour tester leurs changements
- Utilisé pour faire des démonstrations
- Utilisé pour tester les APIs sans se préoccuper du déploiement
- Ne doit PAS être utilisé pour de la production
Fonctionnement de DevStack
- Support d'Ubuntu 16.04/17.04, Fedora 24/25, CentOS/RHEL 7, Debian, OpenSUSE
- Un script shell qui fait tout le travail : stack.sh
- Un fichier de configuration : local.conf
- Installe toutes les dépendances nécessaires (paquets)
- Clone les dépôts git (branche master par défaut)
- Lance tous les composants
Configuration : local.conf
Exemple
[[local|localrc]]
ADMIN_PASSWORD=secrete
DATABASE_PASSWORD=$ADMIN_PASSWORD
RABBIT_PASSWORD=$ADMIN_PASSWORD
SERVICE_PASSWORD=$ADMIN_PASSWORD
SERVICE_TOKEN=a682f596-76f3-11e3-b3b2-e716f9080d50
#FIXED_RANGE=172.31.1.0/24
#FLOATING_RANGE=192.168.20.0/25
#HOST_IP=10.3.4.5Conseils d’utilisation
- DevStack installe beaucoup de choses sur la machine
- Il est recommandé de travailler dans une VM
- Pour tester tous les composants OpenStack dans de bonnes conditions, plusieurs Go de RAM sont nécessaires
- L’utilisation de Vagrant est conseillée
Déployer OpenStack
Ce qu’on va voir
- Installer OpenStack à la main https://docs.openstack.org/install-guide/
- Donc comprendre son fonctionnement
- Passer en revue chaque composant plus en détails
- Tour d’horizon des solutions de déploiement
Architecture détaillée
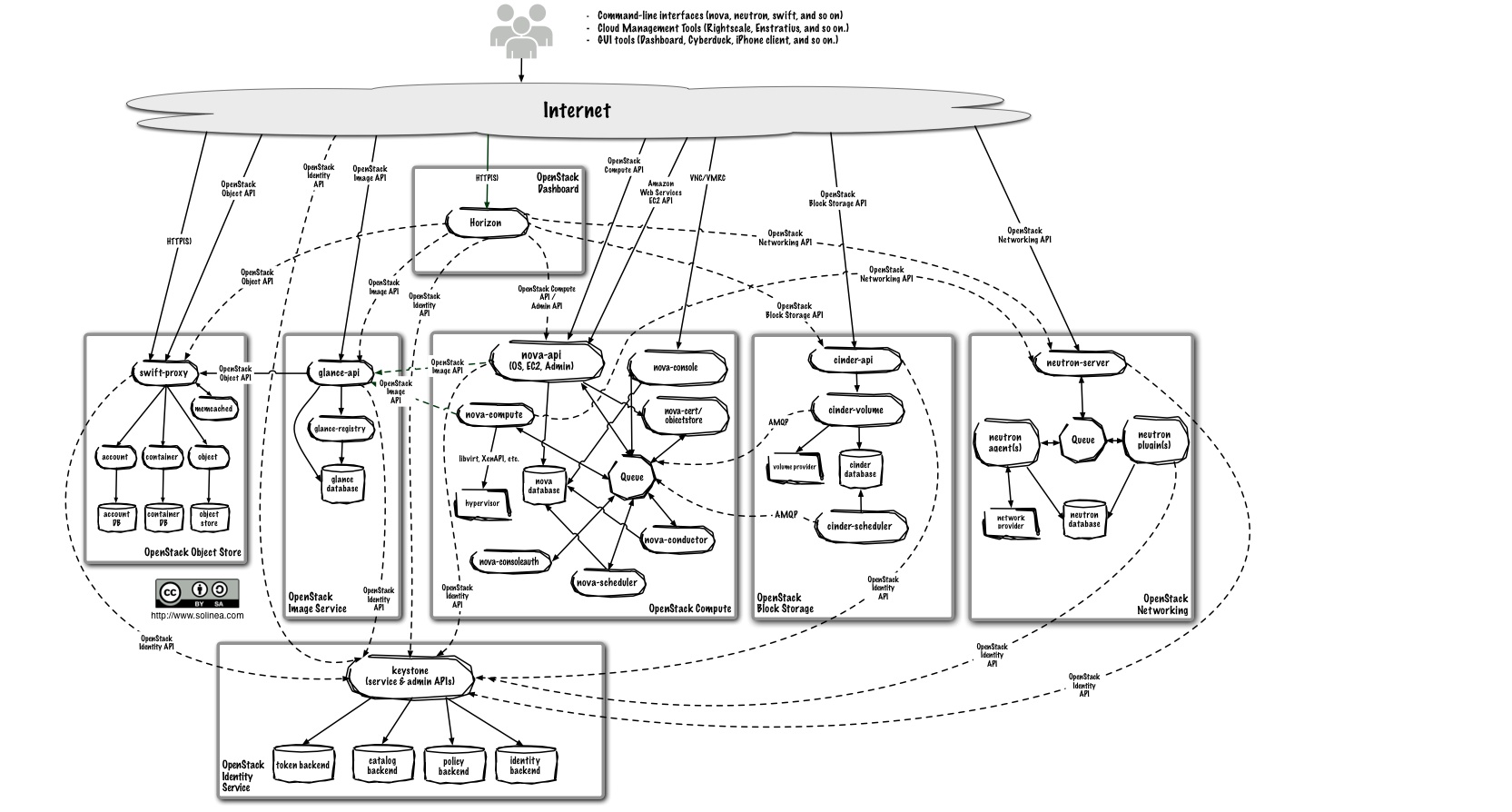
Architecture services
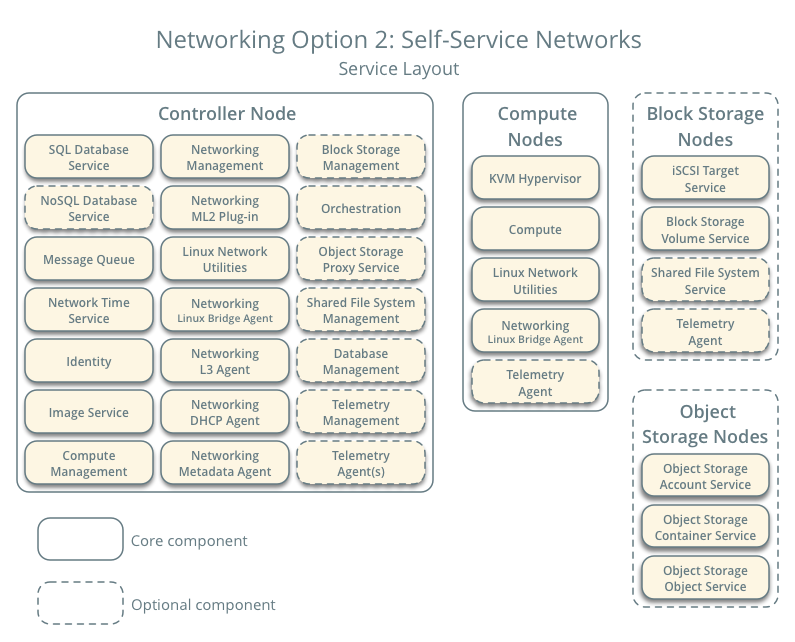
Quelques éléments de configuration généraux
- Tous les composants doivent être configurés pour communiquer avec Keystone
- La plupart doivent être configurés pour communiquer avec MySQL/MariaDB et RabbitMQ
- Les composants découpés en plusieurs services ont parfois un fichier de configuration par service
- Le fichier de configuration
policy.jsonprécise les droits nécessaires pour chaque appel API
Système d’exploitation
- OS Linux avec Python
- Ubuntu
- Red Hat
- SUSE
- Debian, Fedora, CentOS, etc.
Python

- OpenStack est compatible Python 2.7
- Comptabilité Python 3 presque complète
- Afin de ne pas réinventer la roue, beaucoup de dépendances sont nécessaires
Base de données MySQL/MariaDB
- Permet de stocker la majorité des données gérées par OpenStack
- Chaque composant a sa propre base
- OpenStack utilise l’ORM Python SQLAlchemy
- Support théorique équivalent à celui de SQLAlchemy (et support des migrations)
- MySQL/MariaDB est l’implémentation la plus largement testée et utilisée
- SQLite est principalement utilisé dans le cadre de tests et démo
- Certains déploiements fonctionnent avec PostgreSQL
![]()
![]()
Passage de messages
- AMQP : Advanced Message Queuing Protocol
- Messages, file d’attente, routage
- Les processus OpenStack communiquent via AMQP
- Plusieurs implémentations possibles : Qpid, 0MQ, etc.
- RabbitMQ par défaut
RabbitMQ
- RabbitMQ est implémenté en Erlang
- Une machine virtuelle Erlang est donc nécessaire
“Hello world” RabbitMQ
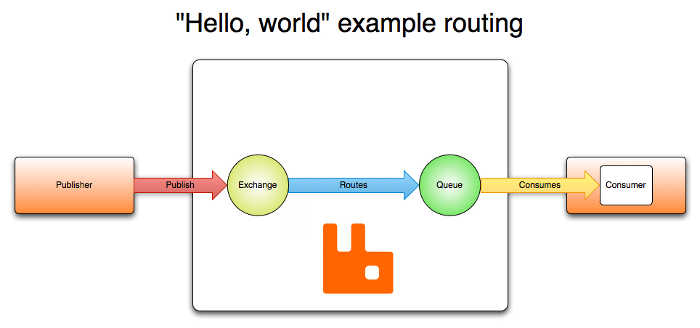
Cache Memcached
- Plusieurs services tirent parti d'un mécanisme de cache
- Memcached est l'implémentation par défaut
Keystone : Authentification, autorisation et catalogue de services
Installation et configuration
- Paquet APT : keystone
- Intégration serveur web WSGI (Apache par défaut)
- Fichier de configuration:
/etc/keystone/keystone.conf - Backends utilisateurs/groupes : SQL, LDAP (ou Active Directory)
- Backends projets/rôles/services/endpoints : SQL
- Backends tokens : SQL, Memcache, aucun (suivant le type de tokens)
Drivers pour tokens
- Uuid
- PKI
- Fernet
Bootstrap
- Création des services et endpoints (à commencer par Keystone)
- Création d'utilisateurs, groupes, domaines
- Fonctionnalité de bootstrap
Nova : Compute
Nova api
- Double rôle
- API de manipulation des instances par l’utilisateur
- API à destination des instances : API de metadata
- L’API de metadata doit être accessible à l’adresse
http://169.254.169.254/ - L’API de metadata fournit des informations de configuration personnalisées à chacune des instances
Nova compute
- Pilote les instances (machines virtuelles ou physiques)
- Tire partie de libvirt ou d’autres APIs comme XenAPI
- Drivers : libvirt (KVM, LXC, etc.), XenAPI, VMWare vSphere, Ironic
- Permet de récupérer les logs de la console et une console VNC
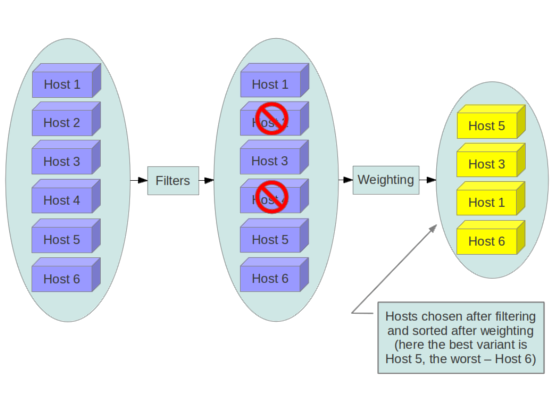
Nova scheduler
- Service qui distribue les demandes d’instances sur les nœuds compute
- Filter, Chance, Multi Scheduler
- Filtres, par défaut : AvailabilityZoneFilter,RamFilter,ComputeFilter
- Tri par poids, par défaut : RamWeigher
Le scheduler Nova en action
Nova conductor
- Service facultatif qui améliore la sécurité
- Fait office de proxy entre les nœuds compute et la BDD
- Les nœuds compute, vulnérables, n’ont donc plus d’accès à la BDD
Glance : Registre d’images
Backends
- Swift ou S3
- Ceph
- HTTP
- Répertoire local
Installation
- Paquet APT : glance-api
Neutron : Réseau en tant que service
Principes
- Software Defined Networking (SDN)
- Auparavant Quantum et nova-network
- neutron-server : fournit l’API
- Agent DHCP : fournit le service de DHCP pour les instances
- Agent L3 : gère la couche 3 du réseau, le routage
- Plugin : LinuxBridge par défaut, d’autres implémentations libres/propriétaires, logicielles/matérielles existent
Fonctionnalités supplémentaires
Outre les fonctions réseau de base niveaux 2 et 3, Neutron peut fournir d’autres services :
- Load Balancing (HAProxy, ...)
- Firewall (vArmour, ...) : diffère des groupes de sécurité
- VPN (Openswan, ...) : permet d’accéder à un réseau privé sans IP flottantes
Ces fonctionnalités se basent également sur des plugins
Plugins ML2
- Modular Layer 2
- LinuxBridge
- OpenVSwitch
- OpenDaylight
- Contrail, OpenContrail
- Nuage Networks
- VMWare NSX
- cf. OpenFlow
Implémentation
- Chaque réseau est un bridge
- Les bridges sont étendus entre les machines via des tunnels (type VXLAN) si nécessaires
- Neutron tire partie des namespaces réseaux du noyau Linux pour permettre l’IP overlapping
- Le proxy de metadata est un composant qui permet aux instances isolées dans leur réseau de joindre l’API de metadata fournie par Nova
Schéma
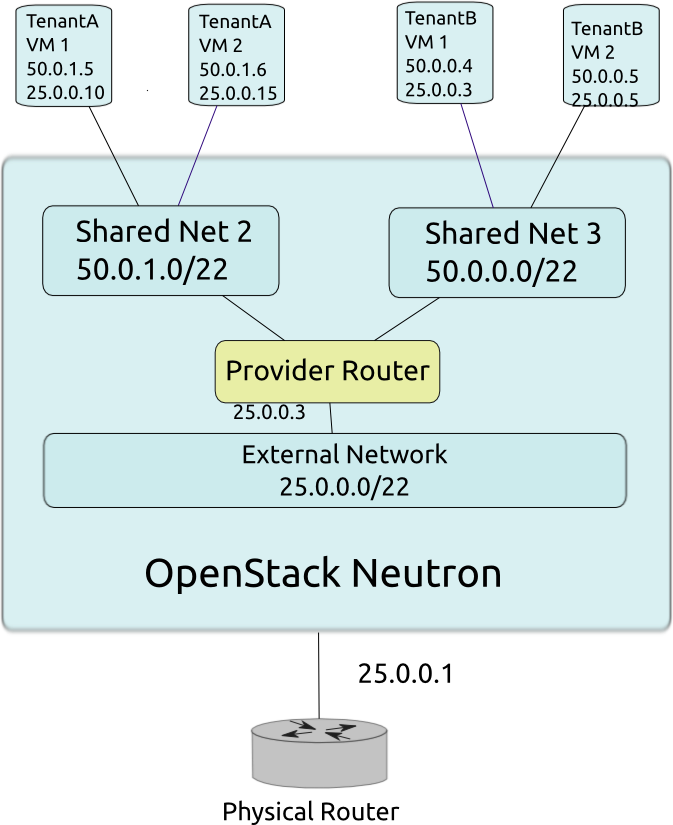
Schéma
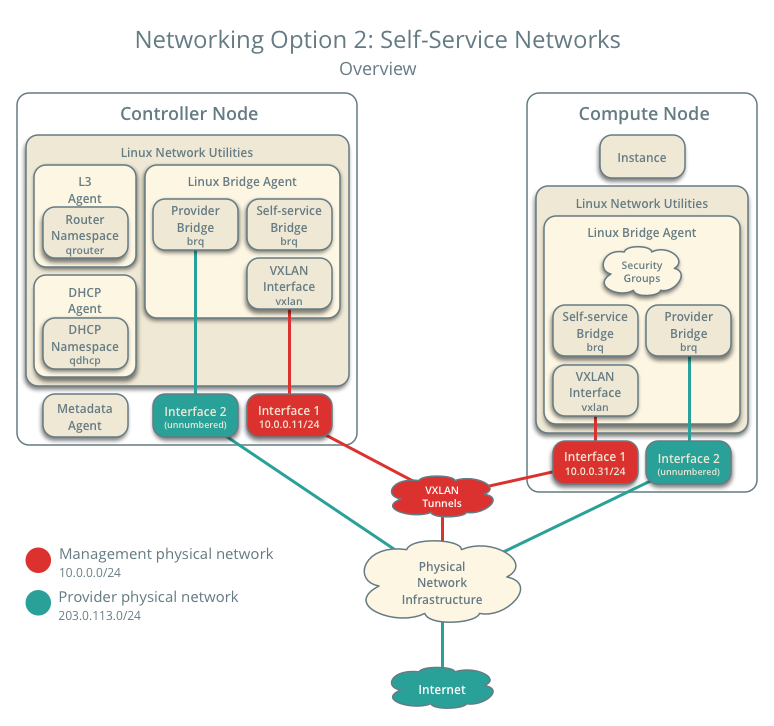
Cinder : Stockage block
Principes
- Auparavant nova-volume
- Fournit des volumes
- Attachement des volumes via iSCSI par défaut
Installation
- Paquet cinder-api : fournit l’API
- Paquet cinder-volume : création et gestion des volumes
- Paquet cinder-scheduler : distribue les demandes de création de volume
- Paquet cinder-backup (optionnel) : backup vers un object store
Backends
- Utilisation de plusieurs backends en parallèle possible
- LVM (par défaut)
- GlusterFS
- Ceph
- Systèmes de stockage propriétaires type NetApp
- DRBD
Horizon : Dashboard web
Principes
- Horizon est un module Django
- OpenStack Dashboard est l’implémentation officielle de ce module
Configuration
local_settings.py- Les services apparaissent dans Horizon s’ils sont répertoriés dans le catalogue de services de Keystone
Swift : Stockage objet
Principes
- SDS : Software Defined Storage
- Utilisation de commodity hardware
- Théorème CAP : on en choisit deux
- Architecture totalement acentrée
- Pas de base de données centrale
Implémentation
- Proxy : serveur API par lequel passent toutes les requêtes
- Object server : serveur de stockage
- Container server : maintient des listes d’objects dans des containers
- Account server : maintient des listes de containers dans des accounts
- Chaque objet est répliqué n fois (3 par défaut)
Le ring
- Problème : comment décider quelle donnée va sur quel object server
- Le ring est découpé en partitions
- On situe chaque donnée dans le ring afin de déterminer sa partition
- Une partition est associée à plusieurs serveurs
Schéma
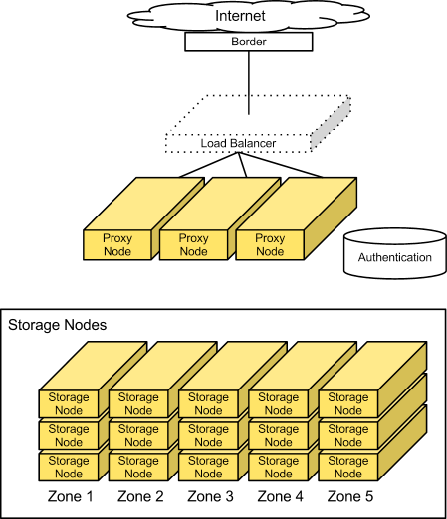
Ceilometer : Collecte de métriques
Surveiller l’utilisation de son infrastructure avec Ceilometer
- Indexer et stocker différentes métriques concernant l’utilisation des différents services du cloud
- Fournir des APIs permettant de récupérer ces données
- Base pour construire des outils de facturation (exemple : CloudKitty)
Ceilometer
- Récupère les données et les stocke
- Historiquement : stockage MongoDB
- Aujourd'hui : stockage Gnocchi
Gnocchi : time-series database
- Pourquoi Gnocchi ? Palier aux problème de scalabilité de Ceilometer + MongoDB
- Initié par des développeurs de Ceilometer et intégré à l’équipe projet Ceilometer
- Fournit une API pour lire et écrire les données
- Se base sur une BDD relationnelle et un système de stockage objet
Heat : Orchestration des ressources
Architecture
- heat-api
- heat-engine
Quelques autres composants intéressants
Trove : Database as a Service
- trove-api : API
- trove-taskmanager : gère les instances BDD
- trove-guestagent : agent interne à l’instance
Designate : DNS as a Service
- Gère différents backends : BIND, PowerDNS, etc.
Barbican : Key management as a Service
- Backends possibles :
- Fichiers chiffrés
- PKCS#11
- KMIP
- Dogtag
Magnum : Container Infrastructure as a Service
- Backends: Swarm, Kubernetes
OpenStack en production et opérations
Bonnes pratiques pour un déploiement en production
Quels composants dois-je installer ?
- Keystone est indispensable
- L’utilisation de Nova va de paire avec Glance et Neutron
- Cinder et Swift s'apprécient en fonction des besoins de stockage
- Swift peut être utilisé indépendemment des autres composants
- Heat coûte peu
- Les services plus haut niveau s'évaluent au cas par cas
Penser dès le début aux choix structurants
- Distribution et méthode de déploiement
- Politique de mise à jour
- Drivers/backends : hyperviseur, stockage block, etc.
- Réseau : quelle architecture et quels drivers
Les différentes méthodes d’installation
- DevStack est à oublier pour la production
- Le déploiement à la main comme vu précédemment n’est pas recommandé car peu maintenable
- Distributions OpenStack packagées et prêtes à l’emploi
- Distributions classiques et gestion de configuration
- Déploiement continu
Mises à jour entre versions majeures
- OpenStack supporte les mises à jour N → N+1
- Swift : très bonne gestion en mode rolling upgrade
- Autres composants : tester préalablement avec vos données
- Lire les release notes
- Cf. articles de blog du CERN https://techblog.web.cern.ch/techblog/
Mises à jour dans une version stable
- Fourniture de correctifs de bugs majeurs et de sécurité
- OpenStack intègre ces correctifs sous forme de patchs dans la branche stable
- Publication de point releases intégrant ces correctifs issus de la branche stable
- Durée variable du support des versions stables, dépendant de l’intérêt des intégrateurs
Assigner des rôles aux machines
Beaucoup de documentations font référence à ces rôles :
- Controller node : APIs, BDD, AMQP
- Network node : DHCP, routeur, IPs flottantes
- Compute node : Hyperviseur/pilotage des instances
Ce modèle simplifié n’est pas HA.
Haute disponibilité
Haute disponibilité du IaaS
- MySQL/MariaDB, RabbitMQ : HA classique (Galera, Clustering)
- Les services APIs sont stateless et HTTP : scale out et load balancers
- La plupart des autres services OpenStack sont capables de scale out également
Guide HA : https://docs.openstack.org/ha-guide/
Conférences par Florian Haas, Hastexo : https://www.openstack.org/community/speakers/profile/398/florian-haas
Haute disponibilité de l’agent L3 de Neutron
- Distributed Virtual Router (DVR)
- L3 agent HA (VRRP)
Considérations APIs
- Des URLs uniformes pour toutes les APIs :
- Utiliser un reverse proxy
- Mettre à jour le catalogue de services
- Apache/mod_wsgi pour servir les APIs lorsque cela est possible (Keystone, etc.)
Guide Operations : https://docs.openstack.org/openstack-ops/content/
Découpage réseau
- Management network : réseau d’administration
- Data/instances network : réseau pour la communication inter instances
- External network : réseau externe, dans l’infrastructure réseau existante
- Storage network : réseau pour le stockage Cinder/Swift
- API network : réseau contenant les endpoints API
Considérations liées à la sécurité
- Indispensable : HTTPS sur l’accès des APIs à l’extérieur
- Sécurisation des communications MySQL/MariaDB et RabbitMQ
- Un accès MySQL/MariaDB par base et par service
- Un utilisateur Keystone par service
- Limiter l’accès en lecture des fichiers de configuration (mots de passe, token)
- Veille sur les failles de sécurité : OSSA (OpenStack Security Advisory), OSSN (... Notes)
Guide sécurité : https://docs.openstack.org/security-guide/
Segmenter son cloud
- Host aggregates : machines physiques avec des caractéristiques similaires
- Availability zones : machines dépendantes d’une même source électrique, d’un même switch, d’un même DC, etc.
- Regions : chaque région a son API
- Cells : permet de regrouper plusieurs cloud différents sous une même API
https://docs.openstack.org/openstack-ops/content/scaling.html#segregate_cloud
Host aggregates / agrégats d’hôtes
- Spécifique Nova
- L’administrateur définit des agrégats d’hôtes via l’API
- L’administrateur associe flavors et agrégats via des couples clé/valeur communs
- 1 agrégat ≡ 1 point commun, ex : GPU
- L’utilisateur choisit un agrégat à travers son choix de flavor à la création d’instance
Availability zones / zones de disponibilité
- Spécifique Nova et Cinder
- Groupes d’hôtes
- Découpage en termes de disponibilité : Rack, Datacenter, etc.
- L’utilisateur choisit une zone de disponibilité à la création d’instance
- L’utilisateur peut demander à ce que des instances soient démarrées dans une même zone, ou au contraire dans des zones différentes
Régions
- Générique OpenStack
- Équivalent des régions d’AWS
- Un service peut avoir différents endpoints dans différentes régions
- Chaque région est autonome
- Cas d’usage : cloud de grande ampleur (comme certains clouds publics)
Cells / Cellules
- Spécifique Nova
- Un seul nova-api devant plusieurs cellules
- Chaque cellule a sa propre BDD et file de messages
- Ajoute un niveau de scheduling (choix de la cellule)
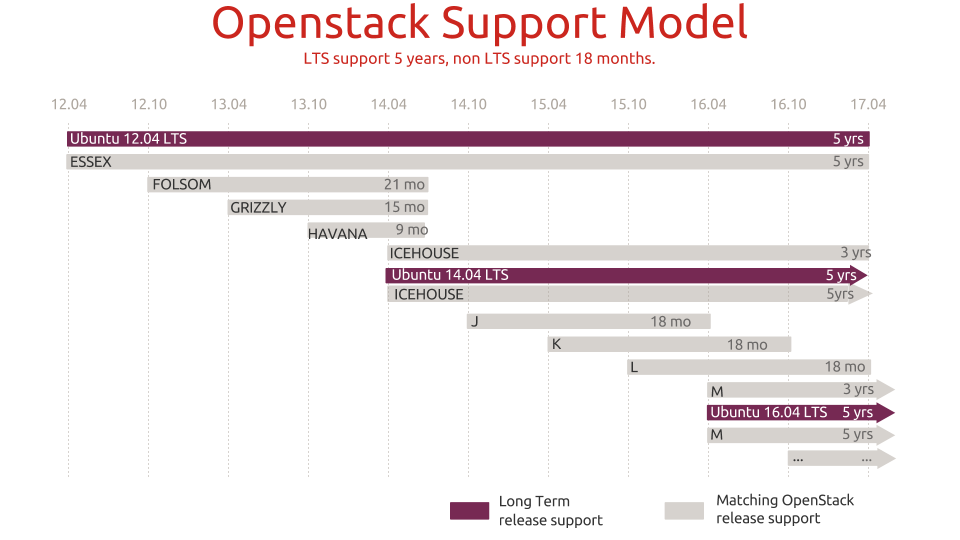
Packaging d’OpenStack - Ubuntu
- Le packaging est fait dans de multiples distributions, RPM, DEB et autres
- Ubuntu est historiquement la plateforme de référence pour le développement d’OpenStack
- Le packaging dans Ubuntu suit de près le développement d’OpenStack, et des tests automatisés sont réalisés
- Canonical fournit la Ubuntu Cloud Archive, qui met à disposition la dernière version d’OpenStack pour la dernière Ubuntu LTS
Ubuntu Cloud Archive (UCA)
Packaging d’OpenStack dans les autres distributions
- OpenStack est intégré dans les dépôts officiels de Debian
- Red Hat propose RHOS/RDO (déploiement basé sur TripleO)
- Comme Ubuntu, le cycle de release de Fedora est synchronisé avec celui d’OpenStack
Les distributions OpenStack
- StackOps : historique
- Mirantis : Fuel
- HP Helion : Ansible custom
- etc.
TripleO
- OpenStack On OpenStack
- Objectif : pouvoir déployer un cloud OpenStack (overcloud) à partir d’un cloud OpenStack (undercloud)
- Autoscaling du cloud lui-même : déploiement de nouveaux nœuds compute lorsque cela est nécessaire
- Fonctionne conjointement avec Ironic pour le déploiement bare-metal
Déploiement bare-metal
- Le déploiement des hôtes physiques OpenStack peut se faire à l’aide d’outils dédiés
- MaaS (Metal as a Service), par Ubuntu/Canonical : se couple avec Juju
- Crowbar / OpenCrowbar (initialement Dell) : utilise Chef
- eDeploy (eNovance) : déploiement par des images
- Ironic via TripleO
Gestion de configuration
- Puppet, Chef, CFEngine, Saltstack, Ansible, etc.
- Ces outils peuvent aider à déployer le cloud OpenStack
- ... mais aussi à gérer les instances (section suivante)
Modules Puppet, Playbooks Ansible
- Puppet OpenStack et OpenStack Ansible : modules Puppet et playbooks Ansible
- Développés au sein du projet OpenStack
- https://wiki.openstack.org/wiki/Puppet
- https://docs.openstack.org/developer/openstack-ansible/install-guide/
Déploiement continu
- OpenStack maintient un master (trunk) toujours stable
- Possibilité de déployer au jour le jour le
master(CD : Continous Delivery) - Nécessite la mise en place d’une infrastructure importante
- Facilite les mises à jour entre versions majeures
Test et validation : Tempest
- Suite de tests d’un cloud OpenStack
- Effectue des appels à l’API et vérifie le résultat
- Est très utilisé par les développeurs via l’intégration continue
- Le déployeur peut utiliser Tempest pour vérifier la bonne conformité de son cloud
- Cf. aussi Rally
Gérer les problèmes
Les réflexes en cas d’erreur ou de comportement erroné
- Travaille-t-on sur le bon projet ?
- Est-ce que l’API renvoie une erreur ? (le dashboard peut cacher certaines informations)
- Si nécessaire d’aller plus loin :
- Regarder les logs sur le cloud controller (/var/log/<composant>/*.log)
- Regarder les logs sur le compute node et le network node si le problème est spécifique réseau/instance
- Éventuellement modifier la verbosité des logs dans la configuration
Est-ce un bug ?
- Si le client CLI crash, c’est un bug
- Si le dashboard web ou une API renvoie une erreur 500, c’est peut-être un bug
- Si les logs montrent une stacktrace Python, c’est un bug
- Sinon, à vous d’en juger
Opérations
Gestion des logs
- Centraliser les logs
- Logs d'API
- Logs autres composants OpenStack
- Logs BDD, AMQP, etc.
Backup
- Bases de données
- Mécanisme de déploiement, plutôt que les fichiers de configuration
Monitoring
- Réponse des APIs
- Vérification des services OpenStack et dépendances
Utilisation des quotas
- Limiter le nombre de ressources allouables
- Par utilisateur ou par projet
- Support dans Nova
- Support dans Cinder
- Support dans Neutron
Conclusion
Pour conclure
- Le cloud révolutionne l’IT
- OpenStack est le projet libre phare sur la partie IaaS
- Déployer OpenStack n’est pas une mince affaire
- L’utilisation d’un cloud IaaS implique des changements de pratique
- Les métiers d’architecture logicielle et infra évoluent